Страница 1 из 8
Demagog TTS
Добавлено: 20 июн 2018 02:54
Fenix
- demago2.gif (133.66 КБ) 58872 просмотра
- demag0.jpg (297.36 КБ) 58872 просмотра
Сайт программы
 Demagog
Demagog
SAPI4 / SAPI5 - совместимый синтезатор речи (Text To Speech software); OS Windows 10, 8, 7, XP.
Demagog - говорящий текстовый редактор.
 Венедикт Ли
Венедикт Ли
Возможности:
- Редактирование текстов
- Полная поддержка Юникода
- Чтение текста вслух
- Поддержка чтения многоязычных текстов
- Конвертация текста в аудио-файл
- Пакетная запись аудио
- Запись аудио в виде сериала, т.е. с делением на фрагменты заданного размера
- Поддержка словарей корректировки произношения популярного формата .dic
- Поддержка аналогичных словарей формата .rex, основанных на регулярных выражениях
- Подключение одновременно нескольких словарей
- Импорт рисунков из документов MS Word и E-Books, fb2, ePub
- Развитая система поиска и замены в тексте
- Подсветка орфографических ошибок, омографов, и близко стоящих похожих слов (опция "Свежий взгляд")
- Пользовательские настройки окна редактирования: шрифт, фон или фоновая картинка
- До 16 одновременно открытых файлов
- Встроенный интерпретатор для создания пользовательских скриптов: например, экспресс-анализа текстов или математических расчетов.
- Получение результатов выполнения скриптов не только в текстовом виде, но и в форме графиков и диаграмм
- В число поддерживаемых форматов файлов входит .dxt - документ Demagog. По функциональным возможностям он соответствует известному межплатформенному формату .rtf
Название программы соответствует ее назначению, и происходит от первоначального значения греческого слова δημαγωγός - "говорящий с народом". Программа не требует установки и поставляется уже готовой к использованию. Для этого надо запустить исполняемый файл Demagog.exe. Для удаления программы достаточно удалить с компьютера папку Demagog со всем ее содержимым. Программа не изменяет никакие системные файлы, не содержит рекламы, не собирает и не передает личные данные пользователей.
Примечание 1:
Под управлением Windows 10 формат dxt обладает расширенными возможностями.
Доступны дополнительно "
Выравнивание текста по ширине" и вставка рисунков перетаскиванием или из Буфера обмена непосредственно в текст; изменение ширины столбцов таблицы перетаскиванием их границ мышью.
- ternii.gif (201.42 КБ) 58872 просмотра
Примечание 2:
Результаты выполнения скриптов могут выдаваться интерпретатором в наглядной, графической форме. Полученное изображение можно сохранить в файл типа .png для дальнейшего использования.
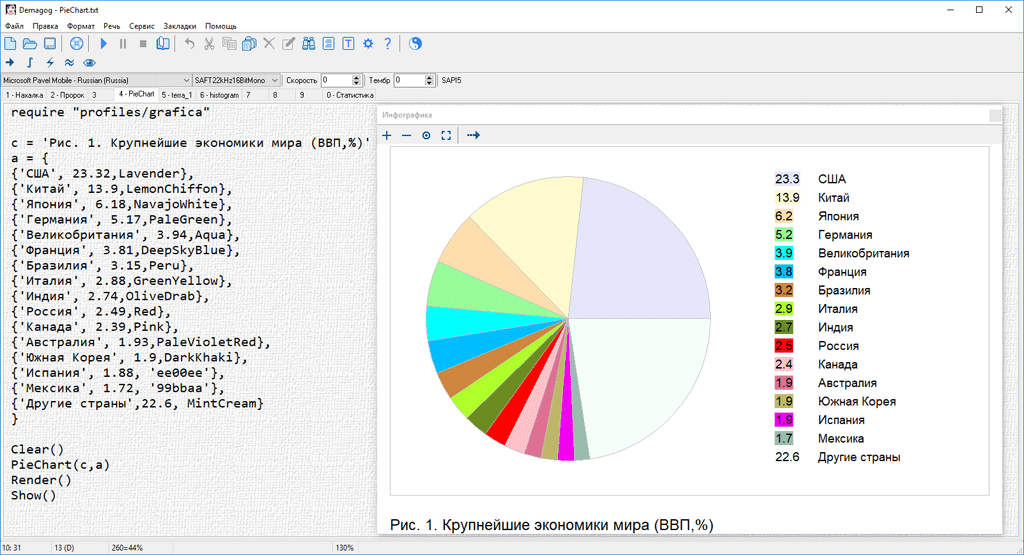
- grafica.gif (140.9 КБ) 54322 просмотра
Многоязычный интерфейс:
- Английский
- Русский
- Украинский - перевод Evgeniy Miroshnychenko
- Эсперанто
- Испанский
Простота добавления новых языков интерфейса.
