Страница 12 из 19
Yandex TTS
Добавлено: 02 ноя 2020 15:07
tonio_k
tonio_k писал(а): ↑01 ноя 2020 10:39
этот большой словарь предварительно применить к тексту книги в Демагоге с включенной в настройках галочкой "хешировать словари". И вы быстро получите книгу с проставленными ударениями.
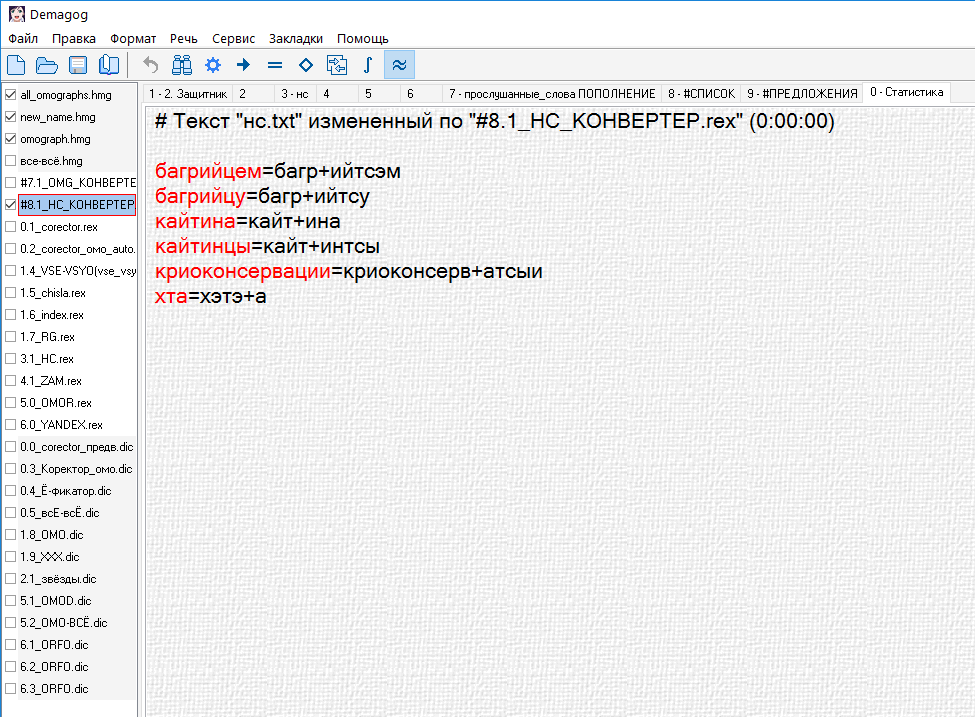
Пример применения:
Piligrim писал(а): ↑02 ноя 2020 09:17
и "поиск новых слов"?
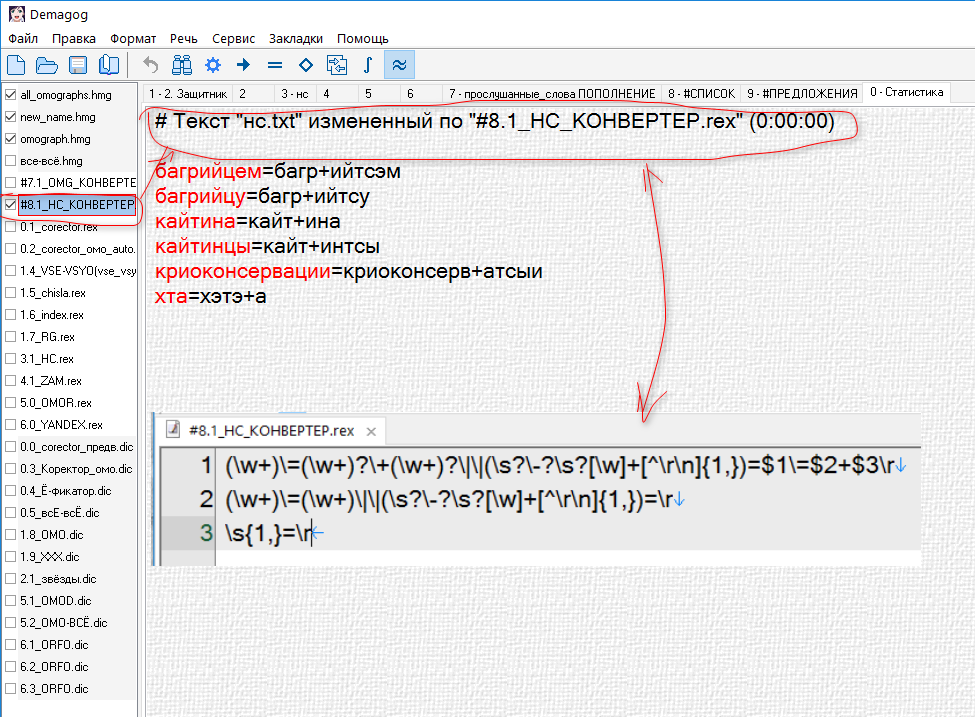
а это уже не в настройках Демагога, отдельно написанный скрипт:
Пример применения:
Перед запуском скрипта рекомендуется провести первичную обработку текста в том числе с расстановкой ё-фикации иначе найденные новые слова будут выведены одни, а после ёфикации получаются другие - лишняя работа получится.
После прослушивания новых слов, список вставляем в окно 7 "прослушанные_слова ПОПОЛНЕНИЕ" и сохраняем. При этом, можно смело копировать строки из окна 8 и 9 - вся лишняя информация будет удалена при повторном запуске скрипта
Найти "имена" или найти "новые слова" - это практически одно и то же. Только в первом случае ищутся новые слова среди имен и аббревиатур. Можно сначала искать имена а затем новые слова - так списки будут меньше - удобнее?
По умолчанию, в результаты выводятся все найденные новые слова и имена. Если нужно выводить только те, которые в книге встречаются часто, то одиночные слова можно удалить из выводимого списка. Для этого:
Код: Выделить всё
-- удалить строки со словами встречающиеся в тексте только (1|2|3|4) -- перечислить
r0=[[
#^.*‹(1|2|3|4)›.*$=
]]
удаляем символ решетки и перечисляем какие результаты не выводить. Например:
Yandex TTS
Добавлено: 02 ноя 2020 16:06
Piligrim
tonio_k писал(а): ↑02 ноя 2020 15:07
Пример как применить словарь к тексту...
...отдельно написанный скрипт:
Demagog.zip
Пример применения...
По умолчанию, в результаты выводятся все найденные новые слова и имена. Если нужно выводить только те, которые в книге встречаются часто, то одиночные слова можно удалить из выводимого списка. Для этого:
КОД: ВЫДЕЛИТЬ ВСЁ
-- удалить строки со словами встречающиеся в тексте только (1|2|3|4) -- перечислить
r0=[[
#^.*‹(1|2|3|4)›.*$=
]]
удаляем символ решетки и перечисляем какие результаты не выводить. Например:
КОД: ВЫДЕЛИТЬ ВСЁ
^.*‹(1)›.*$=
Ув. tonio_k Благодарю Вас за скрипт, за пояснения и видео. Всё понятно. Скачал, уставновил. Теперь буду экпериментировать.
Yandex TTS
Добавлено: 03 ноя 2020 19:46
tonio_k
2 ошибки исправил в скрипте:
1) вместо удаления лишних предложений в выводимом списке удалялись только знаки конца предложения.
