Страница 11 из 19
Yandex TTS
Добавлено: 13 окт 2020 16:09
tonio_k
К стати, если в скрипте удалить строку:
Код: Выделить всё
t = string.gsub(t,"=",'\r') -- экспорт dic в dicOMG.txt
то получим стандартные правила замен для dic словаря
Yandex TTS
Добавлено: 13 окт 2020 16:52
olelog
Спасибо "tino_k" все получилось правда в старой версии демагога Version 7.29.371
Как правильно этот результат из окна "статистика" правильно сохранить в dicOMG.txt ?
Yandex TTS
Добавлено: 13 окт 2020 17:41
tonio_k
Попробуйте файл "сохранить как" а где выбирается расширение вроде должно быть поле сохранить в ansi кодировке. Или можно открыть файл dicOMG.txt в блокноте, скопировать текст из окна статистики и вставить поверх содержимого dicOMG.txt и пересохранить
olelog писал(а): ↑13 окт 2020 16:52
и все равно сортировка не такая как у "chibis"
а какая у него сортировка?
Yandex TTS
Добавлено: 13 окт 2020 18:01
olelog
Сравните два файла, начало.
Yandex TTS
Добавлено: 13 окт 2020 18:10
olelog
t = string.gsub(t,"=",'\r') -- экспорт dic в dicOMG.txt удалил строку из скрипта не работает, поля сохранить в кодировке нет, просто выделяю из окна текст и копирую в dicOMG.txt
Yandex TTS
Добавлено: 13 окт 2020 18:23
tonio_k
Попробуйте такой вариант:
Код: Выделить всё
u=0
t={}
s=WText(1)
s = string.split(s,'\r')
for i=1,#s,2 do
u=u+1
t[u]=s[i]..'='..s[i+1]
end
t = table.sortcyr(t)--сортировка по алфавиту (кирилица)
t = table.concat(t, '\r')
t = string.gsub(t,"=",'\r') -- экспорт dic в dicOMG.txt
WNew(0,t)
WActive(0)
Yandex TTS
Добавлено: 13 окт 2020 18:26
tonio_k
olelog писал(а): ↑13 окт 2020 18:10
поля сохранить в кодировке нет
В Демагоге Version 7.30.387 "Сохранить как" горячая клавиша Ctrl+Shift+S
► Показать
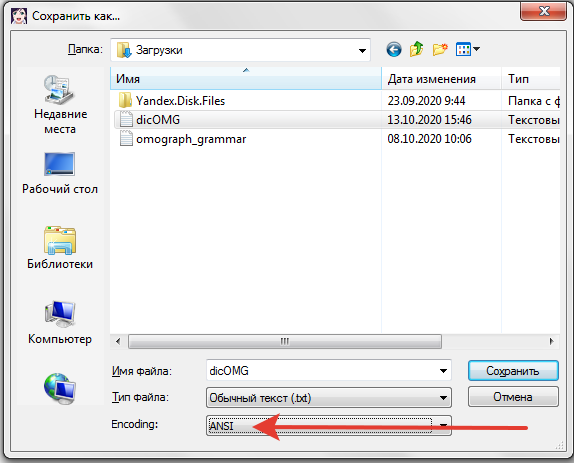
- 2020-10-13_18-25-57.png (55.29 КБ) 5923 просмотра
Yandex TTS
Добавлено: 13 окт 2020 19:12
olelog
Большое спасибо, все получилось с сохранением, но ваш второй вариант скрипта не подошел к моей версии. Работает самый первый вариант.
Yandex TTS
Добавлено: 13 окт 2020 19:15
tonio_k
olelog писал(а): ↑13 окт 2020 19:12
не подошел к моей версии
а в чем проблема обновиться?
Yandex TTS
Добавлено: 21 окт 2020 02:53
chibis
tonio_k писал(а): ↑13 окт 2020 17:41
Попробуйте файл "сохранить как" а где выбирается расширение вроде должно быть поле сохранить в ansi кодировке. Или можно открыть файл dicOMG.txt в блокноте, скопировать текст из окна статистики и вставить поверх содержимого dicOMG.txt и пересохранить
olelog писал(а): ↑13 окт 2020 16:52
и все равно сортировка не такая как у "chibis"
а какая у него сортировка?