Для поддержки регулярных выражений Demagog использует библиотеку
SkRegExp, разработанную
Shuichi Komiya -
https://github.com/shukomiya/skregexp. Библиотека лицензирована под
MPL 2.0.
Встроенный интерпретатор в Demagog основан на библиотеке
VerySimpleLua, разработанной
Dennis D. Spreen -
https://github.com/Dennis1000/verysimplelua. Библиотека лицензирована под
MPL 2.0.
Фрагменты исходного кода Demagog были использованы разработчиками широко известного погодного робота
Meteonova -
http://www.meteonova.ru/.
В 2009 г. Demagog занял 3-е место в конкурсе Soft.Mail.ru "Самые популярные программы года" в номинации "Текст".
Одно из авторитетнейших компьютерных изданий - выходящий на 15 языках журнал "CHIP" (№5/2014), назвал Demagog в числе наиболее известных программ для управления речевыми движками.
Издание на Google books: "250 лучших бесплатных программ" так же включило Demagog в свой список, раздел "Преобразование текста в звук".
28.10.2007 - день рождения программы Demagog.
Re: Общая тема
Добавлено: 20 июн 2018 03:38
evmir_troll-hunter
Формат
*.dxt удобный и практичный:
- все закладки, картинки\таблицы, выделение шрифтом и цветом сохраняются.
Можно подготовить список слов\фраз, выделить проблемные моменты, проиллюстрировать скринами, и переслать другу.
- уменьшение размера больших сборников в 1.5-3 раза.
17.06.15
версия 7.28.296
Изменения:
1) Добавлена опция "Сервис - Статистика - Необработанные омографы";
За скромным названием скрывается вот что; возникла идея списка строк "неучтённых омографов"... но как?
1). открыть текст, отметить галочками словарь alenka.hmg и все словари замен
2). включить опцию, и программа отобразит строки со всеми омографами, не входящими в состав правил замен
Упрощённые примеры:
правило в словаре -
анализ крови=анализ крОви
фраза в тексте -
анализ его крови показал...
Демагог прописывает строку -
крови | анализ его крови показал...
------
правило в словаре -
арки ворот=арки ворОт
фраза в тексте -
у арки замковых ворот...
Демагог прописывает строки -
ворот | у арки замковых ворот...
замковых | у арки замковых ворот...
Некоторые замечания:
- у моих примеров 3-4 слова всего, Демагог же прописывает строку с омографом в окружении пяти предшествующих и пяти следующих слов.
- в принципе анализируются только 3 *.dic словаря - Словарь замены ударений, Большой словарь замен и Расширенный словарь замен. Т.к. другие не ассоциируются с alenka.hmg.
Но если кто-то захочет поэкспериментировать с *.rex - пожалуйста.
- есть возможность запретить программе отображать строки с указанными омо. Перед поиском омографов выдается запрос: какие не искать.
Введите перечень через ;
Данная функция полезна для "все\всё всем\всём" потому что:
- на данном этапе задача омографа "все\всё всем\всём" нерешаема
- из форумских .dic-словарей изъяты все правила с этими омо
- Венедикт Ли подтвердил и уточнил мою догадку, что словарь vse_vsyo.rex эффективен на 60%
- если пользователям захочется помучиться, они смогут отобразить строки с "все\всё всем\всём" намного быстрее с помощью Поиска и Шаблона DIC
Ну и самый главный вопрос - зачем это надо?!
Проанализировав полученный список каждый пользователь имеет возможность быстро сформировать свой собственный словарь замен... сообразно своих литературных предпочтений.
Ведь список будет содержать омограф в контексте.
Спасибо автору за воплощение идеи.