2) при чистке словаря ПОПОЛНЕНИЕ удалялась латинская d вместо удаления чисел
+Добавил вывод окна-напоминание о необходимости провести первичную обработку.
Yandex TTS
Добавлено: 03 ноя 2020 23:48
Piligrim
Благодарю Вас, tonio_k. Я перезаписал скрипт, но пока не дошёл до его освоения.
Используя словарь на 3 миллиона слов, столкнулся с тем, что Филипп и Алёна приобрели уральский окающий акцент. Все эти короткие частички и слова (типа "т+о", "+от", "п+о") режут слух, хоть и правильно произносятся, но с паузами. Эти появившиеся лишние плюсики мешают голосовому движку правильно произносить предложения там, где они появились...
Попытался на слух определить излишние плюсы в словах, сравнивая с тем, что произносит синтезатор и проплюсованные ударения... Думаю, что у меня не хватит терпения на этот "мартышкин труд"...
Yandex TTS
Добавлено: 03 ноя 2020 23:58
wasyaka
tonio_k писал(а): ↑01 ноя 2020 10:39
о практической полезности словаря ничего сказать не могу.
Имеется в виду
орфоэпический словарь русского языка
Небольшой эксперимент (все что больше одного раз встречается, я прослушиваю, но не вначале,как предлогает
tonio_k, а после обработки словарями...Совпавшие со словарём :
Код: Выделить всё
банковым=б+анковым
братов=бр+атов
бутончиков=бут+ончиков
выемках=в+ыемках
высокопреподобие=высокопрепод+обие
генштабисты=генштаб+исты
дедукцией=дед+уктсыей
ельцовым=+ельтсовым
ермиловой=+ермиловой
забайкальцами=забайк+альтсами
забайкальцев=забайк+альтсэв
забайкальцы=забайк+альтсы
ионг=+ионг
капор=к+апор
картавостью=карт+авостью
лагунов=лагун+ов
личниками=л+ичниками
личником=л+ичником
марксистскую=маркс+истскую
мызы=м+ызы
обмишулится=обмиш+улится
околоточных=окол+оточных
политэмигрант=политэмигр+ант
полонэза=полон+эза
приглашено=приглашен+о
пуржило=пурж+ило
справках=спр+авках
сумском=сумск+ом
террористке=террор+истке
топографического=топограф+ического
уссурийцев=уссур+ийтсэв
уссурийцы=уссур+ийтсы
хабаровским=хаб+аровским
черевину=чер+евину
эстре=+эстре
ясумаса=+ясумаса
айгуне=+айгуне
айгунь=+айгунь
айгуня=+айгуня
альберс=+альберс
анисимовым=+анисимовым
астрахановки=+астрахановки
биваке=бив+аке
босоногими=босон+огими
бронепоездах=бронепоезд+ах
бунтарка=бунт+арка
гиляка=гиляк+а
гиляке=гиляк+е
гонконгского=гонк+онгского
девиза=дев+иза
екатерино=+екатерино
ериловым=+ериловым
женьшеню=женьш+еню
забайкальца=забайк+альтса
зарезанными=зар+езанными
илинский=+илинский
илинским=+илинским
ихэтуани=+ихэтуани
ихэтуань=+ихэтуань
крупозного=круп+озного
кульбита=кульб+ита
надульник=над+ульник
пенициллину=пенитсылл+ину
погодков=пог+одков
подхорунжим=подхор+унжим
поручикам=пор+учикам
привилегиях=привил+егиях
противодифтерийной=противодифтер+ийной
сэпсисом=с+эпсисом
сэттльментах=с+эттльментах
сэттльменты=с+эттльменты
цзяо=тсз+яо
цинское=тс+ынское
эндимион=+эндимион
юнгуань=+юнгуань
юнгуаню=+юнгуаню
янчис=+янчис
янчиса=+янчиса
янчису=+янчису
ярон=+ярон
ярона=+ярона
абрикосовый=абрик+осовый
андалусского=андал+усского
безземельного=беззем+ельного
ботфорта=ботф+орта
ботфортов=ботф+ортов
бубенчиков=буб+енчиков
венецианское=венетсы+анское
владетельница=влад+етельнитса
выкупленные=в+ыкупленные
высокоуглеродистую=высокоуглер+одистую
гиды=г+иды
гребешками=гребешк+ами
дончаками=дончак+ами
дончаки=дончак+и
дончаков=дончак+ов
доплатами=допл+атами
закладного=закладн+ого
залоговые=зал+оговые
запорожцами=запор+ожтсами
индигената=индиген+ата
исповеднику=испов+еднику
канарском=кан+арском
каронад=карон+ад
каронады=карон+ады
кастратами=кастр+атами
каширские=каш+ирские
каширских=каш+ирских
каширскому=каш+ирскому
каширскую=каш+ирскую
кэч=к+эч
кинематические=кинемат+ические
конопатенькая=коноп+атенькая
коронных=кор+онных
крестимся=кр+естимся
кси=кс+и
кумовья=кумовь+я
ливнестока=ливнест+ока
ливнестоке=ливнест+оке
любке=л+юбке
малага=мал+ага
малаге=мал+аге
малагу=мал+агу
металлорежущего=металлор+ежущего
наливную=наливн+ую
обороноспособностью=обороноспос+обностью
окладами=окл+адами
оправке=опр+авке
пахолки=п+ахолки
пахолков=п+ахолков
переносчиками=перен+осчиками
пиастр=пи+астр
пиастра=пи+астра
пиастру=пи+астру
повеселевшие=повесел+евшие
повета=пов+ета
подорожные=подор+ожные
послаблении=послабл+ении
посполитых=посполит+ых
пустотелые=пустот+елые
равелины=равел+ины
резьбовое=резьбов+ое
сабелька=с+абелька
сарабанду=сараб+анду
сечевом=сечев+ом
собакевичем=собак+евичем
собакевичу=собак+евичу
соколец=сокол+етс
студиозы=студи+озы
талера=т+алера
тэнэриф=тэнэр+иф
тронному=тр+онному
феода=фе+ода
феодом=фе+одом
фехтовальщиком=фехтов+альщиком
химкомбинате=химкомбин+ате
хлопами=хл+опами
цехинами=тсэх+инами
ятагану=ятаг+ану
агрономической=агроном+ической
андалусского=андал+усского
арапки=ар+апки
арапы=ар+апы
астурийской=астур+ийской
баркентину=баркент+ину
баулу=ба+улу
безводная=безв+одная
бессарабских=бессар+абских
благоприятны=благопри+ятны
бульбой=б+ульбой
бушменов=бушм+енов
венчаний=венч+аний
внебрачные=внебр+ачные
галерники=гал+ерники
гафель=г+афель
гафельный=г+афельный
глупей=глуп+ей
годичного=год+ичного
готтентотов=готтент+отов
готтентоты=готтент+оты
гуртильное=гурт+ильное
десятине=десят+ине
договаривающаяся=догов+аривающаяся
долевое=долев+ое
заслужат=засл+ужат
зулусской=зул+усской
индигената=индиген+ата
калана=кал+ана
камнереза=камнер+еза
капральство=капр+альство
каронад=карон+ад
каронады=карон+ады
каширских=каш+ирских
коваля=ковал+я
корабелом=кораб+елом
краснодеревщики=краснодер+евщики
круглогодичных=круглогод+ичных
кругосветки=кругосв+етки
лозняка=лозняк+а
любке=л+юбке
малаге=мал+аге
малагу=мал+агу
маловатая=малов+атая
маловатых=малов+атых
монетные=мон+етные
нгони=нгон+и
объединилось=объедин+илось
полостную=полостн+ую
полугодичное=полугод+ичное
портиков=п+ортиков
принайтованного=принайт+ованного
равелинов=равел+инов
равелины=равел+ины
рангоутное=ранг+оутное
розарию=роз+арию
розария=роз+ария
селене=сел+ене
селеной=сел+еной
селену=сел+ену
слоновых=слон+овых
стакселей=ст+акселей
стаксели=ст+аксели
стакселях=ст+акселях
талера=т+алера
тэнэриф=тэнэр+иф
ткачихами=ткач+ихами
феода=фе+ода
феоде=фе+оде
феодом=фе+одом
флейтов=фл+ейтов
фомке=ф+омке
хромистый=хр+омистый
чеканочной=чек+аночной
шатунную=шат+унную
шебеках=шеб+еках
шеренговый=шер+енговый
шкиперские=шк+иперские
штэмпели=шт+эмпели
При вычетке (голос Ермила)осталось невпопад
Код: Выделить всё
картавостью=карт+авостью
уссурийцев=уссур+ийтсэв
эстре=+эстре
ясумаса=+ясумаса
айгуне=+айгуне
айгунь=+айгунь
айгуня=+айгуня
астрахановки=+астрахановки
екатерино=+екатерино
ериловым=+ериловым
сэттльментах=с+эттльментах
янчиса=+янчиса
янчису=+янчису
малага=мал+ага
пахолков=п+ахолков
баркентину=баркент+ину
баулу=ба+улу
нгони=нгон+и
флейтов=фл+ейтов
штэмпели=шт+эмпели
из 238 -и ошибочных 20
И как им распоряжатся ...?