Я словарь никак не сортировал, он такой и был в сборке Play_5 2018 года которую я тогда же скачал с этого форума. Уже писал, что надо было использовать более новые сборки, но поскольку та сборка с голосом Еремы полностью устраивала, ничего другого и не искал, пока не зашел на форум, и не узнал про новый голос филипп, но такой сборки, которая бы работала с филиппом без ключей, апи, и т п, не нашел, поэтому и начал переделывать своими силами. В словарь, добавил несколько записей, просто чтобы протестировать как они будут срабатывать. Вставлял записи по алфавиту, но это чтобы удобнее было для себя, для обработчика текста Play_5.hta насколько я понял, не имеет значения алфавитный порядок записей в словаре. Важнее чтобы длинные записи, которые включают в себя более короткие шли первыми, иначе по понятным причинам они не сработают. А вообще для себя, если надо отсортировать какой-нибудь текст, да и вообще для работы с текстом использую редактор нотепад++.
Еще заметил что в предыдущей сборке, когда идет скачивание процессор практически не нагружен, поэтому если обрабатывать на замены текст по частям и сразу отправлять их на яндекс, они будут скачиваться, а следующие части в это время обрабатываться, получается где-то в полтора - два раза быстрей. Поэтому сделал сборку, которая скачивает таким способом
PS. У меня на windows 10, обнаружилась такая особенность - если в папку поместить звуковые файлы, винда автоматически присваивает этой папке тип-"Музыка", и начинает ее постоянно то-ли сканировать для обновления библиотеки мультимедиа, то-ли еще что-то. Но в результате если такую папку активно юзать, то пишутся, читаются, и удаляются файлы в ней с заметной задержкой. Если же в настройках свойств папки, принудительно вместо "Музыка" поставить тип "Общие элементы", то все становится нормально.
Yandex TTS
Добавлено: 21 окт 2020 19:05
speeck
chibis писал(а): ↑21 окт 2020 02:53
В словарь, добавил несколько записей, просто чтобы протестировать как они будут срабатывать. Вставлял записи по алфавиту, но это чтобы удобнее было для себя, для обработчика текста Play_5.hta насколько я понял, не имеет значения алфавитный порядок записей в словаре. Важнее чтобы длинные записи, которые включают в себя более короткие шли первыми
Не пробовали сначала обработать текст словарями в Демагоге, а через Play_5 уже озвучить готовый текст? Есть сборка от
tonio_k, там много словарей задействовано.
Yandex TTS
Добавлено: 22 окт 2020 15:15
olelog
В демагоге ведь словари заточены на голос Максима от Ивоны, а здесь яндекс Филипп. Пусть спецы прольют свет.
Yandex TTS
Добавлено: 22 окт 2020 15:53
tonio_k
olelog писал(а): ↑22 окт 2020 15:15
словари заточены на голос Максима от Ивоны, а здесь яндекс Филипп.
словари из сборки
для Максима заточены под Максима (и пополняются). Словари из сборки
для Яндекса за основу взяты часть универсальных словарей от сборки под Максима(подходят "в целом" для любого голосового движка) остальные словари предоставлены от Васьки специально под Яндекс. В связи с тем, что Филипп по определению ставит ударения лучше чем старые Яндекс голоса к тому же он развивается, то есть вероятность, что словари от старого Яндекса могут иногда что то улучшать, а что то делать хуже. В любом случае словари из сборки для Яндекса и принцип их построения плотностью совместим с Филиппом.
Стоит ли под Филиппа с нуля писать новые словари или использовать старые, внося в них корректировки и добавляя новые правила - определить можно только опытным путём. Надо отзывы пользователей узнавать как Филипп звучит после применения словарей от старых голосов Яндекса?
Yandex TTS
Добавлено: 22 окт 2020 19:21
speeck
На днях я проведу тест Филиппа на разных статьях, со словарями и без, отпишусь о результатах.
