Страница 8 из 10
Балаболка TTS
Добавлено: 19 апр 2020 14:47
wasyaka
Трёп дело расслабляющее, но
Посуществу
► Показать
РУСАКОВ ПАВЕЛ КОНСТАНТИНОВИЧ, ВИЦЕ СЕКРЕТАРЬ…
ВЕРХОВНОГО СОВЕТА, СОВЕТНИК ПРЕЗИДЕНТА РУСИИ…
ПО НАЦИОНАЛЬНЫМ ПРОЕКТАМ И МИГРАЦИОННОЙ…
ПОЛИТИКЕ.
В
ПРАВКА :добавить: если более двух слов капслоком >> перевести в нижний регистр?
В
найти Имена:
показать одноразовые (без склонения) имена? их может быть огого как - ну без разницы как будет звучать имя
буабУбу или
буабубУ 
зачем прослушивать?
Соответственно добавил в список прослушанных и ОК

Балаболка TTS
Добавлено: 19 апр 2020 15:13
Lecron
wasyaka, Причем тут я? Чего вы вцепляетесь в приведенный пример? Это только один из возможных вариантов. Когда шаблонные правила могут конфликтовать с отображенными и прослушанными именами, которые по причине корректного воспроизведения движком в словарь не заносятся.
Речь идет только о том, нужно ли такие словоформы отображать в списке или считать что внесенные шаблоны заведомо корректны.
wasyaka писал(а): ↑19 апр 2020 13:56
Откажитесь от безграмотного применения ЗВЁЗД и всё наладится
Полностью согласен. От безграмотного надо отказаться :)
wasyaka писал(а): ↑19 апр 2020 13:56
Слова, которые начинаются на "артем"
А вот
грамотное позволит упростить подготовку в разы. Если программа позволит. Вы что-то мало нашли, только Артемов* позволит обработать 25+ словоформ отчеств и прочего.
► Показать
Артёмов
Артёмова
Артёмове
Артёмовен
Артёмович
Артёмовича
Артёмовичам
Артёмовичами
Артёмовичах
Артёмовиче
Артёмовичей
Артёмовичем
Артёмовичи
Артёмовичу
Артёмовна
Артёмовнам
Артёмовнами
Артёмовнах
Артёмовне
Артёмовной
Артёмовну
Артёмовны
Артёмовой
Артёмову
Артёмовым
Так может оставите выбор стратегии за пользователем?
Балаболка TTS
Добавлено: 21 апр 2020 22:07
Kei
Я уже писал по сходному вопросу, но DarkMetro снова выглядит не слишком хорошо. Хоть сейчас и не критично.
Балаболка TTS
Добавлено: 22 апр 2020 04:39
balabolka
Kei
Спасибо за сообщение. Программный компонент для "шкурок" (тем оформления) конфликтует с компонентом для поддержки программ экранного доступа. В этом окне программы ошибку можно поправить; попробую сделать необходимые изменения в следующей версии. В других окнах "Балаболки" проблема с этой "шкуркой" останется.
К счастью, проблема не настолько серьезная: "шкурка" DarkMetro отображается неверно только тогда, когда она только что выбрана из списка доступных тем оформления (проверял на Windows 7). При повторном запуске программы всё будет в порядке.
"Шкурки" нужны зрячим пользователям "Балаболки", а поддержка программ экранного доступа требуется слабовидящим пользователям. Выяснилось, что эти два программных компонента конфликтуют друг с другом. Но и отказаться от их использования сейчас не могу.
Балаболка TTS
Добавлено: 03 май 2020 21:41
tonio_k
Знак решётка (#) в начале правила в Демагоге означает закомментированную строку. Я не знаю, является ли это стандартом словаря dic и для Балаболки, но если является, то При импорте словаря из dic в bxd такие правила загружаются как есть с решеткой в начале правила. Понятно, что такие правила не сработают в силу того, что текст удовлетворяющий такому правилу варят ли встретится на практике, но может при импорте словаря такие правила автоматом делать с пометкой "активный -Нет"? С удалением знака решётка
Балаболка TTS
Добавлено: 03 май 2020 23:09
ilog
Пробуя последнюю сборку "все включено" Балаболки, сделанную
tonio_k со словарями из Демагога, заметил вот такое:
Открываем обработанный скриптами из Демагога файл, в котором проставлены ударения (заглавной буквой). Замечаем неправильное ударение, редактируем, сохраняем, пускаем чтение. В некоторых случаях (по-видимому при отсутствии вариаций слова в словаре) по-прежнему слышим неправильное ударение.
Пример
стрЯпая фальшивку
Вопрос - почему проставленное ударение игнорируется? Или это проблемы у меня в настройках?
Балаболка TTS
Добавлено: 03 май 2020 23:23
balabolka
tonio_k писал(а): ↑03 май 2020 21:41
При импорте словаря из dic в bxd такие правила загружаются как есть с решеткой в начале правила.
Да, это мое упущение. Исправлю в следующей версии. Спасибо.
Балаболка TTS
Добавлено: 03 май 2020 23:37
tonio_k
ilog писал(а): ↑03 май 2020 23:09
Пробуя последнюю сборку "все включено" Балаболки, сделанную tonio_k со словарями из Демагога, заметил вот такое:
вопросы по сборке лучше задавайте на ветке сборки. Это проблема последовательности применения словарей, а не самой программы Балаболки. Так что вопрос к составителю словаря, а не к разработчику программы. Если проблема в ударении, то (на ветке сборки) задайте вопрос с примером текста в котором надо поменять удаление, в каком словаре вы пытались сделать изменения и какое именно. А там уже я подскажу где и как и на что обратить внимание.
Балаболка TTS
Добавлено: 20 май 2020 12:02
levm
Не находится объяснение, каков должен быть результат действия команды "Использовать по умолчанию" в контекстном меню словарей на панели словарей. Назначить какое-то предпочтение словарю, расположенному ниже по списку? Или нескольким словарям? Что-то другое? Для чего?
Балаболка TTS
Добавлено: 20 май 2020 17:16
wasyaka
Настройки >> Импорт текста >> Извлечение текста из файлов >> Добавить сноски и примечания внутрь текста (для форматов DOCX, FB2, FB3, MD и ODT)
А формат EPUB добавить возможно?
Балаболка TTS
Добавлено: 20 май 2020 18:04
balabolka
wasyaka писал(а): ↑20 май 2020 17:16
А формат EPUB добавить возможно?
Нет, сейчас это не представляется возможным.
Хотя спецификация для формата EPUB предусматривает специальные атрибуты для сносок и примечаний, многие программы для создания и редактирования книг в этом формате игнорируют такие возможности. Сноски оформляются как обычные гиперссылки; и зачастую эти ссылки реализуются как попало. Например, вместо того, чтобы конкретная сноска указывала на конкретное примечание в конце книги, эта сноска/ссылка указывает на всю страницу примечаний для главы книги (а на этой странице может быть несколько десятков примечаний).