Demagog TTS
Добавлено: 27 июн 2018 15:38
Fenix
flegont писал(а): Nov 23 2017
Demagog расширенно толкует правила для словарей формата .DIC, в которых есть символ *
Он обозначает изменяемую часть слова.
Например: *стрелил*=стрелИл
Но, отличие от сложившегося стандарта, звездочка может стоять не только в начале и/или конце левой части правила. А так же в начале и/или конце любого слова в левой части правила.
ворот* города=ворОт гОрода
Звездочка также может стоять отдельно от других слов, обозначая любое слово:
все * *ло= всё ло
все давно прошло. --> всё давно прошло.
все вокруг потемнело. --> всё вокруг потемнело.
все мне надоело. --> всё мне надоело.
*ный, * *, берег=ный, , бЕрег
черный, усыпанный ракушками, берег --> черный, усыпанный ракушками, бЕрег
песчаный, покрытый мусором, берег --> песчаный, покрытый мусором, бЕрег
мрачный, наводящий ужас, берег --> мрачный, наводящий ужас, бЕрег
И т.д. и. т.п...
tonio_k писал(а): Nov 26 2017
Для понимания работы со словарями в
Demagog в сравнении с
Балаболка,
прошу ответить на вопросы.
Ответы по
Балаболке тут
1) В какой последовательности идёт замена по списку файлов словарей (кто раньше)
REX или
DIC?
2) В какой последовательности идёт обработка файлов словарей
REX между собой - по алфовиту?
3) В какой последовательности идёт обработка файлов словарей
DIC между собой - по алфовиту?
4) В какой последовательности идёт оброка строк правил внутри самого словаря? (
REX /
DIC) с первой строки и далее вниз?
5) какие словари по производительности быстрее работают? Какому отдать предпочтение для скорости обработки текста
REX или
DIC ?
6) если отсортировать правила внутри словаря по алфовиту или по длине строки или ещё по какому признаку это как то влияет на ускорение процесса обработки словаря (
REX /
DIC)
7) большой размер файла
DIC. Может его лучше разбить на несколько небольших? или можно смело объединять в один файл? Или нет разницы и на производительность не влияет?
Если отличия единичны, то, пожалуйста, укажите только эти отличия.
flegont писал(а):Отличия лишь в словарях DIC.
Demagog поймет любой dic-словарь от Балаболки, но обратное - неверно.
Если правило в левой части содержит звездочки, то в классическом формате DIC (придуманном много лет назад автором "Говорилки" Антоном Рязановым) звездочки могут быть только в начале и/или в конце левой части правила. Пример:
ворот*=ворОт
ворота --> ворОта
воротах --> ворОтах
...
Такое правило одинаково отработает в Demagog'e и в Балаболке.
Но в Demagog'e звездочка в dic-словаре может стоять и внутри левой части правила. Пример 2:
ворот* города=ворОт гОрода
Текст:
Ворота города отворились. У ворот города началась битва. Над воротами города реяли стяги. Изменников повесили на воротах города.
Измененный текст в Demagog'e:
ворОта гОрода отворились. У ворОт гОрода началась битва. Над ворОтами гОрода реяли стяги. Изменников повесили на ворОтах гОрода.
В Балаболке текст не изменится, потому что такие правила она не обрабатывает.
P.S. DIC словари обрабатываются быстро и разбивать их на части для "ускорения" совершенно не нужно.
А REX словари имеют важную особенность: правила в них применяются к тексту строго в порядке их следования в словаре. При этом предыдущие правила могут быть "подготовительными" для работы последующих. И разбив такой REX-словарь на части, вы рискуете просто испортить его и получить непредсказуемые результаты.
P.P.S. В среднем, dic-словари работают заметно быстрее rex-словарей. Но rex-словари обладают значительно бОльшей гибкостью. Это - плюс. Плата за мощь и универсальность - сложность языка регулярных выражений. Это - минус. Пользователь сам решает, какие словари ему удобнее в применении.
tonio_k писал(а):Не хочу ничего усложнять, поэтому только к рассмотрению
допустим фраза:
привет, Тому
$*, Тому=тОму - замена произойдет, потому что ","
$*! Тому=тОму - замена НЕ произойдет, потому что любой другой знак припенания
$* Тому=тОму - замена ВСЕГДА произойдет - при любом знаке препинания и даже его отсутствии!