Забегая наперед - Яндекс в целом и без словарей читает хорошо, и часто на старых голосах без словарей получалось лучше, ибо словари очень часто меняют ударения на неправильные (например "бЕлка", хотя речь о "белкЕ").
Особо отмечу, что сборка под Яндекс от Васяки крайне сырая и местами безумная, очень много ударений вроде "бизнес*=бИзнес" (в результате чего, получается бИзнесмен"), "булка хлеба стоИт 5 рублей" и тп (последний пример выдуманный, для понимания). Я исправил таких косяков сотни правил, в свое время, но найдены были далеко не все.
Лучше брать сборку под Яндекс от tonio_k.
Также у меня есть своя сборка, основанная на сборке от tonio_k, пожалуй еще более адаптированная под Яндекс (старые голоса), т.к. сборка от tonio_k базируется на Максиме (изначально), у меня исключительно Яндекс.
Там я добавил еще пару тысяч правил, в основном обработку слов с "ция", "це" и тд, которые старые голоса Яндекса в целом плохо произносят. Попробуйте любое составное или выдуманное слово, например "архиузурпация сверхинтеллегенции", станет понятно о чем речь (кстати, Филипп произносит хорошо, но это новый движ).
Могу поделиться своей сборкой, если кому надо.
Yandex TTS
Добавлено: 22 окт 2020 19:49
olelog
Если подойдут под словарь dicOMG в таком виде, постепенно дополняю. И если их получится как то объединить. Под сборкуPlay_5_filipp
Yandex TTS
Добавлено: 22 окт 2020 21:33
speeck
olelog писал(а): ↑22 окт 2020 19:49
dicOMG.txt
А что это за формат словарей? Там сразу по 2 варианта идут, выбираете сами вручную?
Yandex TTS
Добавлено: 22 окт 2020 22:09
skreb
speeck писал(а): ↑22 окт 2020 19:21
Могу поделиться своей сборкой, если кому надо.
Выложите здесь ссылку, пожалуйста, - будет интересно опробовать...
Yandex TTS
Добавлено: 22 окт 2020 22:42
tonio_k
speeck писал(а): ↑22 окт 2020 21:33
Там сразу по 2 варианта идут, выбираете сами вручную?
http://i91650e3.beget.tech/viewtopic.php?t=59&start=450#p4680
Yandex TTS
Добавлено: 23 окт 2020 09:55
speeck
skreb писал(а): ↑22 окт 2020 22:09
Выложите здесь ссылку, пожалуйста, - будет интересно опробовать
Чуть позже сделаю.
Yandex TTS
Добавлено: 23 окт 2020 10:08
speeck
olelog писал(а): ↑22 окт 2020 19:49
Если подойдут под словарь dicOMG в таком виде, постепенно дополняю. И если их получится как то объединить. Под сборкуPlay_5_filipp
Словари dic из сборки Демагога можно сконвертировать под этот формат, если нужно. Но словари rex придется пропустить.
Вообще удобнее готовить книги в Демагоге, и уже готовый текст писать Филиппом. Тем более в сборке от tonio_k есть скрипты, которые пилят большие абзацы в допустимые, делает ли это Play_5_filipp? Бывают абзацы совсем без точек размером с главу и даже книгу, про это речь.
Yandex TTS
Добавлено: 24 окт 2020 20:40
wasyaka
speeck писал(а): ↑22 окт 2020 19:21
Особо отмечу, что сборка под Яндекс от Васяки крайне сырая и местами безумная, очень много ударений вроде "бизнес*=бИзнес"
Хорошо критиковать то что есть, а можно
несуществующую сборку от speeck протестировать и соответствено
потыкать?
И научитесь пользоватся словарями - вначале -
Это для PLAY
бизнесме*=бизнесм+э*
бизнес*=б+изнэс*
для другой проги поменять местами - или нужна спец инструкция...?