Еще раз подчеркну: у такой сноски нет никаких признаков того, что это сноска. Выглядит она как обычная ссылка (разве что, текст сноски представляет собой число или "звездочку"). Пока не готов реализовать обработку таких ссылок; но держу эту идею в своей голове.
Балаболка TTS
Добавлено: 21 май 2020 17:14
balabolka
wasyaka
Есть разные программы для создания книг в формате EPUB. Одной из таких популярных программ является
calibre: она умеет автоматически преобразовывать файлы из одного формата в другой. Вот как раз для EPUB-файлов, созданных этой программой, можно осуществить вставку сносок и примечаний внутрь текста. Попробую добавить такую возможность в следующую версию "Балаболки". Это не полнофункциональное решение, но лучше, чем ничего.
Спасибо, что обратили мое внимание на эту опцию.
Балаболка TTS
Добавлено: 18 июн 2020 09:11
Lecron
Еще одно пожелание — логирование. Вести лог (включаемый в настройках) по процедурам применения словарей. Также возможно для поиска имен. Дата, найденная последовательность, словарь, применяемое правило и возможно результат.
Думаю проблема из соседней темы, логом решилась бы на раз-два. Для меня еще польза. Кажется что 20% словаря обеспечивают даже не 80% результата, а все 99%. Слушаю много, готовлю пакетно, через год-другой сбора логов, можно в разы почистить словари. Думаю еще полезных применений надется.
Балаболка TTS
Добавлено: 19 июн 2020 11:12
balabolka
Lecron писал(а): ↑18 июн 2020 09:11
Вести лог (включаемый в настройках) по процедурам применения словарей.
Идея понятна, но реализовать ее в полном объеме затруднительно. Этот лог может быть необъятного размера:
- на этом форуме можно найти словари размером в десятки мегабайт;
- пользователи преобразуют в звуковые файлы множество текстов, в пакетном режиме.
За одни сутки работы программы можно получить лог-файл размером в несколько гигабайт.
Согласен, что подобный инструмент нужен, некая разновидность логирования. Пока всё, что могу предложить, - пункт главного меню
Статистика замен. Показывает, какие правила были применены к текущему тексту, сколько раз, за какое время.
Балаболка TTS
Добавлено: 19 июн 2020 13:13
Lecron
balabolka писал(а): ↑19 июн 2020 11:12
Этот лог может быть необъятного размера:
на этом форуме можно найти словари размером в десятки мегабайт;
От размера словаря зависит крайне опосредовано. Конечно больше правил, больше замен, больше лог. Но повторю, 20% словаря может давать 99% замен. Остальное тупо висит, фактически одноразовое.
balabolka писал(а): ↑19 июн 2020 11:12
За одни сутки работы программы можно получить лог-файл размером в несколько гигабайт.
С одной стороны, гигабайты не критичны. Кому надо, пожертвуют. Кому нет — ну так и суда нет, лог отключен. При решении же одиночных проблем, много никогда :) не будет.
С другой, Откуда гигабайты?
Сколько в среднем замен на книгу? Случайно взятая на 630кБ в 1251 кодировке, показала 4800 замен или с небольшим запасом 8000 на мегабайт исходника. Чтобы
сравняться с исходником по размеру, запись лога должна составлять 131 байт. 8 на дату, большая точность не нужна. Средний размер правила, в моем основном словаре 781244 байт / 23741 правило = 33 байта. Чуть больше от половины правила, в среднем займет найденная последовательность — 20 байт. Имеем резерв 70 байт. Больше чем уже израсходовали. :)
Какая бы ни была пакетная обработка, пусть за год 1000 книг, лог для них не превысит 1 гигабайта. Ну пусть вдвое больше — 2 гигабайта. Проблема?
Балаболка TTS
Добавлено: 19 июн 2020 13:15
speeck
balabolka писал(а): ↑19 июн 2020 11:12
Этот лог может быть необъятного размера:
на этом форуме можно найти словари размером в десятки мегабайт;
пользователи преобразуют в звуковые файлы множество текстов, в пакетном режиме.
Поддерживаю насчет необходимости логирования правил, ибо ошибок в словарях "знак бесконечности....". А насчет гиговых логов, это проблемы "пакетчиков", у них наверное и с местом на жестком диске возникают трудности, но причем здесь обычный средний потребитель? )
Балаболка TTS
Добавлено: 19 июн 2020 13:41
Lecron
А еще, повторно попрошу сделать такую настройку.
- Снимок_.png (3.18 КБ) 9489 просмотров
Набросал черновой скрипт, группирующий словарь. Он превратил
► Показать
Код: Выделить всё
Александре=Алекса`ндре
Александрии=Александри`и
Александрия=Александри`я
Александров=Алекса`ндров
Александрова=Алекса`ндрова
Александрове=Алекса`ндрове
Александрович=Алекса`ндрович
Александровича=Алекса`ндровича
Александровичем=Алекса`ндровичем
Александровичу=Алекса`ндровичу
Александровка=Алекса`ндровка
Александровна=Алекса`ндровна
Александровне=Алекса`ндровне
Александровну=Алекса`ндровну
Александровны=Алекса`ндровны
Александровой=Алекса`ндровой
Александровский=Алекса`ндровский
Александровского=Алекса`ндровского
Александровской=Алекса`ндровской
Александровском=Алекса`ндровском
Александровскую=Алекса`ндровскую
Александровым=Алекса`ндровым
в
Код: Выделить всё
Александре=Алекса`ндре
Александри*=Александри`*
Александро*=Алекса`ндро*
Дело даже не в сокращении словаря, наверняка шаблоны кушают больше ресурсов. Дело в ошибках произношения. Если шаблонизировать только при большом начальном фрагменте (ограничил минимум 8 символами), попасть на них очень сложно. А вот исправлений, для отсутствующих в первом списке правил, будет намного больше. Даже для указанного еще много незатронутых словоформ, а ведь бывают более значимые случаи, когда в словарь внесено 2-3 правила, а еще 23 пропущены из-за отсутствия в данной книге или не преодолевши порог по количеству вхождений в книгу при прослушивании.
И даже это не главное. Подключен стандартный (?) словарь ёфикации, в котором куча правил прописана шаблонами
Код: Выделить всё
аксенов*=аксёнов*
алферов*=алфёров*
артемов*=артёмов*
Все эти словоформы, приходится повторно прослушивать, уже нехорошо, и тадам.... по одному повторно заносить в основной словарь. Аналогично со "стандартным" словарем для голоса, в котором тоже хватает шаблонов. Все это дублируется. Зачем?