Каждый выбирает сам...

ПыСы
Ц заранее меняется на тс
це на тсэ
ци на тсы
Yandex TTS
Добавлено: 04 ноя 2020 00:57
tonio_k
wasyaka писал(а): ↑03 ноя 2020 23:58
но не вначале,как предлогает tonio_k, а после обработки словарями
согласен, что так правильно (в результате список новых слов получается в разы меньше по размеру), но я обошёл эту необходимость так (для голоса Максим):
из всех словарей *ФОНЕМЫ* вытащил все слова к которым есть замены (левую часть правил) и добавил их списком в файл "прослушенные слова" т.е. продублировал в этом словаре.
В результате, эти слова в список новых слов (после срабатывания скрипта) уже не попадают. Т.о. можно получить список новых слов не прогоняя всю книгу всеми словарями, а только словарями предварительной обработки.
Сделав один раз такую "синхронизацию" словарей замен со словарем "прослушенные слова", больше к этой процедуре возвращаться не надо, при условии постоянного/регулярного использования скрипта "новые слова" т.к. новые слова заносятся в прослушенные одновременно с новыми правилами.
Ещё раз повторюсь,
словарь Орфоэпический надо использовать с осторожностью! Особенно с Яндексом т.к. он по умолчанию лучше ставит ударения чем тот же Максим.
Скрипт, который я выложил, отличается от того, который я лично использую для Максима. Скрипт для Максима делает ещё несколько операций и заполняет ещё пару дополнительных окон с промежуточными результатами. Всё это делается потому, что фонетические транскрипции (для Максима) к словам в Демагоге можно генерировать пакетно к списку слов и в 90% случаев, благодаря Орфоэпическому словарю, произношение в конкретном слове либо не меняется, либо становится лучше (что ещё раз говорит о том, что Максим ударения ставит хуже чем Яндекс). А получить автоматически ударения к 80% новых слов (из которых всего 3-5 произносятся не верно) это большое подспорье и автоматизация рутины вставки ударений в новые слова перед подготовкой книги к озвучке.
Yandex TTS
Добавлено: 04 ноя 2020 22:24
wasyaka
chibis писал(а): ↑01 ноя 2020 12:06
kreb писал(а): ↑31 окт 2020 22:51
У меня установлена 32-разрядная ОС. На ней никак не получится?
Отправил в личку 32-битные версии библиотек и ffmpeg
Это каждому обладателю win х 32 делать запрос?
Yandex TTS
Добавлено: 04 ноя 2020 22:56
wasyaka
chibis писал(а): ↑01 ноя 2020 12:59
Я собственно из-за этого и хочу насобирать словарь побольше,
И как он должен выглядеть? ( это касаемо премиум голосов)
Вычитка - слово
лыцарь и в склонении - Ермил пробурчал чтото не понятное -ну и спорт интерес - а как у випов?
Филип - как и написано...
Задело..
А как омографы?
Несколько фраз с одним омографом но в разном ударении - + фразы с
все-всё и всё - ОК правильно - и зачем словари? в смысле как понять с чем "боротся"?
Поспешил и у випов не всё гаразд(ОК)
Код: Выделить всё
алкогольные пары=алкогольные парЫ
пары йода=парЫ йода
Согласен - проще по старинке...
Yandex TTS
Добавлено: 08 ноя 2020 18:43
chibis
Piligrim писал(а): ↑01 ноя 2020 17:05
Поэтому буду рад, если в следующей Вашей сборке появятся дополнительные списки на форму (и расширенный словарь). Заранее благодарю.
Списки выбора скорости и интонации добавил, словарь тоже увеличил почти в три раза, собрав по форуму записей из разных сборок. Плюс еще записи со звездочками, одна такая запись покрывает сразу несколько возможных сочетаний. Пробовал добавить еще несколько десятков тысяч записей с "е" и "ё", но потом убрал, потому что количество срабатываний от этих ё практически не увеличивается. Проверил сборку на нескольких книгах- ловит в среднем в два с половиной раза больше замен чем предыдущая. Если добавить однословные раньше проблемные записи, то можно поймать значительно больше, но по-моему премиум голосам однословные однозначные записи не нужны. Словари для удобства разделил по разным назначениям.
wasyaka писал(а): ↑
Это каждому обладателю win х 32 делать запрос?
32 бита выложу попозже, на новом ноуте пока нет инструмента для сборки 32 бит.
wasyaka писал(а): ↑
и зачем словари? в смысле как понять с чем "боротся"?
Я тоже заметил, что филипп со временем начинает произносить правильно те словосочетания, которые раньше произносил неправильно. Может скоро яндекс сам порешает все эти проблемы с ударениями, лишь бы не прикрыл аттракцион неслыханной щедрости после этого.
Yandex TTS
Добавлено: 08 ноя 2020 19:12
Haarhuss
chibis писал(а): ↑08 ноя 2020 18:43
yndx_tts64.zip
Большое спасибо :) Пользуюсь предыдущей версией и очень доволен качеством Филиппа.
Yandex TTS
Добавлено: 08 ноя 2020 21:15
Piligrim
chibis писал(а): ↑08 ноя 2020 18:43
Если добавить однословные раньше проблемные записи, то можно поймать значительно больше, но по-моему премиум голосам однословные однозначные записи не нужны. Словари для удобства разделил по разным назначениям.
yndx_tts64.zip (27.25 МБ)
Скачал, опробовал, в полном восторге!!! Благодарю, chibis. Особенно понравились словари, которые можно пополнять (используя скрипт от tonio_k в Демагоге).