теперь новшества
ТОЛЬКО ПОСЛЕ ВАС

,
Yandex TTS
Добавлено: 24 окт 2020 21:50
speeck
Простите, наверное я несколько обидно выразился, но на то есть причины. Мне пришлось переписать
несколько раз свою коллекцию книг из-за некоторых ваших словарей, ибо они критически портили книги. По некоторым ошибкам я вам писал, но вы промолчали, соответственно ошибки не исправили (?), именно поэтому я рекомендовал людям не пользоваться вашей сборкой.
Понимаю, что вы сделали много работы по словарям в целом, за это отдельное
спасибо.
wasyaka писал(а): ↑24 окт 2020 20:40
И научитесь пользоватся словарями - вначале -
Это для PLAY
бизнесме*=бизнесм+э*
бизнес*=б+изнэс*
Этот пример чуть исправляет ситуацию, но не сильно. Русский язык крайне гибкая штука, и есть такие неологизмы, как например: бизнесОвый. Потом, слово "бизнесмен" могут написать разными способами: бизнесмен, бизнесмэн, бизнес-мен и тд. Ваше правило "бизнес*=б+изнэс*" абсолютно не нужное, и даже скорее вредит, тем более Яндекс сам корректно произносит это слово.
wasyaka писал(а): ↑24 окт 2020 20:40
Хорошо критиковать то что есть, а можно несуществующую сборку от speeck протестировать и соответствено потыкать?
На днях я выложу свою сборку, но сперва хочу актуализировать её, обновить в ней Демагог, посмотреть последние скрипты от
tonio_k, все протестировать, и только потом выложить. Обязательно отпишусь вам. С уважением.
Yandex TTS
Добавлено: 25 окт 2020 10:55
Sergshturo
MoppoH писал(а): ↑05 июл 2018 20:20
я вот почти на 100% уверен что была тема где человек выкладывал программу для создания книг с помощью этого движка, сейчас никак не могу найти, хотя сама программа у меня сохранилась, единственный минус яндекс сделал ограничение на 1000 обработок текста в месяц, может кто даст ссылку на ту тему
Кто подскажет что я делаю не так!? ВВожу ключ разроботчика, добавляю книгу в формате TXT, оно думает, потом файл сохраняет в папку audio, но этот файл весит 0 кб, и не открывается в aimp.....или тут нужно подключать какие-то подписки на самом сервисе!?ПОМОГИТЕ ПОЖАЛУЙСТА!!!
Yandex TTS
Добавлено: 25 окт 2020 12:51
tonio_k
Sergshturo писал(а): ↑25 окт 2020 10:55
ВВожу ключ разроботчика, добавляю книгу в
а в какой программе/сборке вы это делаете? Не все умеют работать с ключём разработчика.
Yandex TTS
Добавлено: 25 окт 2020 13:44
Sergshturo
Dmitry писал(а): ↑08 июл 2018 20:37
p,s, прикладываю и для виндовса которую выше Fenix выложил, но у меня версия свежее
из правок
YandexTTSnew.rar
(1.07 МБ) 2607 скачиваний
Обновление Yandex-многоголоски:
- исправлены обнаруженные ошибки;
- добавлены правила распознавания диалогов.
tonio_k писал(а): ↑25 окт 2020 12:51
Sergshturo писал(а): ↑25 окт 2020 10:55
ВВожу ключ разроботчика, добавляю книгу в
а в какой программе/сборке вы это делаете? Не все умеют работать с ключём разработчика.
вот эта сборка (YandexTTSnew.rar) скачал в самом начале ветки,4 коммент от этого пользователя (#4Сообщение Dmitry )
Yandex TTS
Добавлено: 25 окт 2020 13:46
Sergshturo
tonio_k писал(а): ↑25 окт 2020 12:51
Sergshturo писал(а): ↑25 окт 2020 10:55
ВВожу ключ разроботчика, добавляю книгу в
а в какой программе/сборке вы это делаете? Не все умеют работать с ключём разработчика.