Не прошу делать неотключаемой. Уже есть опция "Не показывать из словарей", чем помешает еще одна?
Балаболка TTS
Добавлено: 20 июн 2020 00:33
balabolka
Логирование - нет, остаюсь при своем мнении: если писать в лог-файл информацию о всех заменах, это приведет к серьезным проблемам. Вы даже не представляете, словари каких размеров используют пользователи и какие объемы текста регулярно преобразуются в звуковые файлы. Это, скорее, не "
случайно взятая книга в 630 Кб", а намеренно взятый список романов размером в 100-200 мегабайт.
Кроме того, логирование замедлит работу программу. А еще несколько экземпляров программы могут работать одновременно и писать данные в один лог-файл. А потом надо будет создать инструмент для анализа лог-файлов, с графиками, таблицами и экспортом в Excel. В общем, не готов разбираться со всем этим (особенно, если сам не уверен в необходимости подобной опции).
Еще раз рекомендую обратить внимание на пункт главного меню
Статистика замен: это не лог-файл, но в этом окне достаточно полезной информации по применению правил к текущему тексту. Подумаю над тем, можно ли добавить для каждого правила показ предложений из текста, в которых были выполнены замены; пока не уверен, что это необходимая функция.
Lecron писал(а): ↑19 июн 2020 13:41
А еще, повторно попрошу сделать такую настройку.
Хорошо, добавляю такую "галочку". Реализовать ее несложно, но это приведет к замедлению формирования списка найденных имен (так как здесь проверяется не точное совпадения слова и шаблона правила, а частичное). Впрочем, задержка будет небольшой; и если "галочка" не проставлена, в работе программы ничего не изменится.
Но мои предостережения остаются в силе. Если, например, словарь содержит такое правило (видел в одном из словарей на своем компьютере):
все имена, начинающиеся на букву "А", не будут отображаться в списке. То есть, словарь должен быть не абы какой, а специально подготовленный, - как в Вашем примере с именами, отчествами и фамилиями.
Балаболка TTS
Добавлено: 20 июн 2020 10:49
Lecron
balabolka писал(а): ↑20 июн 2020 00:33
Это, скорее, не "случайно взятая книга в 630 Кб", а намеренно взятый список романов размером в 100-200 мегабайт.
Если человеку лог нужен, он его включит, несмотря на. Но
"если "галочка" не проставлена, в работе программы ничего не изменится." Обращу внимание на целевую аудиторию. Фича не общего регулярного применения. Либо для тех, кто знает зачем. Либо для решения конкретных проблем. По умолчанию — выкл.
Плюс повторю,
размер лога сопоставим с размером обрабатываемых книг. Нет там больших объемов. 200МБ книг —> 200МБ лога. По процессору, формирование строки и запись файл, на фоне поиска десятков и сотен тысяч правил в тексте, даже не процент, а следовое включение. Про синтез и lossy сжатие вообще молчу.
balabolka писал(а): ↑20 июн 2020 00:33
А еще несколько экземпляров программы могут работать одновременно и писать данные в один лог-файл.
Три решения, один другого лучше.
а) стандартные библиотеки логирования, часто умеют немонопольное открытие файла с атомарной записью. Многие программы работают в несколько экземпляров и лог не портят.
б) папка лог-файлов. По файлу на запуск экземпляра. Если дату-время писать в имя файла, их можно убрать из данных, что еще больше сократит размер. Плюсы. Легкая возможность для пользователя обрезать лог по дате. Небольшой файл, который легче открыть и найти данные последнего запуска для решения проблемы. Минусов не вижу.
в) SQLite. Библиотеки доступа простейшие и наилегчайшие. Запись атомарная. Плюсы. Легкость разбора и обработки, данные уже в таблице. Запросы для типовых анализов можно заранее записать во вьюхи. Минусы. Доступ пользователя. Нужна ссылка на инструменты. Либо готовые, либо простенькая утилита вывода в консоль базовой статистики или текстового среза за временной период.
balabolka писал(а): ↑20 июн 2020 00:33
А потом надо будет создать инструмент для анализа лог-файлов, с графиками, таблицами и экспортом в Excel.
Во-первых, зачем создавать? Во-вторых даже если создавать, зачем такую сложную?
Опять целевая аудитория. Одним инструмент не нужен, другим — не поможет. Поэтому давайте есть слона по кусочкам. На любом этапе можете сказать "нет". Или "да", если вам достаточно аргументируют необходимость.
balabolka писал(а): ↑20 июн 2020 00:33
мои предостережения остаются в силе. Если, например, словарь содержит такое правило...
Вопрос кстати интересный. Меня не касается. Обработку провожу в balcon. Но разделить списки задействованных словарей для применения правил и для фильтрации имен, возможно стоит.
Да, работы оказалась немного больше. Надеюсь это не изменить вашего согласия на добавление функциональности. Уж очень надо. /смайл кота из Шрека/
Балаболка TTS
Добавлено: 20 июн 2020 12:44
Kei
Это нормально, что закладки так легко слетают?
Некоторое время активно ими не пользовался, так что проблему только сейчас увидел.
В чём суть - закладки слетают даже если перевставить текст.
CTRL + A > CTRL + C > CTRL + V
И этот документ больше не содержит закладок.
Раньше, насколько я помню, закладки держались крепко. Я спокойно обновлял текст не добавляя новые части, а скопировав его целиком из источника и вставив с заменой. Да к тому ещё я использую форматирование для удаления множества пустых строк, поэтому файл спокойно переживал переезд места назначения закладок из уже сформатированного текста на не форматированный и тут же на снова уже форматированный.
Когда текст не получал добавление фрагментов, а был изменён, то закладки кидали уже немного не туда, но они всё равно присутствовали и были достаточно удобными.
Оно так и должно быть?
Балаболка TTS
Добавлено: 23 июн 2020 16:21
Lecron
Был на старом форуме участник Lev55 (Лёва) создавший неплохую программу для автоматического снятия омонимии. Больше ему спасибо. Заодно, программа применяет к тексту стандартные корректирующие словари. Среди которых один большой на 268к записей.
Играясь сейчас со словарями, заметил, что его программа применяет словари гораздо быстрее Балаболки. Думаю, может проблемы, не все проверяет. Задал ей исходником, левую часть правил самого словаря (размер 3266кБ), на всякий случай поменяв сортировку. Все ОК.
Результаты теста:
Lev55soft: 1 мин 12 секунд
Балаболка: 14 мин 56 секунд (вызов преобразования по Ctrl-T, с одним активированным словарем)
Уважаемый balabolka, не прокомментируете? Кмк, разница 1250% достойна внимания.
Балаболка TTS
Добавлено: 23 июн 2020 19:42
Lecron
UPD: Замена формата на bxd, даже немного увеличило время.