Yandex TTS
Добавлено: 09 ноя 2020 16:10
olelog
Попробовал в "yndx_tts64.zip" проверить словарь DicOMG на ошибки через демагог и вот что вышло, ошибок очень много, со словарем надо поработать.
Yandex TTS
Добавлено: 09 ноя 2020 22:46
chibis
olelog писал(а): ↑09 ноя 2020 16:10
Попробовал в "yndx_tts64.zip" проверить словарь DicOMG на ошибки через демагог и вот что вышло, ошибок очень много, со словарем надо поработать.
Дубликаты должны автоматически удаляться в процессе сортировки, но это если записи полностью одинаковые. А у этих пар разные правые части поэтому они не удалились сами. В любом случае применится только одна запись, вторая с такой же левой частью естественно уже не применится. Я согласен, из двух записей пары, нужно выбрать какую-то одну, ту у которой более удачная правая часть. Насколько заметил бегло просмотрев отчет - записи отличаются в основном тем что в одной проставлены ударения в двух словах сочетания, а в другой только в одном. Поэтому я думаю можно просто при сортировке из двух таких записей, автоматом оставлять ту у которой плюсиков в правой части больше. Ударения проставлены человеком, значит адекватны и вреда от ударения не будет. Тем более, что яндекс постоянно учится, боюсь что уже сейчас б+ольшая часть ударений которые мы отсылаем, на самом деле ему не нужна.
Yandex TTS
Добавлено: 10 ноя 2020 07:42
Piligrim
chibis писал(а): ↑08 ноя 2020 18:43
Плюс еще записи со звездочками, одна такая запись покрывает сразу несколько возможных сочетаний.
В словаре dicOMGaster в словопарах с крайней звёздочкой справа (например - *ение места преступлен*=ение м+еста преступлен*) в текст попадает ненужная звёздочка: ение м+еста преступлен* Я у себя их поудалал. Новая сборка работает великолепно! Благодарю Вас, chibis.
Yandex TTS
Добавлено: 10 ноя 2020 13:41
olelog
Сборка работает хорошо, слов нет, однако заметил, что ввиду большой "замусоренности" словарей сильно снижена скорость обработки, да и траффика жрет в три раза больше чем к примеру с версией Play5_fillip, со старым словарем в 750кб Если сидишь на мобильном интернете, то это существенно. Кстати иногда случаеются накладки, если использовать свой доп. словарь. Исправленные слова работают неправильно. Буду пробовать их слить в один без дубликатов. Ну а исправлять такое огромное количество ошибок после проверки демагогом вручную это безумие.
Yandex TTS
Добавлено: 10 ноя 2020 14:26
Haarhuss
Заметил, что "м-да" читается как "н девяносто один н девяносто один" .
В словаре dicOMG такие строчки "м-да=н%91н%91, да" и "м-да=н`н`-да" .
Yandex TTS
Добавлено: 10 ноя 2020 15:16
olelog
то же самое с оп-па=оп%91п%91п%91-па, я поудалял эти абраказябры и все.
Yandex TTS
Добавлено: 10 ноя 2020 21:10
chibis
Piligrim писал(а): ↑10 ноя 2020 07:42
В словаре dicOMGaster в словопарах с крайней звёздочкой справа (например - *ение места преступлен*=ение м+еста преступлен*) в текст попадает ненужная звёздочка: ение м+еста преступлен* Я у себя их поудалал.
Это значит я пропустил, хотя смотрел дважды, и при импорте и уже в готовом словаре. Звездочек(если конечно они сами по себе не являются частью текста), с права от знака равно быть не должно.
Haarhuss писал(а): ↑10 ноя 2020 14:26
В словаре dicOMG такие строчки "м-да=н%91н%91, да" и "м-да=н`н`-да"
Эта запись и еще оп-па с символами процентов тоже попала в словарь по моему недосмотру - она была с словаре от последней версии Play_5, когда на демостранице еще использовалось url-кодирование, поэтому выглядит так странно. Я сейчас прогоню словари нотепадом, на поиск ненужных звезд, процентов и одинаковых левых частей. Просто пока ошибку кто-нибудь не обнаружит, непонятно какого-рода косяки в записях отлавливать.
olelog писал(а): ↑10 ноя 2020 13:41
траффика жрет в три раза больше чем к примеру с версией Play5_fillip, со старым словарем в 750кб Если сидишь на мобильном интернете, то это существенно.
Трафик зависит только от звуковых файлов, вклад именно текста принебрежительно мал и словарь на трафик вообще никак повлиять не может. Я сначала подумал, может чем медленнее скорость озвучки, тем больше размер файлов, но нет. Длительность аудио естественно больше, но размер практически такой же, в районе 3.5 мегабайт на 5000-символьный текст. Чтобы трафика было в три раза больше, размер одного звукового файла должен быть больше десяти Мб. Посмотрите в папке Audio, какой размер у .ogg файлов до того как они склеятся.
Yandex TTS
Добавлено: 10 ноя 2020 22:41
chibis
Вот, зачистил словари от указанных косяков, пока руками при помощи нотепада, но потом хочу сделать так чтоб в процессе сортировки само проверялось на корректность.
Оба надо положить в папку Sys.
Yandex TTS
Добавлено: 11 ноя 2020 09:13
olelog
Огромное спасибо chibis за работу ! Я в свою очередь объединил еще свой словарь с последним от chibis отсортировал без дубликатов и по убыванию, однако возникли некоторые ошибки про проверке. В архиве все показал. Если доработать будет вообще отлично !
Yandex TTS
Добавлено: 11 ноя 2020 10:47
flegont
Доп
устим, книга не нуждается в исправлении произношения, потому что уже обработана словарями с помощью сторонних программ. Как в сборке
отключить словари
dicOMG.txt и
dicOMGaster.txt?

Yandex TTS
Добавлено: 11 ноя 2020 13:51
Piligrim
flegont писал(а): ↑11 ноя 2020 10:47
Как в сборке отключить словари dicOMG.txt и dicOMGaster.txt?
Я поступил так - распаковал программу в папку №2 и обнулил в ней содержимое всех словарей.
Yandex TTS
Добавлено: 11 ноя 2020 19:22
chibis
olelog писал(а): ↑11 ноя 2020 09:13
однако возникли некоторые ошибки про проверке. В архиве все показал. Если доработать будет вообще отлично !
Здесь тоже одинаковые левые части, которые получаются при объединении словарей. Я прогнал словарь notepadом++ через вот такую регулярку "^(.*)=(.*)\r\n\1=.*", она ищет левые дубликаты. Если в поле для замены написать "$1=$2", то в зависимости от расстановки скобок можно выбрать правую часть либо от первой записи либо от второй. В случае когда записей относительно немного, можно даже использовать ручной выбор назначив горячие клавиши на первый или второй вариант. Результат отправлю в личку, но после этой операции и сортировки количество записей объединения возросло только на чуть больше тысячи. Остальные отсеялись либо, как полные дубликаты, либо как дубликаты по левым частям.
flegont писал(а): ↑11 ноя 2020 10:47
Допустим, книга не нуждается в исправлении произношения, потому что уже обработана словарями с помощью сторонних программ. Как в сборке отключить словари dicOMG.txt и dicOMGaster.txt?
Словари не отключаются, но можно сделать так как написал Piligrim.
Yandex TTS
Добавлено: 12 ноя 2020 01:29
npupoct
Больше спасибо chibis за отличный софт.