Тоесть от этих правил:
$Тому=тОму
$*Тому=тОму
$ Тому= тОму
ничем не отличается (ну разве что книга со слова Тому начинается)
Таким образом, $* Тому=тОму сработает при любом положении Тому в тексте, если он с большой буквы.
Может ввести в программу какой нибудь особый знак (например "^") обозначающий конец слова?
тогда:
$*^ Тому=тОму[/b] - сработает только на привет Тому
$*^, Тому=тОму[/b] - сработает только на привет, Тому аналогично $*, Тому=тОму
Или "объяснить программе"
"* " это означает любое слово и пробел за ним, (при этом между самим словом и пробелом ничего нет)
"*, " это означает любое слово, запятая, пробел (при этом между самим словом и запятой ничего нет)
[merge_posts_bbcode]Добавлено: 2017-12-05 12:31:44[/merge_posts_bbcode]
Еще одно замечание.
При обработке текста в Demagog.
Если выделить сразу три словаря DIC и поставить на обработку текст - получим один результат.
А если тот же текст обработать последовательно каждым словарем друг за другом в отдельности, то может получится другой результат.
Т.Е если выделить несколько словарей, то программа их "как бы" объединяет в один файл и начинает обрабатывать по длине правил внутри этого "объединенного" файла.
Так задумано?
flegont писал(а):$* Тому=тОму - замена ВСЕГДА произойдет - при любом знаке препинания и даже его отсутствии!
Совершенно верно. Но это придумано не мной, а Антоном Рязановым, автором "Говорилки" много-много лет назад. С тех пор формат DIC утвердился именно в таком виде. Если нет знаков препинания в шаблоне замены, то заменяются слова как со знаками, так и без знаков препинания. Чтобы на каждый знак препинания не приходилось сочинять отдельные правила для каждого слова. Точно так же игнорируются скобки и кавычки - замена всегда происходит внутри них.
А если в шаблоне
явно указан знак препинания/скобки/кавычки, тогда они учитывается при поиске подходящей замены.
Об отличиях формата DIC в Демагоге от стандарта я уже упоминал. Все они реализованы без введения каких-либо дополнительных управляющих символов, которых в dic-словарях всего три: * $ #
А поскольку Демагог поддерживает еще и REX формат - словари регулярных выражений - гораздо более мощное средство, то дальнейшие придумки к формату DIC уже будут напоминать изобретение велосипеда.
Re: Общая тема
Добавлено: 27 июн 2018 16:02
evmir_troll-hunter
flegont писал(а): Dec 5 2017
Способ применить к тексту одновременно кипу словарей, но в заранее заданном пользователем порядке - в Демагоге есть...
Версия 331:
"Выполнить скрипт" (кнопка со значком интеграла)
"Из файла"
"Pronunciation adjustment.lua"
tonio_k писал(а):может будет проще и универсальнее (чтобы не лазить в сам скрипт и не сломать в нем что либо), это добавить в скрипт или создать новый с возможностью выбора файла листа *.lst , который пользователь сам может легко подготовить. В этом файле *.lst пользователь перечисляет через строчку список нужных словарей в нужном ему порядке. И при запуске скрипта, пользователь выбирает уже не сами словари по одному с риском пропустить или щелкнуть не на том или еще чего, да и вообще это требует и время и сосредоточенность. А выбирает нужный ему плейлист, затем выбирает файл с книгой для обработки и процесс пошёл.
flegont писал(а): Вариант скрипта словарных замен с возможностью загрузки "плей-листа" с перечнем (через строчку) имен словарей. Плей-лист: текстовый файл с расширением .lst должен находиться в папке dic.
Замечание: файл плей-листа должен быть в кодировке ANSI.
Re: Общая тема
Добавлено: 27 июн 2018 19:30
Fenix
tonio_k писал(а):
Dec 21 2017
Как в Demagog сохранить книгу с разбивкой на несколько аудио файлов?
Лично мне "далеко не сразу" стало понятно, как сохранить книгу в MP3 с разбивкой на файлы с определенным временем звучания.