UPD2: Кажется понял. Время преобразования исходя из количества правил словаря
268к 14:56
134к 5:42
67к 2:22
У вас сложность даже не линейная, что предполагал в худшем случае, а степенная.
Оптимальное для поиска красно-черное дерево, индексный поиск аналогичный базам данных, имеет сложность вроде LOG₃(n/2), где n — количество записей в таблице.
То есть преобразование по словарю 268к будет всего на 20% медленнее словаря 67к.
У lev55 тоже далеко от оптимума, но не столь критично. Там либо свой индекс строится в памяти, либо, скорее всего, другая сортировка словаря. Не просто по убыванию, как насколько понял сделано у вас. А по убыванию внутри групп, разбитых по первой букве правила.
Но всетаки, почему не линейно?
Балаболка TTS
Добавлено: 24 июн 2020 10:33
Lecron
Продолжу. Уж очень меня зацепили вчерашние цифры.
Набросал прототип. На небыстром Питоне, а не на быстром компилируемом языке. Делайте поправку на результаты. Впрочем, забегаю вперед, она не сильно-то и нужна.
Задача: отбросить из обработки все правила, которые
гарантированно не подходят к слову.
Текст: 270к слов, представляет левую часть правил применяемого словаря. Содержит *слово*, позволяя проверить применение правил *токен*=ток`ен. Каждое 3 слово с большой буквы, эмулирует поведение стандартного текста. Важно потому, что слова в нижнем регистре требуют вдвое меньше времени на обработку.
Словарь: 270к правил. Какую еще информацию предоставить не знаю. Спрашивайте.
Оптимизации кода наивные. Возможны несущественные огрехи. Например, для токена может существовать несколько правил, и хранить надо список индексов, а не сам индекс.
► Показать
Код: Выделить всё
import time
from pathlib import Path
from typing import Iterator, List
from bintrees import RBTree
class Rule:
def __init__(self, rule: str):
left, _, right = rule.partition('=')
self.right = right.strip()
self.case_sensitive = False
self.any_left = False
self.any_right = False
if left[0] == '$':
self.case_sensitive = True
left = left[1:]
if left[0] == '*':
self.any_left = True
left = left[1:]
if left[-1] == '*':
self.any_right = True
left = left[:-1]
self.left = left if self.case_sensitive else left.lower()
@property
def content(self):
return f'{"*" if self.any_left else ""}' \
f'{self.left}' \
f'{"*" if self.any_right else ""}'
def __contains__(self, text: str) -> bool:
if not self.case_sensitive: # преобразовать регистр у обоих
text = text.lower()
combination = (self.any_left, self.any_right)
if combination == (0,0):
return text == self.left
elif combination == (1,0):
return text.endswith(self.left)
elif combination == (0,1):
return text.startswith(self.left)
else:
return self.left in text
def apply(self, text: str) -> str:
orig = text
if not self.case_sensitive:
text = text.lower()
if (self.any_left and self.any_right) or self.any_right:
return text.replace(self.left, self.right, 1)
elif self.any_left: # aab *ab = *ak
rule_char_count = len(self.left)
return text[:-rule_char_count] + self.right
elif text == self.left:
return self.right
else:
return orig
def open_dictionary(dictionary: Path, encoding: str = 'utf-8-sig') -> Iterator[Rule]:
with dictionary.open('r', encoding=encoding) as f:
for line in f:
yield Rule(line.strip())
def permutation(value):
lower = value.lower()
words = [value, lower] if value != lower else [value]
for word in words:
yield word
for idx in range(0, len(word)):
yield word[:idx+1] + '*'
def get_rules(text: str) -> Iterator[Rule]:
"""Список правил имеющих хоть какой-то шанс быть применимым к тексту"""
indexed_idx = set(v for chars in permutation(text) if (v := index.get(chars)) is not None)
rules_idx = non_indexed_idx + list(indexed_idx)
rules_idx.sort()
for i in rules_idx:
yield rules[i]
start_time = time.time()
dct = Path('dict.dic')
# та самая полная структура с которой работаем сейчас
rules: List[Rule] = list(open_dictionary(dct, 'cp1251'))
# сортируем на вносимые в индекс и обрабатываемые по старинке seq scan
index = RBTree() # структура реализуюящая быстрое для поиска красно-черное дерево
non_indexed_idx = []
for i, x in enumerate(rules):
if (x.any_left and x.any_right) or x.any_left:
non_indexed_idx.append(i)
else:
index[x.content] = i
print(f'Время загрузки: {round(time.time()-start_time, 1)} сек.')
start_time = time.time()
text = Path('test.txt')
with text.open('r', encoding='cp1251') as fi, \
text.with_suffix('.apply').open('w', encoding='cp1251') as fo:
for word in fi:
word = word.strip()
# получаем список правил, имеющих хоть какой-то шанс быть применимым к слову
for r in get_rules(word):
if word in r:
word = r.apply(word)
fo.write(word + '\n')
print(f'Время обработки: {round(time.time()-start_time, 1)} сек.')
Результаты:
Время загрузки: 6.6 сек.
Время обработки: 22.5 сек.
Загрузка небыстрая. Вставка значения в дерево дорогое. Но она отменяет необходимость сортировки правил после загрузки словаря. Плюс скорость обработки, однозначно компенсирует все. Если все равно захочется оптимизировать, индекс можно сохранять в файл. Отслеживая актуальность по самому быстрому хэшу словаря.
Время обработки, без комментариев. В целом, в 2.5 раза быстрее lev55soft и в 30 раз быстрее Балаболки. Понимаю, что реальное применение правил может быть сложнее, но не настолько же.
Еще раз напомню, это Питон. Реальная разница будет еще весомее.
Балаболка TTS
Добавлено: 24 июн 2020 15:29
Lecron
Для тех кто не хочет разбираться в коде поясню.
Все правила словаря делятся на 2 категории:
а) *правые, *внутренние*, регэкспы. Утверждать неприменимость которых сложнее, чем пробовать применить и посмотреть что выйдет. А так как их меньшинство меньше 2-5%, то и фиг с ними.
б) константные, левые*, чью неприменимость можно определить за логарифмическое время. Индексируем их по первым N символам, что позволяет за N запросов к индексу, вернуть в среднем, в 30^N меньшее количество правил (на ьъй слова не начинаются) подходящих для строки, утверждая неприменимость остальных. Фактически сводя скорость применения всех правил, к скорости применения правил группы "а", сокращая ее до меньше 2-5% от нынешней. Причем скорее 2, чем 5.
Доступ к индексу очень быстр. В данном примере, за 22 секунды. Было произведено 3 миллиона 100 тысяч запросов. К базе из 270к записей. Из Питона.
PS. Сейчас индекс по всему слову, но преобразовать его к токен[:N] дело 5 строк кода.