4 коммент в начале ветки от Dmitry, его сборка
Yandex TTS
Добавлено: 25 окт 2020 14:20
tonio_k
Sergshturo писал(а): ↑25 окт 2020 13:46
4 коммент в начале ветки от Dmitry, его сборка
каждое сообщение на форуме имеет номер через хештег например #526, одновременно это ещё и ссылка на это сообщение. Так что если ссылаетесь, то делайте ссылку на сообщение. Не думаю, что кто то захочет искать сообщения только по вырезке в тексте
Yandex TTS
Добавлено: 25 окт 2020 17:07
krys4d
Здравствуйте, можете уменьшить количество символов для выделения в этом скрипте?
tonio_k писал(а): ↑16 сен 2020 17:11
Скрипт ОКНО - БЛОКИ В БУФЕР ОБМЕНА.lua
На демостранице яндекса, как и написано, максимальное количество для синтеза - 5000 символов, но вот для скачки получившегося файла максимальное количество символов - 2172 символа.
В скрипте количество символов для выделения - 2450, и из-за этого получается, что текст, количество символов которого составляет 2173-2450 просто выпадает из скачки.
Если можно, то лучше вообще до 2000 символов сократить.
Yandex TTS
Добавлено: 25 окт 2020 17:34
tonio_k
krys4d писал(а): ↑25 окт 2020 17:07
файла максимальное количество символов - 2172 символа.
Сделал 2170 - "на всякий случай"
но вы можете в скрипте сами вручную поправить переменную
simbol:
Yandex TTS
Добавлено: 27 окт 2020 23:17
chibis
Я тут подумал собрать на форуме несколько словарей какие найду и добавить записи из них в файл dicOMG.txt, а то он что-то маленький. Честно говоря раньше когда слушал книги, не обращал внимание на неправильные ударения, но теперь почитал форум и тоже стал их замечать. Но чем больше будет словарь, тем дольше создается книга, и если добавить несколько сотен тысяч записей то на одну книгу может уйти час, а то и больше. В Play5.hta поиск в тексте замен из словаря, сделан с помощью регурярок, поэтому даже по короткому словарю обрабатывается несколько минут. В качестве эксперимента, вместо регулярок сделал просто поиск и замену по типу str_replace(), и так работает в десятки раз быстрее и заменяет ровно те же слова, что и по регуляркам. Проверил на нескольких книгах, разницы в заменах нет никакой, зато при моих 30 Mbit/s, и имеющемся у меня на данный момент коротком словаре из двадцати трех тысяч записей который был с программой, на среднюю книгу, вместе со скачиванием уходит меньше двух минут. Вот сборка в таком варианте
. Еще есть мысль для быстрого поиска и замены использовать ресурсы видеокарты, но это хорошо бы найти словарь от миллиона записей.
Yandex TTS
Добавлено: 28 окт 2020 02:57
tonio_k
chibis писал(а): ↑27 окт 2020 23:17
хорошо бы найти словарь от миллиона записей.
надо же как совпало, буквально сегодня в руки мне как раз такой попался. Целый день с ним борюсь - слишком большой под 300 Мб. В Демагоге в окно такое не загрузить - не расчитан. Но как словарь Демагог его проглатывает и применяет к книге без проблем. Результат похож как на
сайте . Так что приходится к правилам в словаре через скрипты к тексту добираться - очищать от мусора и дубликатов. Осталось омографы из него удалить. Поставил скрипт на удаление омографов и спать пошёл. Должен получится словарь вставки ударений примерно на 2,9 млн правил. Постараюсь завтра закончить и выложить.
Yandex TTS
Добавлено: 28 окт 2020 09:31
chibis
Что-то не нашел кнопку, для редактирования сообщений. Я в своем предыдущем сообщении, перепутал и выложил сборку не с той качалкой, там могут быть ошибки с кодировкой utf-8, к тому же как я понял из предыдущего сообщения tonio_k, большой словарь может появится гораздо раньше чем я думал, так что лучше потом выложу вариант с правильной кодировкой и новым словарем, а предыдущий надо удалить.
Yandex TTS
Добавлено: 28 окт 2020 19:06
tonio_k
chibis писал(а): ↑28 окт 2020 09:31
большой словарь может появится гораздо раньше чем я думал
похоже, я не успею сегодня его доделать, поэтому скину его черновик вам в личку. Для тестирования нагрузок чернового варианта, думаю, достаточно будет.