Посмотрите, пожалуйста, в последних версиях выходит ошибка:
{"error_code":"BAD_REQUEST","error_message":"Error while parsing and validating request: Requested text length exceed limitation(5000): 5046"}
В версии yndx_tts все работает хорошо.
Yandex TTS
Добавлено: 12 ноя 2020 14:17
olelog
Еще раз спасибо chibis за отличный софт. Как будет происходить сортировка списка словаря при добавлении новых слов, будут ли удаляться одновременно дубликаты ?
Yandex TTS
Добавлено: 12 ноя 2020 18:08
chibis
npupoct писал(а): ↑12 ноя 2020 01:29
Посмотрите, пожалуйста, в последних версиях выходит ошибка:
{"error_code":"BAD_REQUEST","error_message":"Error while parsing and validating request: Requested text length exceed limitation(5000): 5046"}
Быстрое решение - это открыть в текстовом редакторе файл "Play_5.hta", найти два вхождения числа "4950" и переправить его на "4750". Первое вхождение находится в строке 640, а второе в строке 656.
olelog писал(а): ↑12 ноя 2020 14:17
Как будет происходить сортировка списка словаря при добавлении новых слов, будут ли удаляться одновременно дубликаты ?
Сортируется по убыванию длин левых частей записей. При сортировке удаляются только полные дубликаты, то есть если и левая и правая часть у записей одинаковые. Если у записей левые части одинаковые, а правые разные, то такие дубликаты не удаляются. В следующий раз я добавлю обработку после сортировки регуляркой которую приводил выше. Сейчас если нужно, ее можно применить из текстового редактора поддерживающего регулярки.
И лучше сначала свои записи добавлять в локальный словарь из папки "Lexicon". Там они не сортируются, и будут находиться на тех местах куда их записали. А по мере накопления, те записи, которые решите оставить уже переносить в основные словари.
Yandex TTS
Добавлено: 13 ноя 2020 14:40
olelog
Еще заметил, что при слиянии словарей все слова с заглавных букв переписались на малый регистр, и при чтении делают ошибки. Приходится добавлять по новой.
Али-Баба=Али-Баб+а
Жигана=Жиг+ана
Yandex TTS
Добавлено: 13 ноя 2020 19:11
chibis
olelog писал(а): ↑13 ноя 2020 14:40
Еще заметил, что при слиянии словарей все слова с заглавных букв переписались на малый регистр, и при чтении делают ошибки.
Это я в текстовом редакторе преобразовал все буквы в строчные, потому что было много записей где ударения были проставлены не в виде плюсика, а в виде больших гласных букв. Яндекс одинаково произносит большие и маленькие буквы, поэтому алибабу и другие имена не надо писать с большой буквы. Добавляйте просто али-баба=али-баб+а
Yandex TTS
Добавлено: 14 ноя 2020 10:55
olelog
К сожалению это не так, не всегда малый и большой регистр читает одинаково, в данных примерах с большой буквы читает неправильно. Лично исправлял. Может со временем яндекс научится это делать.
Заметил еще, что для разных голосов например Алиса и Филлип по разному идет расстановка ударений. например "моего слОва" Филлип читает правильно а Алиса нет. Таких примеров море, Филлип читает гораздо "грамотнее". Правда зачастую на странице сервиса Yandex SpeechKit API многое из того что произносится правильно, при записи книги записывается неправильно.
Yandex TTS
Добавлено: 14 ноя 2020 12:32
Piligrim
olelog писал(а): ↑14 ноя 2020 10:55
Алиса и Филлип по разному идет расстановка ударений. например "моего слОва" Филлип читает правильно а Алиса нет
Проверил
https://cloud.yandex.ru/services/speechkit
"моего слова" и Алёна и Филипп читает правильно, не нужно обозначать "моего сл+ова",
"моего слОва" Филипп читает с паузой перед О "моего эсэл Ова", а Алёна - почти правильно: "моего сл Ова". Движок Элис (Алиса?) - вчерашний день.
Yandex TTS
Добавлено: 14 ноя 2020 12:44
wasyaka
olelog писал(а): ↑14 ноя 2020 10:55
Алиса и Филлип по разному идет расстановка ударений. например "моего слОва" Филлип читает правильно а Алиса нет.
Диалог между ними:
Филлип- А моего слОва вам достаточно?
Алиса: А у моего словА расходятся с делом...
Где-то так...
Yandex TTS
Добавлено: 17 ноя 2020 07:52
olelog
Постоянно сталкиваюсь с подобным "феноменом", книгу записал с ошибками голос "Fillip"
Катящиеся волнЫ
должно полУчиться
положение телА
слОва и призывы
Проверяю в сервисе SpeechKit через тот же голос - читает все правильно ! ??? Как быть, может стоит несмотря на "правильность чтения" в сервисе все же включать себе в словарь с "плюсами-ударениями" ?
Проверил все снова, включил данные словосочетания в текст, в словарь не включал, так и есть записало опять все неправильно за исключением "слова и призывы". Думал, что Филлип уже научился, однако нет ! И только включив данные словосочетания к себе в словарик получил "правильный текст". Делаю вывод, нельзя доверять полностью сервису при проверке слов. То ли запись книг идет с другого источника, то ли еще что... Если записало "неправильно", есть смысл включать себе в словарь во избежание повторения ошибок. Прикладываю маленький фрагмент для пробы.
Yandex TTS
Добавлено: 17 ноя 2020 18:44
chibis
olelog писал(а): ↑17 ноя 2020 07:52
Делаю вывод, нельзя доверять полностью сервису при проверке слов. То ли запись книг идет с другого источника, то ли еще что... Если записало "неправильно", есть смысл включать себе в словарь во избежание повторения ошибок.
Нет, вывод из этих примеров как противоположный - сервису можно доверять больше. Филипп с этим словосочетаниями прекрасно разобрался сам, а ошибки произношения это результат "коррекции" словарями. Потому-то текст посланный через демо-страницу произносится правильно - он не обрабатывается. В словарях есть записи "*иеся волны=иеся волн+ы" "*ние тела=ние тел+а" "получиться=пол+учиться". За "слОва и призывы" тоже очевидно ответственна какая-то запись, но связанная думаю со словом предшествущим сочетанию. Чтобы точно узнать виноват ли в ошибке непосредственно сам голос, или его вынуждает ошибаться неправильно проставленное ударение, проверяйте файл "replacingLog.txt". В него записывается текст, в том виде в каком его получает яндекс, т.е. уже с плюсиками. Я думаю подобные ошибки более логично исправлять, не добавлением в словарь новых записей, а удалением имеющихся если они не универсальны/не подходят филиппу/просто ошибочны/и.т.д.
Yandex TTS
Добавлено: 17 ноя 2020 21:44
speeck
wasyaka писал(а): ↑03 ноя 2020 23:58
ПыСы
Ц заранее меняется на тс
це на тсэ
ци на тсы
Вы меняете все ЦЕ/ЦИ на ТСЭ/ТСЫ? Это слишком радикальное решение, там очень много слов, которые произносятся корректно, станут произноситься хуже, и в добавок некоторые другие правила могут перестать работать (в виду замен исходных слов).
Лично я сделал так с ЦИ/ЦЕ (актуально для старого движка). Собрал наиболее популярные слова с ЦИ/ЦЕ, прослушал их, там где были косяки - сделал правила + размножил на другие словоформы (ЦИИ, ЦИОННЫЙ и тд). Большую часть наиболее употребительных слов данный способ охватывает, но далеко не все, например многие составные слова в пролете. Приходится выбирать из 2х зол.