Балаболка TTS
Добавлено: 24 июн 2020 19:02
wasyaka
Lecron писал(а): ↑24 июн 2020 10:33
Продолжу. Уж очень
{IVONA} ВСЁ ВКЛЮЧЕНО. ГОТОВЫЕ СБОРКИ ДЛЯ ЧТЕНИЯ/ЗАПИСИ КНИГ.
{Yandex TTS} Всё включено. Готовые сборки для записи книг.
Сборки от
wasyaka
tonio_k
А от
Lecron только вопросы,вопросы,вопросы...
И все ему должны... ответить на...вопросы,вопросы,вопросы...
А поделится западло? Все вам обязаны и должны?
Жду ВАшу сборку..
Потреблять конечно ....
Приятного апетита...
Балаболка TTS
Добавлено: 26 июн 2020 23:26
Kei
Судя по всему, исчезновение закладок после перевставки текста связано с изменением от 27.10.2019, в версии 2.15.0.716.
[-] Исправлено изменение позиций закладок при редактировании текста.
Установив предшествующую версию, исчезновение закладок я не обнаружил.
Можно ли сделать данное исправление опциональным, добавив куда-нибудь в меню “Перейти по именной закладке” возможность закрепить в файле закладки, с возможностью их удаления только через данное меню. Или же добавить какую-нибудь возможность импорта-экспорта закладок либо в сам текст, либо в отдельный файл.
Или иной способ избежать удаления закладок при полной замене текста, когда в источнике он был дописан или немного изменён. Потеря возможности обновить немного изменённый текст с сохранением примерного местонахождения закладок и возможности добавления нового фрагмента, без потребности вручную его искать в источнике, кажется для меня значительной. Особенно, если окончание моей версии текста в источнике подверглось изменению и теперь не представляется возможности воспользоваться поиском и сразу перейти на место, с которого надо копировать текст.
Прошу прощения, если это добавит работы, но надеюсь с этим можно что-то сделать. Сохранять <bookmarks> из файла весьма неудобно, особенно когда это не bxt а bxz файл. А сидеть на устаревшей версии программы не хочется, особенно когда программа на регулярной основе обновляется и получает исправления, улучшение и расширение функционала.
Балаболка TTS
Добавлено: 27 июн 2020 21:38
Lecron
Совместил приятное, познакомился с Rust, с полезным, проверил работу своего предложения на компилируемом языке.
5 секунд на обработку 270к слов / 3.3МБ, по словарю 270к правил / 6.6МБ. Меньшие объемы, будут вообще за доли секунды. Зависимость скорости обработки от длинны ключа:
► Показать
Словарь 3 симв.
Время загрузки: 485 миллисек.
Время выполнения: 201299 миллисек.
Словарь 4 симв.
Время загрузки: 483 миллисек.
Время выполнения: 51633 миллисек.
Словарь 5 симв.
Время загрузки: 502 миллисек.
Время выполнения: 10501 миллисек.
Словарь 6 симв.
Время загрузки: 528 миллисек.
Время выполнения: 6001 миллисек.
Словарь 7 симв.
Время загрузки: 547 миллисек.
Время выполнения: 5126 миллисек.
Словарь 8 симв.
Время загрузки: 568 миллисек.
Время выполнения: 4862 миллисек.
Словарь 9 симв.
Время загрузки: 579 миллисек.
Время выполнения: 4761 миллисек.
У Балаболки потенциал оптимизации в 100+ раз, по применению словарей. Нынешний результат: 15 минут.
balabolka, Каково вообще Ваше мнение по этой идее и ее результатам? Фича почти не требует переделки вашего кода и даже может его упростить. Концептуально, это фильтр вставляемый перед процедурой перебора правил.
ЗЫ. Во вложении исполняемый файл, примеры словаря и текста, плюс исходник (код).
Балаболка TTS
Добавлено: 30 июн 2020 23:03
Lecron
Кажется Вы забыли обновить portable версию. В архиве 745 от 30 мая.
Балаболка TTS
Добавлено: 01 июл 2020 10:01
Lecron
Отлично сделано. Большое спасибо. Правда первый раз поведение чекбоксов в стиле радио-кнопок немного сбило с панталыку.
Для опасающихся пропустить нужное при частичном совпадении, есть логичный лайвхак. Прослушиваете, вносите в словарь, оставшееся добавляете в список прослушанного, переключаетесь на полное совпадение и видите только шаблонные слова.
Однако есть и сожаление. Из-за которого долго сидел на старой версии. В окне добавления слова в словарь, нужны другие кнопки с символами. Возможно настраиваемые. Одним надо "С^аломин", штатное ударение для Ольги. Другим ""Са`ломин". Конечно можно их вводить с клавиатуры, но очень неудобно постоянно переносить руку.
Есть рекомендации? Неужели никто больше с этим не сталкивается и у всех голосов ударение "<>"? В чем вообще причина удаления двух небольших кнопок?
Балаболка TTS
Добавлено: 02 июл 2020 11:04
Lecron
Lecron писал(а): ↑01 июл 2020 10:01
Отлично сделано. Большое спасибо.
balabolka, Рано обрадовался. Фича затруднительная в использовании.
Тестирую на очень небольшой книге, на ~72 бумажные страницы. Поиск имен занимает 4 секунды. (?) При последующей активации "частичное совпадение", замирает еще на 16 сек.
Правил в активированных словарях: всего 74к, шаблонных 4к. Шаблоны естественно сложнее обрабатывать, но "расширение" словаря на 5% не должно увеличивать время в 5 раз.
Для справки (и намек :) — всего в книге слов без фильтров 6027, только имен 153, не показывать из текстового файла 39.
Когда подключаю большой "стандартный" словарь, вообще сливай воду. Поиск имен занимает 15 сек. Кстати, почему дольше? Предположу, что фильтр "точное совпадение" вычисляется независимо от выбранных опций, нужен или вреден, ибо потом его активация мгновенна. Когда же активирую "частичное совпадение" программа замирает на еще 48 секунд.
И это на маленькой повести. Полноценный роман, в общем подвесит программу на 1.5 минуты при базовых словарях или 4 минуты при полном. Не срослось. Жаль :(
Балаболка TTS
Добавлено: 05 июл 2020 10:59
Lecron
balabolka, Спасибо за доработку поиска имен. Работает быстро. Но починив одно, вы кажется поломали другое.
После добавления слова в словарь, исчезновение из списка, переход к следующему слову и его озвучивание, происходит с очень большой задержкой. Даже при Точном совпадении. В это время, ни на курсор, ни на мышь не реагирует. Происходит когда в списке активированных, есть "толстый" словарь. В старой версии 2.7, это быстро, несмотря на толщину словарей.