Yandex TTS
Добавлено: 30 окт 2020 09:42
Nxtpr
chibis, Если уж продолжаете развивать - было б неплохо и Алену задействовать.
Yandex TTS
Добавлено: 30 окт 2020 21:13
chibis
Nxtpr писал(а): ↑30 окт 2020 09:42
chibis, Если уж продолжаете развивать - было б неплохо и Алену задействовать.
Задействовать в смысле для озвучки книжных диалогов по мужским и женским ролям? Или просто чтоб можно было выбирать голос Алены для озвучки книги целиком? Если первое, то это я не знаю как сделать. Для этого надо использовать оригинальную авторскую сборку Play_5, с мужскими и женскими голосами от предыдущей демо-страницы. Если имеется ввиду второе, то это наоборот очень просто, надо только прилепить еще один выпадающий список в форму, для выбора голоса, сама программа параметр голоса принимает.
Yandex TTS
Добавлено: 30 окт 2020 22:34
Piligrim
Или просто чтоб можно было выбирать голос Алены для озвучки книги целиком?
Да, второй вариант желательно бы, с возможностью выбора Алёны, или Филиппа. Странно звучит, когда весь текст от женского имени читается мужским голосом.
Как обстоят дела с подключением объёмного словаря от tonio_k?
Yandex TTS
Добавлено: 31 окт 2020 00:09
chibis
Piligrim писал(а): ↑30 окт 2020 22:34
Да, второй вариант желательно бы, с возможностью выбора Алёны, или Филиппа. Странно звучит, когда весь текст от женского имени читается мужским голосом.
Добавил выпадающий список для выбора голоса.
Piligrim писал(а): ↑30 окт 2020 22:34
Как обстоят дела с подключением объёмного словаря от tonio_k?
Он использовался для проверки времени обработки большим словарем. Представляет из себя орфоэпический словарь русского языка, с почти тремя миллионами слов в разных падежах и формах. Если его использовать для замен в этой конкретной сборке, то ударения-плюсики просто проставляются во всех словах которые есть в книге. Поэтому я думаю его надо использовать не непосредственно для замен, а для формирования большого словаря который в свою очередь уже будет использоваться непосредственно для замен.
Yandex TTS
Добавлено: 31 окт 2020 07:30
Piligrim
chibis писал(а): ↑31 окт 2020 00:09
Добавил выпадающий список для выбора голоса.
yndx_tts.zip (26.9 МБ)
...для формирования большого словаря который в свою очередь уже будет использоваться непосредственно для замен.
Скачал эту сборку. Да, теперь
гораздо лучше!
Подождём большой словарь.
Yandex TTS
Добавлено: 31 окт 2020 11:07
tonio_k
Yandex TTS
Добавлено: 31 окт 2020 19:46
skreb
Ув.
chibis, а эта сборка работает только на Windows 10? У меня Windows 8.1, при нажатии на кнопку "Начать озвучку" появляется такое окно (Ошибка сценария):
► Показать
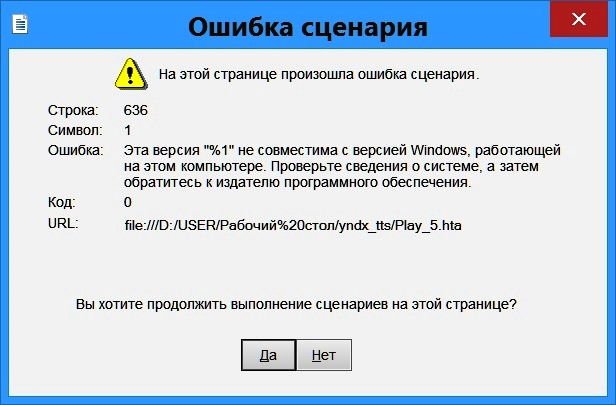
- 1.jpg (46.19 КБ) 4509 просмотров
Yandex TTS
Добавлено: 31 окт 2020 21:03
chibis
Должно работать на любой 64-битной windows. Если в сведениях о системе написано 64 бит, то попробуйте запустить yndxfilipp.exe в папке sys вручную(лучше из терминала), винда должна написать почему не может запустить, может длл, какой нибудь не хватает.