Yandex TTS
Добавлено: 17 ноя 2020 21:56
speeck
chibis писал(а): ↑08 ноя 2020 18:43
словарь тоже увеличил почти в три раза, собрав по форуму записей из разных сборок
А вот тут нужно аккуратней! )
Несколько месяцев назад я решил объединить 2 сборки (словари): от tonio_k и wasyaka, и это было...... не могу подобрать аккуратного слова.
В целом, за несколько недель или месяцев, я более-менее привел полученную сборку к рабочему виду, но до сих пор в ней не уверен. Кстати, я тут обещал выложить её некоторое время назад - постараюсь на этой неделе (пришлось уехать по делам, только вернулся). Также постараюсь дать комменты, что делал и для чего, а также краткие справки по словарям, думаю кому-то пригодится.
Такой момент, может вы, chibis, подумаете. Было бы здорово периодически объединять словари разных пользователей, но тут нужна единая система, и наверное модератор, чтобы не плодились пользовательские словари + объединенные разными людьми. Как бы организовать такую систему? И, вообще, насколько актуальны словари под Филиппа? Еще не довелось протестировать его, но судя по постам выше, сколько-то нужны.
Yandex TTS
Добавлено: 17 ноя 2020 22:06
speeck
chibis писал(а): ↑13 ноя 2020 19:11
Это я в текстовом редакторе преобразовал все буквы в строчные, потому что было много записей где ударения были проставлены не в виде плюсика, а в виде больших гласных букв
Вы отказались от этой системы? Иногда нужно подсунуть Яндексу ударение именно через большую букву, есть также правила в словарях, где учитываются заглавные буквы: "Валя" - имя, "валя" - топая куда-нибудь, ударения будут разные.
Yandex TTS
Добавлено: 18 ноя 2020 14:15
olelog
Со словарями нужна какая то система, например для голоса Филлип. Словарь в yndx_tts64 огромный и раздутый, я понимаю, что наполовину он мешает правильному произношению Филлипа. Кто то хорошо разбирающийся должен навести порядок в словарях. Если это сделать не руками а как то программно, скриптами было бы здорово.
Yandex TTS
Добавлено: 18 ноя 2020 18:46
chibis
speeck писал(а): ↑17 ноя 2020 21:56
А вот тут нужно аккуратней! )
Несколько месяцев назад я решил объединить 2 сборки (словари): от tonio_k и wasyaka, и это было...... не могу подобрать аккуратного слова.
Это да, с объединениями все не так просто. Обидно еще и то, что после приведения записей в готовом словаре к одному формату, получаются одинаковые записи. То есть в словарях из разных сборок по сути одни и те же записи, только в разных форматах и с небольшими вариациями. После хотя бы синтаксической зачистки остается сумма намного меньше чем слагаемые вместе.
speeck писал(а): ↑17 ноя 2020 21:56
Было бы здорово периодически объединять словари разных пользователей, но тут нужна единая система, и наверное модератор, чтобы не плодились пользовательские словари + объединенные разными людьми. Как бы организовать такую систему?
После прочтения вот этого сообщения tonio_k, даже не знаю насколько это перспективно:
http://i91650e3.beget.tech/viewtopic.php?f=55&t=434#p2432
speeck писал(а): ↑17 ноя 2020 21:44
И, вообще, насколько актуальны словари под Филиппа? Еще не довелось протестировать его, но судя по постам выше, сколько-то нужны.
Я полтора месяца назад когда узнал про Филиппа, пробовал озвучивать без словаря непосредственно через демо страницу - выходило в среднем 3 - 5 ошибок на 5000 тысячный кусок текста. Это вообщем очень даже неплохо, но в готовую первую сборку решил добавить обработку средствами Play_5, чтобы была возможность быстрого исправления специфических слов часто, встречающихся в конкретной статье или книге. После НГ снова хочу попробовать без словаря, с учетом прогресса Филиппа, и того что яндексоиды могут как и с прошлой демкой пригрозить отключить демку в НГ.
speeck писал(а): ↑17 ноя 2020 21:56
Вы отказались от этой системы? Иногда нужно подсунуть Яндексу ударение именно через большую букву, есть также правила в словарях, где учитываются заглавные буквы: "Валя" - имя, "валя" - топая куда-нибудь, ударения будут разные.
Яндекс (по крайней мере Филипп)большую гласную в качестве ударения не воспринимает, только плюсик перед гласной. Про имена, спасибо за подсказку, я это учту.
Yandex TTS
Добавлено: 18 ноя 2020 19:09
speeck
chibis писал(а): ↑18 ноя 2020 18:46
Яндекс (по крайней мере Филипп)большую гласную в качестве ударения не воспринимает
А вы попробуйте прослушать этот кусочек текста:
► Показать
Месим тесто.
Месим тестО.
МесИм тесто.
Хоть и не ударение, но произношение заметно меняется )
Yandex TTS
Добавлено: 18 ноя 2020 21:40
chibis
speeck писал(а): ↑18 ноя 2020 19:09
Хоть и не ударение, но произношение заметно меняется )
И правда, меняется. Я так понял что яндекс большие буквы в середине слова, как гласные, так и согласные считает началом следующего слова, как будто перед большой буквой есть пробел. Получается Месим тестО, звучит как Месим тест О. Интересно если ради прикола заменить начальные буквы всех слов в книге на большие и удалить пробелы, как отреагирует на такую оптимизацию? Вот такую классику правильно читает: 'СъешьЕщёЭтихМягкихФранцузскихБулок,ДаВыпейЧаю' )
Yandex TTS
Добавлено: 18 ноя 2020 22:01
speeck
chibis писал(а): ↑18 ноя 2020 21:40
Я так понял что яндекс большие буквы в середине слова, как гласные, так и согласные считает началом следующего слова, как будто перед большой буквой есть пробел. Получается Месим тестО, звучит как Месим тест О. Интересно если ради прикола заменить начальные буквы всех слов в книге на большие и удалить пробелы, как отреагирует на такую оптимизацию? Вот такую классику правильно читает: 'СъешьЕщёЭтихМягкихФранцузскихБулок,ДаВыпейЧаю' )
Занятный пример, действительно как-будто пробелы.
Но на старых голосах это можно было использовать как альтернативу ударениям. Не найду сейчас пример, но некоторые слова я разударял именно через регистр вместо плюса, т.к. с последним ударение не нравилось, а через регистр звучало хорошо.
Насчет Филиппа пока сложно сказать точно, но на первый взгляд он по другому произносит такие слова, вероятно проставить ударения таким образом с ним не получится, но можно поэкспериментировать (если нужно вообще).
Yandex TTS
Добавлено: 19 ноя 2020 12:09
wasyaka
speeck писал(а): ↑17 ноя 2020 21:44
Вы меняете все ЦЕ/ЦИ на ТСЭ/ТСЫ?
tonio_k писал(а): ↑02 ноя 2020 15:07
Piligrim писал(а): ↑02 ноя 2020 09:17
и "поиск новых слов"?
а это уже не в настройках Демагога, отдельно написанный скрипт:
Demagog.zip
Мой
Пример применения:
#ПРЕДЛОЖЕНИЯ
► Показать
апгрейдим || поколение баз ваших искинов мы Апгрейдим настолько, что они превзойдут
артустановок || Вот прилетел привет от артустановок рейдера.
