Страница 1 из 1
Новости
Добавлено: 01 мар 2019 11:04
good_cat
В рамках проекта Common Voice Mozilla выпустила открытый датасет из записей человеческой речи на 18 языках, в том числе на немецком, французском, китайском и испанском. Общая длительность записей превышает 1300 часов. Компания планирует использовать набор данных в своих движках и предоставляет его всем желающим.
https://voice.mozilla.org/en/datasets
Новости
Добавлено: 01 мар 2019 11:27
tonio_k
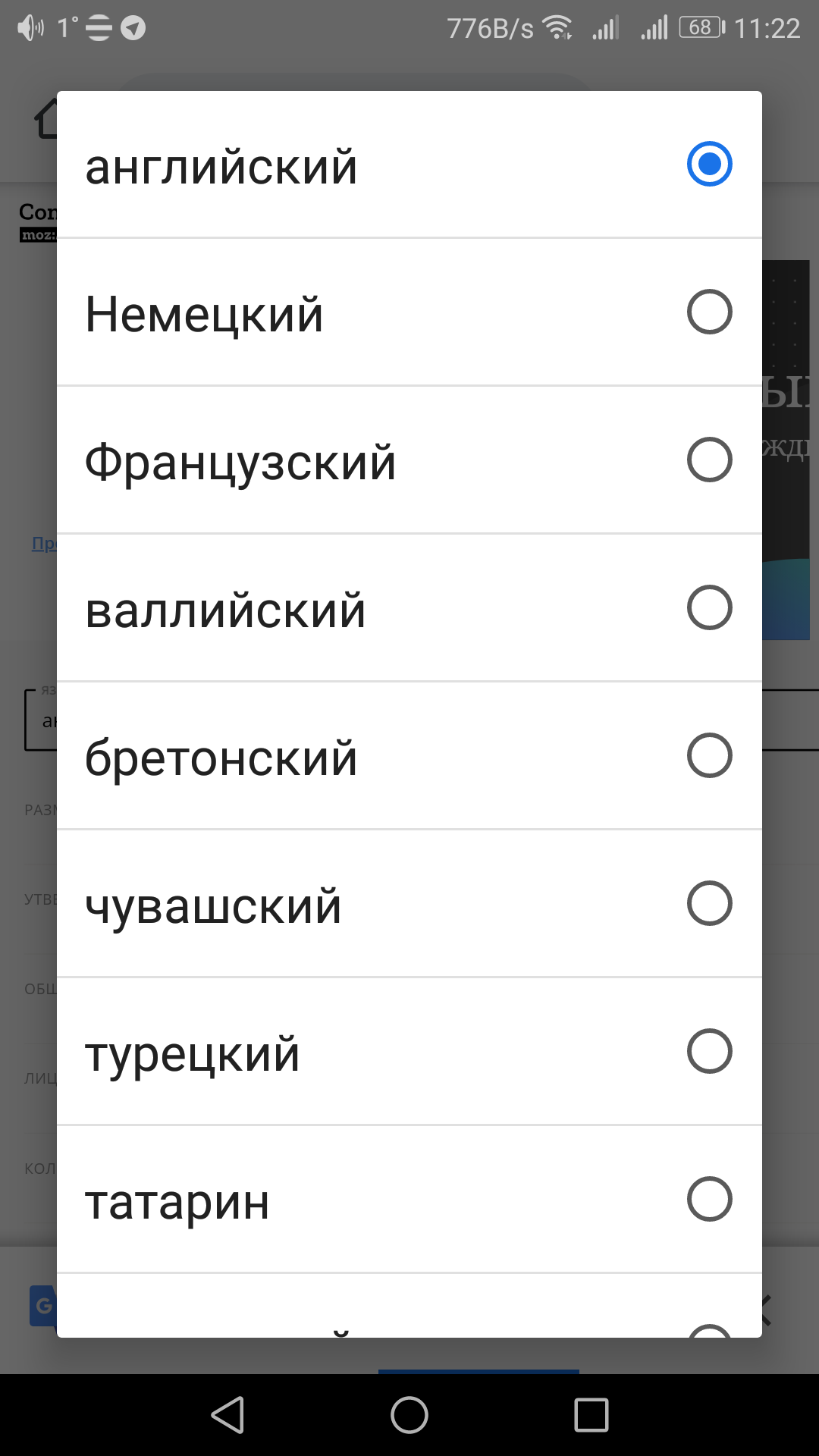
Что восхитило, так это при выборе языка нет русского, зато есть чувашский!