Так что для тех, кто с этим еще не разобрался:
Через меню
Сервис ->
Общие настройки делаем настройки в двух вкладках:
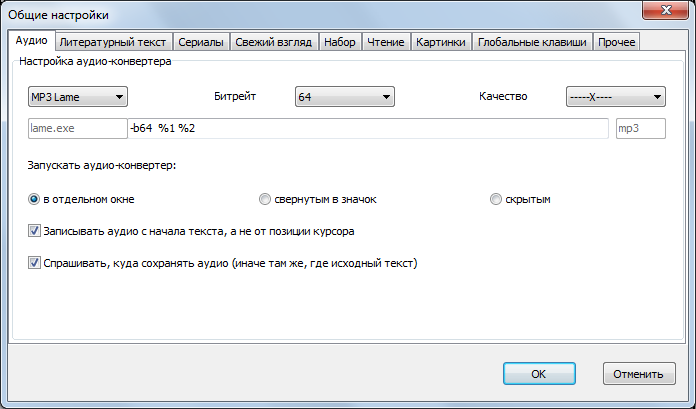
- audio1.png (44.7 КБ) 58782 просмотра
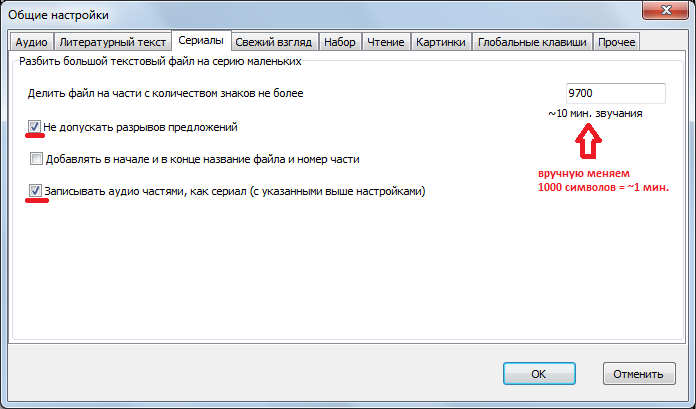
- series.png (43.9 КБ) 58782 просмотра
Далее как обычно: нажимаем
Записать аудио, указываем место сохранения. Ждем результата.
[...]
Пожелание к программе:
Хотелось бы иметь возможность при записи "Сериала" самому устанавливать с какого номера начинать нумерацию файла.
Это может понадобиться:
1) для продолжении записи книги, в случае, если что то прервало запись
2) для записи книги в 2 потока (путем открытия второго экземпляра программы)
ко 2 пункту добавлю: может скрипт такой сделать, что бы при его выборе Dmagog записывал книгу в 2 потока. Т.е. как обычно разбивал книгу на отрезки, а потом первый экземпляр программы записывал в mp3 нечетные отрезки, а второй экземпляр - четные.
Я брал маленький отрезок текста (112 кб) ставил запись - записал за 10м12с.
Этот же текст разбил (примерно) пополам по 56 кб каждый.
открыл 2 приложения одновременно открыл окно записи - запусти оба.
в итоге получилось 4м58с.
В балаболке 7м10с, а с 2 экз получилось за 3м45с
Балаболка быстрее демагога скорее из за разности в настройках записи mp3.
flegont писал(а):Двухпоточная" запись аудио двумя экземплярами Демагога - мысль интересная.
Интуитивно кажется, что в этом случае запись аудио произойдет вдвое быстрее.
А логика говорит, что ничего не изменится - в смысле затрат времени.
Гипотеза: на компьютере с 4 ядрами процессора - будет в 2 раза быстрее, чем на 2-х ядерном. И т.д. по аналогии
good_cat писал(а):Всё зависит от конфигурации компьютера. Если запустить запись одного и того же текста, на двух копиях программы одновременно, время записи фрагментов практически одинаково, а загрузка процессоров возрастает более чем вдвое.
Пример:
Файл 28175 байт
1 программа
Загрузка процессоров 16%.
Время записи - 27.547 c.
2 программы
Загрузка процессоров 33%.
Время записи - 27.625 c.
Время записи - 27.703 c.
Так что если запись загружает ЦП на 50%, то запускать второй поток вряд ли имеет смысл.
[...]
соотношение времени записи к времени воспроизведения приблизительно 1:13. При желании можно приблизительно прикидывать сколько займет запись книги.