Yandex TTS
Добавлено: 31 окт 2020 22:51
skreb
chibis писал(а): ↑31 окт 2020 21:03
Должно работать на любой 64-битной windows...
Спасибо! Теперь всё понятно. У меня установлена 32-разрядная ОС. На ней никак не получится? Нужно переходить на 64-ю систему? При ручном запуске
yndxfilipp.exe пишет:
► Показать

- 1.JPG (14.04 КБ) 4509 просмотров
Yandex TTS
Добавлено: 01 ноя 2020 08:56
Piligrim
Благодарю Вас за словарь! Но...
В словаре 2918412 словесных пар. Я добавил их в словарь в папке Lexicon (заменив = на ^) последней сборки, попробовал так озвучить небольшой текст и... ничего не получилось. Вернулся к прежнему словарю (добавив тысячу словесных пар из Вашего словаря). Обработка текста словарём
значительно замедлилась. Т.е. нужно искать компромисс с таким большим объёмом словаря и скоростью обработки текста. Но возникает вопрос - нужно ли это делать? VIP голоса Филипп и Алёна прекрасно справляются с ударениями, лишь иногда ошибаясь в омонимах.
Вопрос к chibis: что посоветуете делать? И ещё замечание. При озвучке Алёной скорость произношения слишком большая. Нельзя ли уменьшить её до значения 0,8 (или как-то программно регулировать скорость из Вашей замечательной сборки)?
Yandex TTS
Добавлено: 01 ноя 2020 10:39
tonio_k
Piligrim писал(а): ↑01 ноя 2020 08:56
и... ничего не получилось.
о практической полезности словаря ничего сказать не могу. Но если очень хочется послушать есть ли разница, то для эксперимента, попробуйте этот большой словарь
предварительно применить к тексту книги в Демагоге с включенной в настройках галочкой "хешировать словари". И вы быстро получите книгу с проставленными ударениями. Ну а дальше полученную книгу отправляете на озвучку.
Если этот способ себя зарекомендует, то, будет логичным начать применять "поиск новых слов" когда ещё до озвучки выводится список слов которых нет ни в словаре и на сайте расстановки ударений. И этот список отдельно прослушать. Если есть с неверными ударениями- занести из в словарь, если читаются верно- занести в словарь исключений.
Yandex TTS
Добавлено: 01 ноя 2020 12:06
chibis
skreb писал(а): ↑31 окт 2020 22:51
У меня установлена 32-разрядная ОС. На ней никак не получится?
Отправил в личку 32-битные версии библиотек и ffmpeg, но работоспособность проверил на 64 битной винде, 32-битной у меня нету.
Yandex TTS
Добавлено: 01 ноя 2020 12:59
chibis
Piligrim писал(а): ↑01 ноя 2020 08:56
В словаре 2918412 словесных пар. Я добавил их в словарь в папке Lexicon (заменив = на ^) последней сборки, попробовал так озвучить небольшой текст и... ничего не получилось. Вернулся к прежнему словарю (добавив тысячу словесных пар из Вашего словаря). Обработка текста словарём значительно замедлилась. Т.е. нужно искать компромисс с таким большим объёмом словаря и скоростью обработки текста. Но возникает вопрос - нужно ли это делать? VIP голоса Филипп и Алёна прекрасно справляются с ударениями, лишь иногда ошибаясь в омонимах.
Вопрос к chibis: что посоветуете делать? И ещё замечание. При озвучке Алёной скорость произношения слишком большая.