И сразу очередная просьба. Если не трудно, ибо просьба не критичная, при Частичном совпадении, после добавления в словарь шаблона, удалять из списка сразу все слова под него попадающие, а не только текущее прослушиваемаемое.
Балаболка TTS
Добавлено: 05 июл 2020 22:36
GregoryR
Здраствуйте Илья, во первых балаболка это великолепная программа. Я использую ее для детей с проблемами развития, очень им помогает. Единственный недостаток(а может я просто не нашел как это включить) это то что она не корректно поддерживает правосторонние языки: Арабский и Иврит. К чтению вслух нет никаких претензий, но вот выделение текста идет наоборот и выделение текста не корректно. Проблема в том что текстовое поле по умолчанию разворачивает текст в левостороннее направление. Если бы был чекбокс который бы менял направление текста было бы идеально. Это как в HTML, по умолчанию стоит dir="ltr" -направление слева направо, а для арабского и иврита ставится направление справа налево dir="rtl". Может такая опция уже есть?
Балаболка TTS
Добавлено: 10 июл 2020 20:54
groand
Я посмотрел на ваше "плавающее окно" в Балаболке и подумал, а нельзя ли создать панель, которая читала бы прямо в Word? Это нужно, чтобы можно было хорошо ориентироваться в сложно-форматированном тексте и сразу его править. У меня есть старая программка (TTSC 5.13.05.03) тринадцатилетней давности, которая это делает, но делает она это не совсем так, как нужно.
Вот если бы сделать так, чтобы такая панель точнее выделяла читаемые предложения, и чтобы пропускала скрытый текст (и прочие каверзы, так как эта программка иногда почему-то виснет и на каких-то моментах сбивается маркировка - отстаёт от читаемого), и чтобы можно было установить, какие определённые форматы должны пропускаться\не читаться (цвет текста, размер, жирность-курсив... - это разные ссылки и комментарии, не принадлежащие к основному тексту), а также содержимое определённых скобок.
И если можно, то чтобы она работала и с Word 2003, так как я не хочу переходить на более новый, хоть он у меня и есть.
Возможно ли такое? Прослушивание и редактирование прямо в Ворде, это как-то очень нужно. Такое мнение слышал уже от многих моих знакомых. А имеющееся TTS в последних версиях Ворда не имеет утончённых установок, которые я выше назвал.
Балаболка TTS
Добавлено: 12 июл 2020 19:06
levm
Почему-то команда "Найти имена в тексте..." выдает в результатах поиска очень большое количество слов, в которых нет совсем букв в верхнем регистре. Совсем нелогично для имен/названий.
Балаболка TTS
Добавлено: 12 июл 2020 23:18
tonio_k
levm писал(а): ↑12 июл 2020 19:06
"Найти имена в тексте..." выдает в результатах поиска очень большое количество слов, в которых нет совсем букв в верхнем регистре.
Скорее всего вы выбрали пункт "Показывать все слова" - это в прямом смысле вывод в список и подсчет всех слов присутствующих в книге.
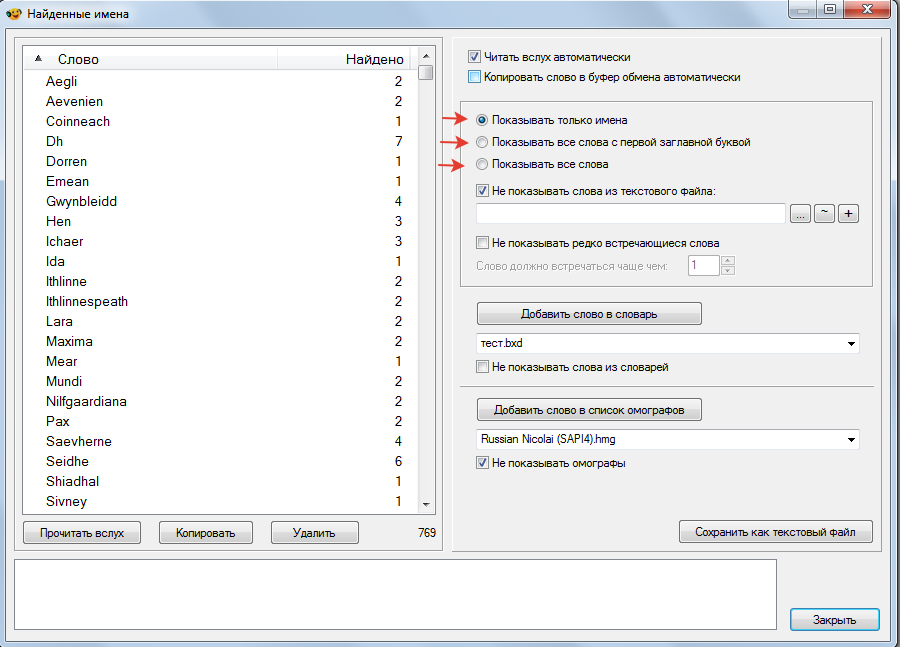
Вам нужен пункт "Показывать только имена" причём, это не даст 100% гарантии что выдаст все имена. Опознание слова как "Имя" возможно при совпадении 3 одновременных условий:
- слово начинается с Заглавной буквы
- слово не является первым в предложении
- слово состоит из первой Заглавной буквы, остальные - строчные.
Что бы кроме имён еще выводил и аббревиатуры, то нужно выбрать "Показать все слова с заглавной буквы". Но тут придётся мириться с тем, что кроме Аббревиатур в список попадут и Имена и все слова с которых начинается предложение.
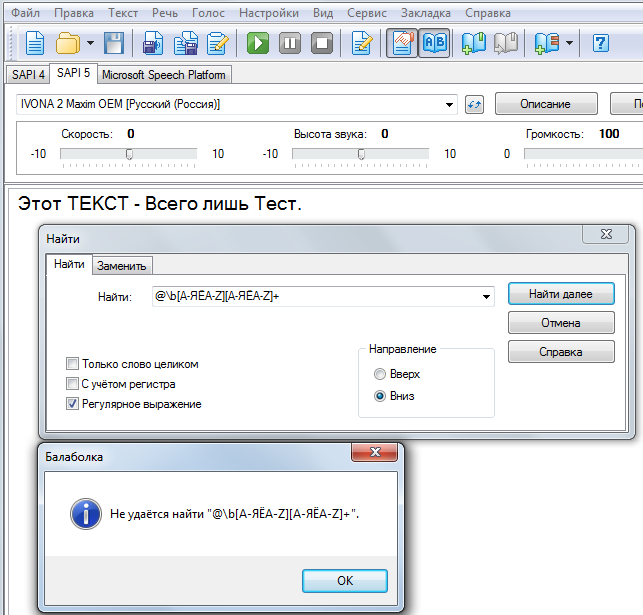
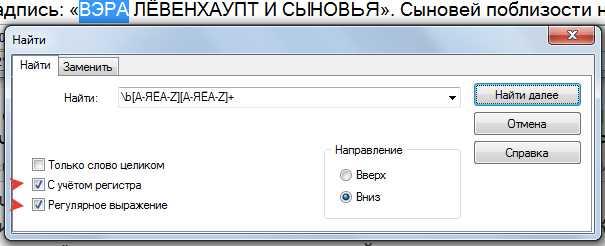
При помощи регулярного выражения можно найти
Имена:
Код: Выделить всё
@[А-ЯЁA-Zа-яёa-z][,: -]? \b[А-ЯЁA-Z][а-яёa-z]+
Аббревиатуры:
Только почему-то в Балаболке эти поисковые запросы не работают

► Показать
- 2020-07-12_23-14-44.png (82.39 КБ) 8653 просмотра
Балаболка TTS
Добавлено: 13 июл 2020 06:51
wasyaka
tonio_k писал(а): ↑12 июл 2020 23:18
Только почему-то в Балаболке эти поисковые запросы не работают
убери знак регистра (он на панели поиска вкл.