Просто никто не поднимал этот вопрос. И кроме того есть одна альтернатива - можно начинать слушать MP3 не дожидаясь окончания оцифровки книги, что намного проще.
flegont писал(а):За 10 лет существования проекта Demagog - это второй раз, когда меня спрашивают: можно ли ускорить запись аудио за счет распараллеливания сего процесса. В первый раз (несколько лет назад) - я предложил пользователю поэкспериментировать с запуском двух копий Демагога и получил в ответ "большое спасибо!" Ну, значит, какой-то эффект был.
А сегодня tonio_k сам провел этот же эксперимент и получил удовлетворительные результаты.
Но, в некоторых случаях, я сам тому свидетель, эффект ускорения - нулевой.
Значит, ситуация на данный момент такая - кому как повезет. Учтите, что я, как автор Демагога, снимаю с себя ответственность за проблемы с компами/ноутами от подобных экспериментов mytts/ag 100% загрузки процессора - это, по любому, не есть хорошо.
Мне известны несколько программ (не TTS), в настройках которых пользователь может указать желаемое количество потоков, при некоей длительной обработке данных. При этом никакой гарантии не дается - всё на волю и ответственность пользователя.
Включать аналогичную опцию в Демагог считаю преждевременным. А там... будущее покажет.
good_cat писал(а):Может быть есть смысл в распараллеливании преобразования из WAV в MP3 при пакетной обработке файлов.
tonio_k писал(а):good_cat, - интересно!
В таком случае,так как в mp3 конвертируется намного быстрее чем wav создается, то на ЦП будет нагрузка под 100% пиково (эпизодически) что не так критично для ЦП, и на время записи может повлиять. Можно сделать bat.ник под lame кодак для мониторинга папки и посмотреть что это может дать.
[...]
Протестил у себя.
разбил текст 124 кб на 31 файл размером примерно по 4кб
создал и запустил bat файл. (lame.exe использовал тот что идет с Demagog)
Запустил Пакетную запись в Demagog
Варианты теста:
1) запись в mp3 в обычном режиме Demagog (в настройках качество записи среднее
-b64 %1 %2) время создания аудио =
7м 21с
график загруженности процессора (шкала 5 сек):
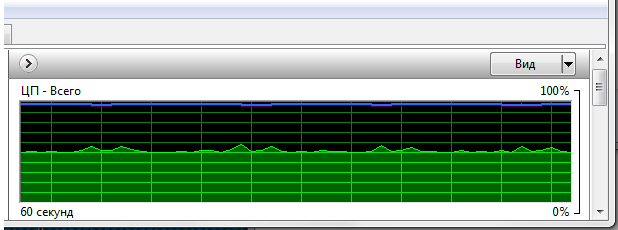
- aud1.png (15.05 КБ) 58782 просмотра
2) запись в WAV в обычном режиме Demagog с параллельно запущенным bat конвертирующий все найденые WAV файлы в mp3 (качество записи среднее
-b64 %1 %2) время создания аудио =
6м 02с
график загруженности процессора (шкала 5 сек):
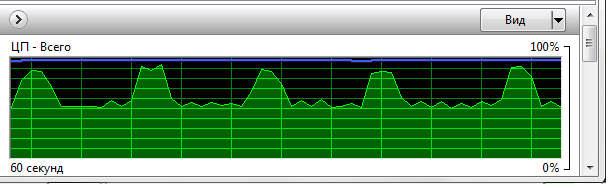
- aud2.png (13.84 КБ) 58782 просмотра
3) запись в mp3 в обычном режиме Demagog (в настройках качество записи Высокое
-b64 -h %1 %2) время создания аудио =
9м 38с
график загруженности процессора (шкала 5 сек):
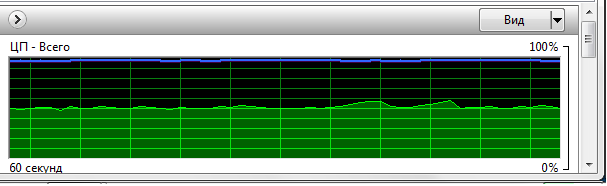
- aud3.png (12.44 КБ) 58782 просмотра
4) запись в WAV в обычном режиме Demagog с параллельно запущенным bat конвертирующий все найденые WAV файлы в mp3 (качество записи Высокое
-b64 -h %1 %2) время создания аудио =
6м 02с
график загруженности процессора (шкала 5 сек):
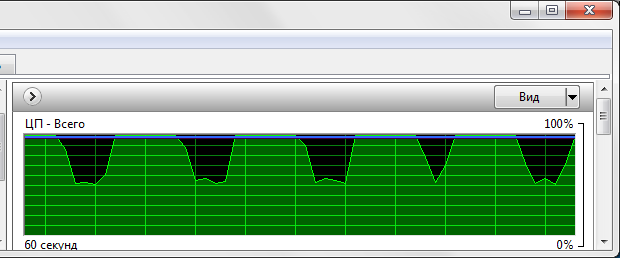
- aud4.png (21.05 КБ) 58782 просмотра
пункты 2 и 4 итоговая скорость записи
одинаковая
Вывод:
"
Параллельный способ" это максимальная скорость записи текста Demagog в WAV не больше и не меньше. При данном методе Конвертация в mp3 может быть исключена из времени конвертации ценой эпизодической нагрузки на ЦП при средних и малых настройках.