► Показать
- Screenshot_20190301-112228.png (156.5 КБ) 22680 просмотров
Вот даже не знаю что это значит и какова история такого решения

Новости
Добавлено: 01 мар 2019 13:14
good_cat
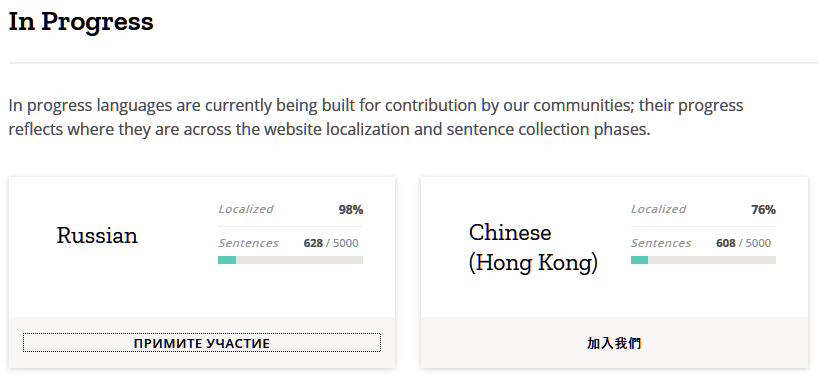
Русский язык тоже планируется... позже.
► Показать
- RusLang.png (31.94 КБ) 22667 просмотров
Новости
Добавлено: 01 мар 2019 17:04
Lecron
Интересно, когда программа сама сможет готовить себе датасет? Указываем папку аудиокниги, указываем ее текстовый файл, жмем кнопку "Создать голос", а программа сама, по анализу пауз и темпа навязываемого знаками препинания, привязывает одно к другому и формирует датасет. И вот мы, промозглым весенним вечером, сидя у камина с бокалом пунша в руке, слушаем книгу, озвученную голосом известного исторического персонажа или любимого артиста.
Да, я знаю, что новость про наборы для тренировки распознавания, но мечтать-то не вредно.
Отправлено спустя 16 часов 40 минут 13 секунд:
Понравились комменты на
opennet.
Что не так с речью в Мозилле
► Показать
Common Voice:
1) собираются голоса молодых людей мужского пола 20-30 лет, нет женских, детских, нет голосов старшего возраста.
2) тексты для записи ограничены тысячей предложений, нет вариативности словаря, в дальнейшем будут трудности со словами.
3) записи распространяются в mp3, что вносит искажения в голосовой сигнал. Оригиналы не дают, видимо, не хотят конкуренции.
4) традиционно вместо того, чтобы развивать существующий проект (voxforge) запилили свой.
5) проверка записей делается вручную, хотя может делаться автоматическими средствами.
6) сейчас таких данных можно просто накачать с youtube за пару часов в 10 раз больше, чем они собрали за год для всех языков.
DeepSpeech
1) взяли чужую технологию от Baidu
2) за пару лет ничего не сделали, даже не добились нормальной точности, точность гораздо хуже передовых результатов.
3) зато кричат о себе на всех углах, получили европейский грант
4) когда стало поджимать, скопировали втихушку чужую библиотеку libctcdecode, не упомянув автора, выкинув весь свой предыдущий код
5) декодер всё ещё требует 4гб памяти, работает очень медленно
7) в коммитах бесконечно переделывают справку и конфигурационные файлы, ни одного реального улучшения. ну ещё обертки для языков пишут
8) модели не может натренировать простой любитель, нужен суперкомпьютер с 8 GPU
В итоге этот проект недалеко ушёл от предыдущего (мобильной ОС)
Ну и по синтезу (mozilla/TTS)
► Показать
1) Опять скопировали чужой проект на github, назвали своим. Автору пришлось напоминать
https://github.com/mozilla/TTS/issues/2
2) Куча хороших проектов на тему существует, до сих пор пилят "своё". Потихоньку копируют, что другие сделали, например, Tacotron2 внесли (скопировали) только сегодня, сходимость моделей была никакая.
3) Wavenet так и не добавили.
Новости
Добавлено: 02 дек 2020 11:13
Lecron
Развитие TTS технологий вне проприетарных сервисов, таки продолжается.
Open Source синтез речи SOVA / Хабр.
В комментариях утверждается, что качество даже получше Google TTS. Шанс на появление современных десктопных движков еще немного вырос.