С словаре надо помимо "=" на "^" поменять большие буквы, на маленькие с плюсиком перед ними. Я после такой замены как раз этим словарем проверял время обработки. Операции замены и скачивания в сборке идут одновременно - время менее длительной операции поглощается временем более длительной. Создание книги из 91-ой части(около 9 часов звучания), заняло четыре с половиной минуты, но я ставил 4 потока обработки текста(проверял на 4-ядерном процессоре). Это при обработке полным, почти трехмиллионным словарем, добавление тысячи записей не должно сколь-нибудь заметно увеличивать время, это надо смотреть формат этих записей. Я собственно из-за этого и хочу насобирать словарь побольше, чтобы процессор не простаивал во время скачивания. Тот словарь который достался от Play_5, содержит чуть больше 23 тысяч записей, применяется за несколько секунд и следующие три минуты 4 ядра простаивают, пока яндекс отдает файлы. А был бы большой словарь их было бы чем занять на все время пока идет скачивание. Поэтому компромисс для меня словарь такой длины, чтобы время обработки книги по нему, занимало примерно такое же время которое требуется на скачивание этой же книги, то есть приблизительно 3-5 минут. Более быстро смысла нет, потому что создать книгу быстрей чем яндекс отдаст файлы все равно не получится и проц(тем более видеокарта) будет простаивать. А на пару минут медленнее в принципе можно, но не больше. Если больше то это уже получается предварительная обработка текста, а не конвейерная на лету в процессе скачивания. Для этого есть другие сборки с кучей словарей, специально созданные для предварительной обработки. Чтобы сделать время обработки наиболее близким ко времени скачивания на машинах с разным железом, и разной скоростью интернета, заранее сделал возможность выбора количества потоков скачивания и количества потоков обработки.
По поводу скорости Алены - яндекс может озвучивать по-моему с тремя разными скоростями и с тремя настроениями-интонациями. В принципе можно для выбора прилепить еще выпадающих списков на форму.
Yandex TTS
Добавлено: 01 ноя 2020 17:05
Piligrim
chibis писал(а): ↑01 ноя 2020 12:59
С словаре надо помимо "=" на "^" поменять большие буквы, на маленькие с плюсиком перед ними.
...В принципе можно для выбора прилепить еще выпадающих списков на форму.
Спасибо. Последовал Вашему совету, заменил большие буквы на маленькие с плюсиками перед ними И ВСЁ ЗАРАБОТАЛО!!! Замечательно. Я пользуюсь нейтральной, повествовательной интонацией, но может быть кому-то нужны и остальные, но вот скорость для Алёны явно нужно замедлять. Поэтому буду рад, если в следующей Вашей сборке появятся дополнительные списки на форму (и расширенный словарь). Заранее благодарю.
Yandex TTS
Добавлено: 02 ноя 2020 09:17
Piligrim
tonio_k писал(а): ↑01 ноя 2020 10:39
если очень хочется послушать есть ли разница, то для эксперимента, попробуйте этот большой словарь предварительно применить к тексту книги в Демагоге с включенной в настройках галочкой "хешировать словари". И вы быстро получите книгу с проставленными ударениями. Ну а дальше полученную книгу отправляете на озвучку.
Если этот способ себя зарекомендует, то, будет логичным начать применять "поиск новых слов" когда ещё до озвучки выводится список слов которых нет ни в словаре и на сайте расстановки ударений. И этот список отдельно прослушать. Если есть с неверными ударениями- занести из в словарь, если читаются верно- занести в словарь исключений.
Благодарю.
Вопрос: Где в настройках Демагога имеется пункты "хешировать словари" и "поиск новых слов"?
Yandex TTS
Добавлено: 02 ноя 2020 11:42
skreb
Ув. tonio_k, нельзя ли вставить в вашу сборку "Демагог+Yandex TTS" скрипт для голоса Филипп, или сделать отдельную сборку на базе "Демагог+Yandex TTS" для этого голоса? Спасибо!
Yandex TTS
Добавлено: 02 ноя 2020 11:55
tonio_k
skreb писал(а): ↑02 ноя 2020 11:42
отдельную сборку на базе "Демагог+Yandex TTS" для этого голоса?
только если ув.
chibis переделает свое продолжение так, что бы при запуске его приложения (без всяких кликов мыши и клавиатуры) все txt-файлы из постоянной папки автоматом сразу отправлялись на озвучку Филиппом.