атанай || договор не подписывали, а командор Атанай на тот момент являлся высшим лицом
атаная || он, похоже, не пожелал держать Атаная вместе с предателями на спасательной
багрийки || - Свободные багрийки сами вынашивают своих детей.
багрийских || Кейла сразу же затребовала базы Багрийских разработчиков.
багрийское || - Оставь моё Багрийское происхождение в покое.
багрийцем || криоконсервации людьми, тремя ирианцами и багрийцем.
багрийцу || Багрийцу нашлось чем ответить, и в сторону
бранте || - Ты о Тионе и Бранте, - даже не спрашивая, а скорее
бранту || Вообще то Бранту нужно нарабатывать командирский
вариканс || ближайшую базу флота в системе Вариканс, потому как вручить каперский
варикансе || В Варикансе находился весьма оживлённый перекрёсток
видеосенсорам || безопасности и подключиться к видеосенсорам, высоки.
вирткресел || Ни вирткресел, ни стационарного искина у меня
гарон || - Как видно, господин Гарон решил, что раз выплатил премию,
гарона || от владельца станции господина Гарона.
гермодверью || За открывшейся гермодверью сразу оказались в одном из технических
гравикаре || Он уже устроился в гравикаре, когда искин уведомил о входящем
гравикары || проЕзжая часть, по которой сновали гравикары.
дарган || - между тЕм продолжал читать Дарган.
датор || - Фрегатом Датор, обнаруженным вами, командовал
датора || Искин Датора засёк векторы, по которым ушли
деактивированными || Как, впрочем, и отсек с деактивированными десантниками.
деактивированы || всЕ деактивированы и законсервированы.
жёлтовым || раньше подобное не водилось, но с жёлтовым они явно спелись.
иглогранаты || Плазменные, ЭМИ - и иглогранаты.
иглометные || - А иглометные установки?
ингера || И вроде как огневые точки Ингера контролируют земляне, но есть
ирианским || понимаю, данный фрегат буксируется ирианским кораблём?
итейя || Вы слышали о планете Итейя в системе Сатойя?
итор || - Итор не мой сын, - покачав головой,
итора || дал аккаунт Пошнагова и тогО Итора?
кайтина || Экономика Кайтина, конечно, развивалась, но средств
кайтином || проверить машИны, подобранные Кайтином у Ханайды.
кайтину || Мы получим доступ к Кайтину, - подняв руку в останавливающем
кайтинцы || Но де - юре кайтинцы являлись лишь союзниками ирианцев,
ковальская || некая польская панночка, Эва Ковальская, с которой Андрей учился в школе
криоконсервации || капсулы с функциями анабиоза и криоконсервации?
лаберж || можем, - констатировал лейтенант Лаберж, командир второго фрегата.
пактур || командир отдельного отряда адмирал Пактур Райдан.
паулиния || Двигайте в закусочную Паулиния и ждите меня там.
противоабордажная || Согласно уставу на бортУ остаётся Противоабордажная команда.
противоабордажной || должно было остаться два отделения противоабордажной команды.
райдан || отдельного отряда адмирал Пактур Райдан.
райдана || Пока ясно только одно - у Райдана есть свой интерес.
райданом || пришлось вдрызг рассориться с Райданом - младшим.
рбд || используя ракеты большой дальности, РБД.
сатойя || слышали о планете Итейя в системе Сатойя?
симбиотика || одним из немногих обладателей симбиотика.
симбиотики || Симбиотики?
стир || Многострадальный Стир, флагманский линкор, на этот раз
таркена || афёре Андрея на Талаханке команда Таркена хорошо приподнялась.
терёхина || Про Дорсу Андрей слышал от терёхина.
тиона || - Тиона, госпожа, - вытянувшись в струнку
тионе || удовлетворённо кивнула и протянула гаджет Тионе.
тионой || А что с Тионой?
тиону || - Ты хочешь очаровать Тиону или нашла повод приставить меня
тионы || - Искин Тионы тренькнул, уведомив о входящем
тронке || То есть на Тронке, негласной, но общепризнанной
тулен || Тулен и двое его подчинённых воспользовались
удгенд || если проверить тяжёлый крейсер Удгенд?
удгенда || багриец, но его капсулу искин Удгенда уж точно спасать не станет.
фодо || Нынешний хозяин Фодо был бог весть каким по счёту.
ханайда || Они направлялись на станцию Ханайда, принадлежащую рудодобывающей
ханайду || ещё и оказались здесь, минуя Ханайду?
ханайды || машИны, подобранные Кайтином у Ханайды.
хта || - Внимание, ХТА - 9212 - 3087 - 4563 - 5295, на
эдоган || Некто Эдоган.
эдогана || Ведь Эдогана всЕ ещё нет на станции.
эдогану || интересующую их информацию по господину Эдогану, как раздобыл и спектральную карту
После небольшой обработки (удаляются слова поподающие под "звёзды" и имеющие букву
ё, ну и
ц в правой части меняется на
тс)
При прослушке где надо ставится
+
► Показать
апгрейдим=апгрейдим|| поколение баз ваших иск+инов мы Апгрейдим настолько, что они превзойдут
артустановок=артустановок|| Вот прилетел привет от артустановок рейдера.
атанай=атанай|| договор не подписывали, а командор Атанай на тот момент являлся высшим лицом
атаная=атаная|| он, похоже, не пожелал держать Атаная вместе с предателями на спасательной
багрийки=багрийки|| - Свободные багрийки сами вынашивают своих детей.
багрийских=багрийских|| Кейла сразу же затребовала базы Багрийских разработчиков.
багрийское=багрийское|| - Оставь моё Багрийское происхождение в покое.
багрийцем=багр+ийтсэм|| криоконсервации людьми, тремя ирианцами и багрийцем.
багрийцу=багр+ийтсу|| Багрийцу нашлось чем ответить, и в сторону
бранте=бранте|| - Ты о Тионе и Бранте, - даже не спрашивая, а скорее
бранту=бранту|| Вообще то Бранту нужно нарабатывать командирский
вариканс=вариканс|| ближайшую базу фл+ота в системе Вариканс, потому как вручить каперский
варикансе=варикансе|| В Варикансе находился весьма оживлённый перекрёсток
видеосенсорам=видеосенсорам|| безопасности и подключиться к видеосенсорам, высоки.
вирткресел=вирткресел|| Ни вирткресел, ни стационарного иск+ина у меня
гарон=гарон|| - Как видно, господин Гарон решил, что раз выплатил премию,
гарона=гарона|| от владельца станции господина Гарона.
гермодверью=гермодверью|| За открывшейся гермодверью сразу оказались в одном из технических
дарган=дарган|| - между тЕм продолжал читать Дарган.
датор=датор|| - Фрегатом Датор, обнаруженным вами, командовал
датора=датора|| иск+ин Датора засёк векторы, по которым ушли
деактивированными=деактивированными|| Как, впрочем, и отсек с деактивированными десантниками.
деактивированы=деактивированы|| всЕ деактивированы и законсервированы.
иглогранаты=иглогранаты|| Плазменные, ЭМИ - и иглогранаты.
иглометные=иглометные|| - А иглометные установки?
ингера=ингера|| И вроде как огневые точки Ингера контролируют земляне, но есть
ирианским=ирианским|| понимаю, данный фрегат буксируется ирианским кораблём?
итейя=итейя|| Вы слышали о планете Итейя в системе Сатойя?
итор=итор|| - Итор не мой сын, - покачав головой,
итора=итора|| дал аккаунт Пошнагова и тогО Итора?