\b[А-ЯЁA-Z][А-ЯЁA-Z]+
Балаболка TTS
Добавлено: 13 июл 2020 11:08
levm
tonio_k писал(а): ↑12 июл 2020 23:18
"Найти имена в тексте..."
Я имел в виду не общий поиск "Найти...", а команду в "Настройки-Коррекция произношения-Найти имена в тексте...", которая СРАЗУ выдает длинный список результатов вместе с ненужными, но никаких промежуточных подпунктов команды там нет. Поэтому предположил, что это требует исправления в самой программе, и спросил об этом.
На представленном Вами скриншоте ОБЩЕГО поиска нет таких пунктов:
tonio_k писал(а): ↑12 июл 2020 23:18
выбрали пункт "Показывать все слова"...
нужен пункт "Показывать только имена"...
выбрать "Показать все слова с заглавной буквы"
Откуда они, tonio_k?
Балаболка TTS
Добавлено: 13 июл 2020 11:23
levm
Оба регулярных выражения -
wasyaka писал(а): ↑13 июл 2020 06:51
\b[А-ЯЁA-Z][А-ЯЁA-Z]+
и
tonio_k писал(а): ↑12 июл 2020 23:18
\b[А-ЯЁA-Z][а-яёa-z]
выдают ОДИНАКОВЫЕ результаты поиска (по ОДНОМУ слову, а не списком). Причем ИСКЛЮЧИТЕЛЬНО находятся слова из букв на латинице, да и НЕ РАЗЛИЧАЯ РЕГИСТР, т. е. там мне попались, например, "headset", "incunabula", "end". На КИРИЛЛИЦЕ поиск по этим выражениям НЕ РАБОТАЕТ. Получается, что не достигается цель
:
tonio_k писал(а): ↑12 июл 2020 23:18
Опознание слова как "Имя" возможно при совпадении 3 одновременных условий:
- слово начинается с Заглавной буквы
- слово не является первым в предложении
- слово состоит из первой Заглавной буквы, остальные - строчные.
Что бы кроме имён еще выводил и аббревиатуры, то нужно выбрать "Показать все слова с заглавной буквы".
Балаболка TTS
Добавлено: 13 июл 2020 11:38
tonio_k
levm писал(а): ↑13 июл 2020 11:08
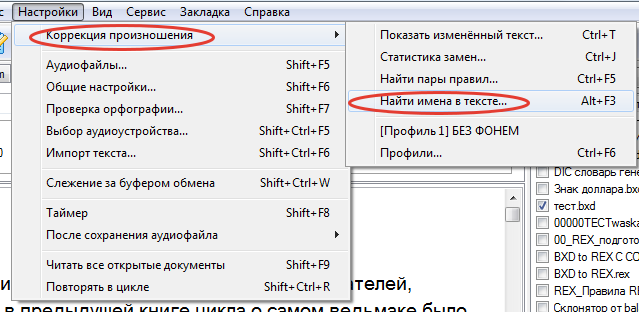
Я имел в виду не общий поиск "Найти...", а команду в "Настройки-Коррекция произношения-Найти имена в тексте...", которая СРАЗУ выдает длинный список результатов вместе с ненужными, но никаких промежуточных подпунктов команды там нет.
у меня промежуточные подпункты есть:
► Показать
- 2020-07-13_11-24-29.png (43.21 КБ) 8616 просмотров
► Показать
- 2020-07-13_11-23-25.png (79.81 КБ) 8616 просмотров
Оба регулярных выражения ... выдают ОДИНАКОВЫЕ результаты поиска (по ОДНОМУ слову, а не списком).
через обычный поиск "Найти" и должен искать по одному прыгая по тексту. При этом прекрасно находит и на Русском и на латинице при правильно активированных галочках:
► Показать
- 2020-07-13_11-29-14.png (38.8 КБ) 8616 просмотров
у меня Балаболка вер. 2.15.0.741
Балаболка TTS
Добавлено: 13 июл 2020 12:04
levm
tonio_k писал(а): ↑13 июл 2020 11:38
у меня промежуточные подпункты есть:
Точно, tonio_k. Слона я не приметил

. Наверное, потому что автоматически стараюсь проскочить искаженные программные диалоги. Искажение возникает в некоторых диалогах из-за предпочитаемого среднего (125%) шрифта, который лучше воспринимаю.
Балаболка TTS
Добавлено: 26 июл 2020 16:54
levm
Почему-то проверка орфографии не работает после того, как загрузил словарь hunspell с сайта Балаболки и установил его. Несмотря на следование указанию Справки. Даже специально для тестирования стер в слове несколько букв - никакой реакции.
Балаболка TTS
Добавлено: 01 авг 2020 10:40
krys4d
Здравствуйте.
Подскажите в чем проблема и как ее исправить.
На компьютере установлено три голоса: два от ивоны (их я устанавливал сам) и один стандартный от майкрософта, но балаболка не видит не один из них.
► Показать
- 11.PNG (6.23 КБ) 7919 просмотров
В тоже время ридер от ивоны все голоса видит и воспроизводит.
При заходе в распознавание речи через панель управления виндовс выдает вот это сообщение (я так понимаю проблема с балаболкой связана как раз с этим сообщением?):
► Показать
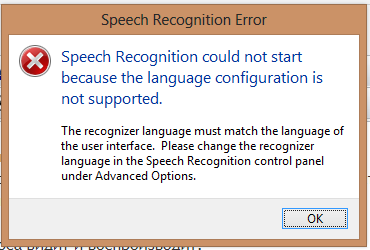
- 12.PNG (15.84 КБ) 7919 просмотров
Но при этом, если вызвать экранного диктора, то он будет читать голосом, который можно выбрать в настройках распознавания речи.