При высоких настройках ЦП находится (субьективно) долго в нагрузках. Итоговый прирост в скорости (на глазок) от 20% в зависимости от качества конвертации в настройках.
Re: Общая тема
Добавлено: 27 июн 2018 22:20
evmir_troll-hunter
tonio_k писал(а):Как в Demagog сохранить книгу с разбивкой на несколько аудио файлов?
Несколько советов:
- запускать аудио-конвертер лучше Скрытым - не будет отвлекать при просмотре фильма
- оптимальнее делить файл на ~6 минут
- отметить опцию Добавлять в начале и в конце название файла и номер части.
При копировании на карты памяти файлы часто перемешиваются, а на плеерах не всегда есть дисплей.
Название можно сократить... вместо "Путешествия в некоторые удалённые страны мира в четырёх частях: сочинение Лемюэля Гулливера, сначала хирурга, а затем капитана нескольких кораблей"  написать "Гулливер"
написать "Гулливер"
- Серии (части) будут сохраняться в папке с названием записываемого файла
- для записи в *.mp3 рекомендую fastencc.exe - аудио-конвертер в mp3, более быстрый, чем lame. Руководство пользователя - в архиве. Пример вызова как "Custom Encoder": fastencc.exe %1 %2 -br 40000
Битрейт можно и нужно подбирать для каждого голоса, иначе будет шипение или металлический отзвук.
Для Алёны битрейт - 40000 - *.wav пишется 07-08 сек. в *mp3 конвертирует 2 сек.
- demag1.jpg (68.15 КБ) 58782 просмотра
В 2015 я опубликовал
 Сравнительную статистику
Сравнительную статистику
из перечисленных файлов я записал лишь
all_Щедрин_ANCI.txt. Это полное собрание сочинений! Не уверен, что когда-нибудь составлю сборник поболе.
Точно я не помню, но процесс занял более 5ч.
При этом я на своём древнем (2007) ноуте развлекался как обычно - инет\скайп\фотошоп\аудиокниги\сериал...
При 100% работе процессора есть вероятность ошибок... вплоть до Синего экрана!
В серьёзных классических произведениях кроме примечаний существуют комментарии.
В бумажных это всё внизу стр. или в конце книги (2-й вариант мне никогда не нравился!