кайтина=кайт+ина|| Экономика Кайтина, конечно, развивалась, но средств
кайтином=кайтином|| проверить машИны, подобранные Кайтином у Ханайды.
кайтину=кайтину|| Мы получим доступ к Кайтину, - подняв руку в останавливающем
кайтинцы=кайт+интсы|| Но де - юре кайтинцы являлись лишь союзниками ирианцев,
ковальская=ковальская|| некая польская панночка, Эва Ков+альская, с которой Андрей учился в школе
криоконсервации=криоконсерв+атсыи|| капсулы с функциями анаби+оза и криоконсервации?
лаберж=лаберж|| можем, - констатировал лейтенант Лаберж, командир второго фрегата.
пактур=пактур|| командир отдельного отряда адмирал Пактур Райдан.
паулиния=паулиния|| Двигайте в закусочную Паул+иния и ждите меня там.
противоабордажная=противоабордажная|| Согласно уставу на бортУ остаётся Противоабордажная команда.
противоабордажной=противоабордажной|| должно было остаться два отделения противоабордажной команды.
райдан=райдан|| отдельного отряда адмирал Пактур Райдан.
райдана=райдана|| Пока ясно только одно - у Райдана есть свой интерес.
райданом=райданом|| пришлось вдрызг рассориться с Райданом - младшим.
рбд=рбд|| используя ракеты большой дальности, РБД.
сатойя=сатойя|| слышали о планете Итейя в системе Сатойя?
симбиотика=симбиотика|| одним из немногих обладателей симбиотика.
симбиотики=симбиотики|| Симбиотики?
стир=стир|| Многострадальный Стир, флагманский линкор, на этот раз
таркена=таркена|| афёре Андрея на Талаханке команда Таркена хорошо приподнялась.
тиона=тиона|| - Тиона, госпожа, - вытянувшись в струнку
тионе=тионе|| удовлетворённо кивн+ула и протянула гаджет Тионе.
тионой=тионой|| А что с Тионой?
тиону=тиону|| - Ты хочешь очаровать Тиону или нашла повод приставить меня
тионы=тионы|| - иск+ин Тионы тренькнул, уведомив о входящемудгенд=удгенд|| если проверить тяжёлый крейсер Удгенд?
удгенда=удгенда|| багриец, но его капсулу иск+ин Удгенда уж точно спасать не станет.
фодо=фодо|| Нынешний хозяин Фодо был бог весть каким по счёту.
ханайда=ханайда|| Они направлялись на станцию Ханайда, принадлежащую рудодобывающей
ханайду=ханайду|| ещё и оказались здесь, минуя Ханайду?
ханайды=ханайды|| машИны, подобранные Кайтином у Ханайды.
хта=хэтэ+а|| - Внимание, ХТА - 9212 - 3087 - 4563 - 5295, на
эдоган=эдоган|| Некто Эдоган.
эдогана=эдогана|| Ведь Эдогана всЕ ещё нет на станции.
эдогану=эдогану|| интересующую их информ+атсию по господину Эдогану, как раздобыл и спектральную карту
И финиш - всё не нужное удаляется, в остатке
► Показать
- 20.png (143.94 КБ) 4253 просмотра
Знак + в словах после || это также попавшие под звёзды - можно мельком просмотреть, а вдруг неправильно...
Yandex TTS
Добавлено: 19 ноя 2020 16:23
tonio_k
wasyaka писал(а): ↑19 ноя 2020 12:09
И финиш - всё не нужное удаляется, в остатке
что бы не ручками не удалять всё не нужное:
Код: Выделить всё
s=WText(0) -- окно 0
s=RexRepl(s,{[[\|\|.+$=]]})
s = string.split(s,'\r')
for i=1,#s do
if LuaMatch(s[i],'^[^=]+')==LuaMatch(s[i],'[^=]+$') then s[i]='' end
end
s = table.concat(s,'\r')
s = GoodText(s)
print(s)
Yandex TTS
Добавлено: 19 ноя 2020 18:23
wasyaka
tonio_k писал(а): ↑19 ноя 2020 16:23
что бы не ручками не удалять всё не нужное:
С чего ты решил, что ручками?
► Показать
- 20.png (223.74 КБ) 4200 просмотров
Yandex TTS
Добавлено: 19 ноя 2020 20:43
tonio_k
Хм, не приходил в голову такой простой вариант...
Попробуй вот такой вариант:
Код: Выделить всё
^(\w+=[\w+]+).+$::$1
^\w+=\w+$::
[\r\n]+::\r
- чуть короче и без перечисления "всех вероятных вариантов" справа от ||
Yandex TTS
Добавлено: 24 ноя 2020 21:27
andko
chibis писал(а): ↑08 ноя 2020 18:43
Списки выбора скорости и интонации добавил, словарь тоже увеличил почти в три раза, собрав по форуму записей из разных сборок. Плюс еще записи со звездочками, одна такая запись покрывает сразу несколько возможных сочетаний. Пробовал добавить еще несколько десятков тысяч записей с "е" и "ё", но потом убрал, потому что количество срабатываний от этих ё практически не увеличивается. Проверил сборку на нескольких книгах- ловит в среднем в два с половиной раза больше замен чем предыдущая. Если добавить однословные раньше проблемные записи, то можно поймать значительно больше, но по-моему премиум голосам однословные однозначные записи не нужны. Словари для удобства разделил по разным назначениям.
yndx_tts64.zip
Подскажите, пожалуйста, возникла такая проблема. Филипп не понимает некоторые добавления в словари, в основном, имена собственные. Я добавляю во все словари (и в UserLocal, и в dicOMG и dicOMGaster), например:
Озма=+Озма
Озме=+Озме
Озму=+Озму
Озмы=+Озмы
Биллина=Билл+ина
Биллине=Билл+ине
Биллину=Билл+ину
Биллины=Билл+ины
но он все равно произносит по-своему, с ударением на другой слог. Как это исправить?
Yandex TTS
Добавлено: 24 ноя 2020 23:44
tonio_k
andko писал(а): ↑24 ноя 2020 21:27
Как это исправить?
пробовали замену на слово с маленькой буквы?
Yandex TTS
Добавлено: 25 ноя 2020 01:31
andko
tonio_k писал(а): ↑24 ноя 2020 23:44
пробовали замену на слово с маленькой буквы?
Да, получилось, поставил оба слова маленькой буквы, благодарю.
Если можно, подскажите еще кое-что.
1) Как делать пауза побольше, после автора-названия книги, между главами и т. п.? Троеточие не распознается программой, как было год назад.
2) Иногда некорректно работает знак * отвечающий за разные падежи и окончания слов. Вроде бы, ставлю так же, как и в словарях dicOMG. Как нужно их расставлять правильно?
3) Во время воспроизведения полученного аудио ogg периодически слышны щелчки, как будто при скачках напряжения. Можно ли их убрать или минимизировать, сразу или при последующей конвертации в mp3?
Yandex TTS
Добавлено: 25 ноя 2020 09:49
GIS88
andko,
1) Знак «-» добавляет паузу, но программа его коверкает и он не работает. Например - Я Yandex .«-».«-».«-».«-». SpeechKit.
Yandex TTS
Добавлено: 25 ноя 2020 14:46
Lecron
Как на Яндекс ТТС прослушивать новые имена, на правильность их произношения? Балаболка не умеет или я не нашел. А другие?
 Demagog.zip
Demagog.zip