Балаболка TTS
Добавлено: 01 авг 2020 12:51
balabolka
krys4d писал(а): ↑01 авг 2020 10:40
На компьютере установлено три голоса: два от ивоны (их я устанавливал сам) и один стандартный от майкрософта, но балаболка не видит не один из них.
Не смогу Вам помочь, мне жаль. Это то, о чем предупреждал в отношении голосов IVONA
здесь. Не знаю, что не так с последними дистрибутивами голосов этой фирмы, но они иногда вызывают проблемы на компьютерах пользователей.
Попробуйте скачать и запустить утилиту
TTSApp из Microsoft Speech SDK: проверьте, видит ли она установленные голоса. (Будет понятно, проблема только в одной программе или в других программах тоже.)
Можно попробовать переустановить голоса IVONA (каждый раз проверяя, видит "Балаболка" голоса или нет). Более радикальный совет - откатить Windows к предыдущей точке восстановления, когда голоса еще не были установлены.
Если кто-то знает более эффективный способ решения проблемы, я тоже буду рад его выслушать.
Балаболка TTS
Добавлено: 01 авг 2020 13:54
krys4d
balabolka писал(а): ↑01 авг 2020 12:51
Не знаю, что не так с последними дистрибутивами голосов этой фирмы, но они иногда вызывают проблемы на компьютерах пользователей.
Если дело в ивоновских голосах, то почему тогда балаболка не видит и стандартный от майкрософта голос?
Балаболка TTS
Добавлено: 01 авг 2020 14:30
balabolka
krys4d писал(а): ↑01 авг 2020 13:54
Если дело в ивоновских голосах, то почему тогда балаболка не видит и стандартный от майкрософта голос?
Потому что голоса IVONA "ломают" функцию получения списка голосов в SAPI 5.
Балаболка TTS
Добавлено: 01 авг 2020 15:39
tonio_k
balabolka,
тут вы давали ссылку на маленький скрипт PowerShell. Приведу его здесь:
► Показать
Код: Выделить всё
function Out-Speech($text) {
$speechy = New-Object –ComObject SAPI.SPVoice;
$voices = $speechy.GetVoices();
foreach ($voice in $voices) {
$voice.GetDescription();
$speechy.Voice = $voice;
$speechy.Speak($text);
}
}
Out-Speech("Testing, One, Two, Three. А теперь на русском: Один, Два, Три.");
Вот так его запускаем:
► Показать
Нажимаем кнопку Пуск на рабочем столе
Вводим текст:
Windows PowerShell
Запускаем найденную программу.
Ждем когда загрузится синее окошко и дожидаемся когда появится строка что то вроде:
PS C:\Users\
Копируем текст скрипта, нажимаем правой клавишей мыши на синем экране программы - текст скрипта вставится в синее окно
Нажимаем Enter ждём: слушаем и смотрим на результаты.
Если будут выходить красные сообщения об ошибках, вероятно у вас старая версия PowerShell - обновить ее можно по этой
инструкции. Обновляется пакет Windows Management Framework 5.1
Мне интересно:
1) если выше приведенный скрипт у пользователя отработает с положительным результатом (будут показаны голоса и текст будет озвучен), а балаболка при этом не видит голоса - это вам чем-то поможет?
2) получение списка голосов может быть как то связан с не установленным Windows Management Framework 5.1 - частью которого является PowerShell?
Балаболка TTS
Добавлено: 01 авг 2020 15:58
balabolka
krys4d
Пожалуйста, скачайте и запустите программу
TTSApp. Это утилита, написанная программистами из Microsoft, так что она лучше всего предназначена для работы с Microsoft Speech API. По крайней мере, будет какая-то ясность в том, насколько серьезна проблема с голосами. Чем больше информации, тем лучше.
tonio_k
Это то же самое, что делает "Балаболка" для получения списка голосов. Можно запустить и этот скрипт, но предпочтительнее использовать программу от Microsoft.
Балаболка TTS
Добавлено: 01 авг 2020 17:41
krys4d
balabolka
TTSApp выдает вот это:
► Показать
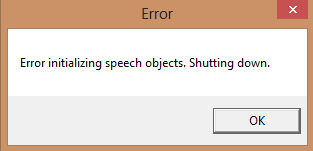
- 13.PNG (3.67 КБ) 7882 просмотра
PowerShell выдает вот это:
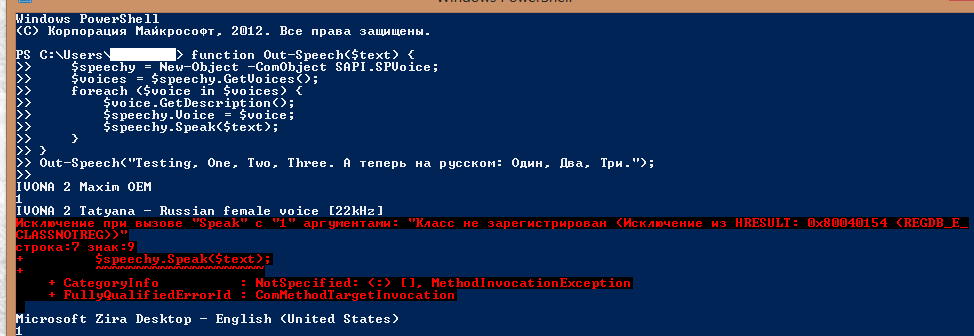
► Показать
- 14.PNG (28.42 КБ) 7882 просмотра
tonio_k писал(а): ↑01 авг 2020 15:39
Если будут выходить красные сообщения об ошибках, вероятно у вас старая версия PowerShell - обновить ее можно
Вручную обновить не получается, если будет завтра время, то попробую обновиться через центр обновления.
Балаболка TTS
Добавлено: 01 авг 2020 20:15
tonio_k
krys4d писал(а): ↑01 авг 2020 17:41
PowerShell выдает вот это:
замечу, что на скриншоте IVONA 2 Maxim и Tatyana, в конце концов видны в консоли PowerShell. К сожалению моих познаний в PowerShell мало что бы оценить, является ли красное сообщение об ошибке признаком старой версии PowerShell или это проблема самих голосов. Очень надеюсь, что с обновлением PowerShell и проблема с голосами пропадет. Попробуйте переустановить голоса после обновления если сразу не заработают. (В любом случае не факт что обновление поможет)
Балаболка TTS
Добавлено: 01 авг 2020 21:42
krys4d
balabolka
tonio_k
Все таки видимо дело в ивоновских голосах версии 1.6.75, потому что установил на втором компе голоса версии 1.6.74 - балаболка увидила их без проблем.
Вопрос теперь в другом: как полностью удалить с пеки 1.6.75 чтобы не было конфликта с 1.6.74?