)
В электронных книгах сложился некий стандарт, строго поддерживаемый библиотекой
Либрусек и мощной программой для подготовки книг -
FictionBook Editor:
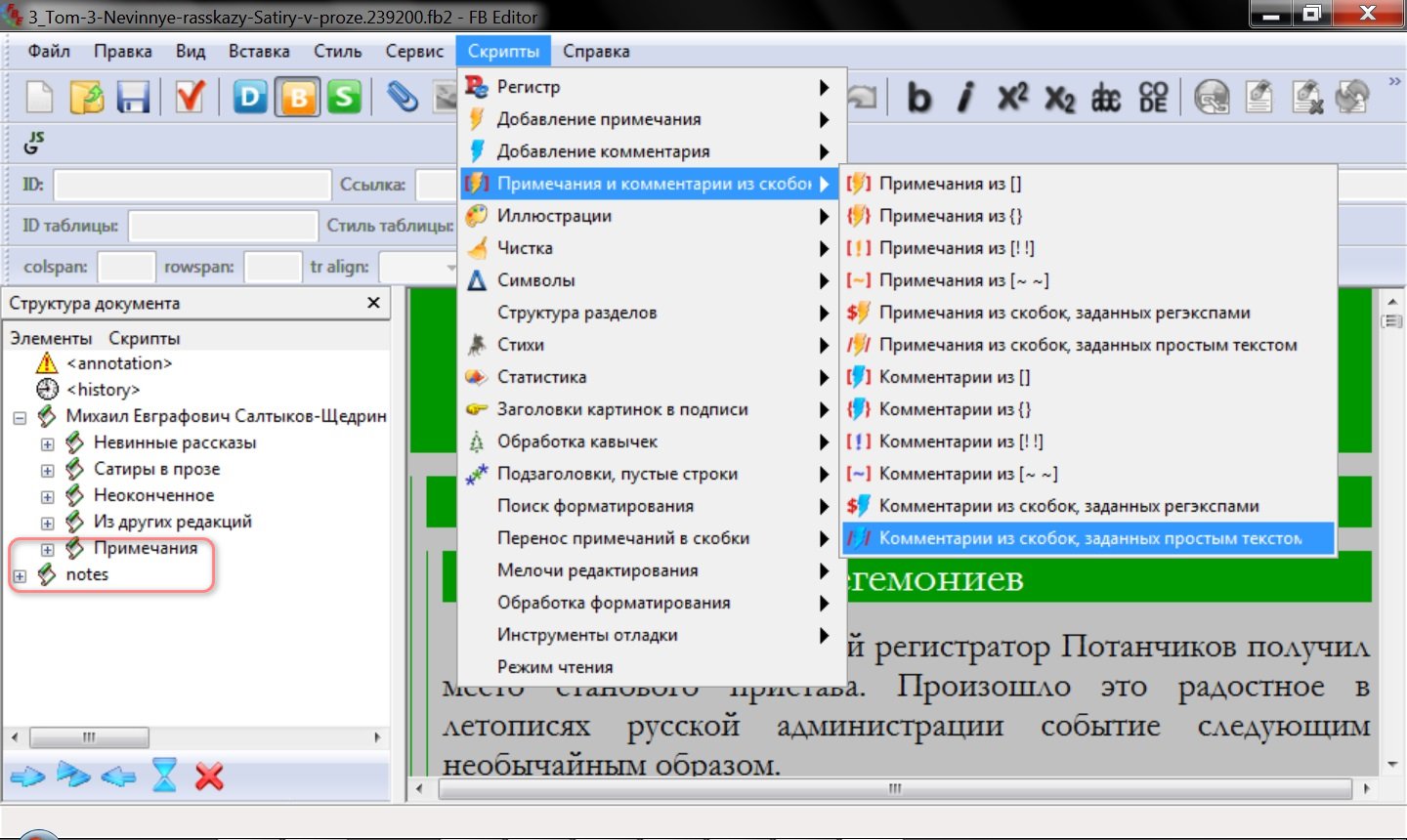
- fe1.jpg (190.31 КБ) 58782 просмотра
От составителя зависит какие сноски в какие скобки заключить, но для этих целей используются и [] и {}.
flegont писал(а):Когда Демагог разбирает форматы fb2 и epub, то примечания и комментарии помещаются в конце текста.
При этом, в самОм тексте: примечания (как правило, я заметил) обозначаются [nnn], а комментарии {nnn}, где nnn - номер, не более 3 знаков.
В принципе возможно - написать скрипт для встроенного интерпретатора, разбирающий такой текст, и вставляющий содержимое примечания/комментария прямо в скобки с нужным номером. Сами же примечания и комментарии в конце текста скрипт должен удалять.
[...]
evmir_troll-hunter писал(а):Да, теперь отлично и быстро - спасибо!.. 725 примечаний, 133 комментария, 83 секунды на обработку.
Вопросы; правила \[(\d+)(.+)\]=[Примечание: $2 Конец примечания.] \{(\d+)(.+)\}=[Комментарий: $2 Конец комментария.] мне понравились, но хочется точности... чтобы прописывался № сноски - Примечание\Комментарий 1, 2, 3 и т. д.
Как это сформулировать в данных рег. выражениях?
В конце notes.re есть строки - #\.\]\x20{0,1}\.=.] #\.\]\x20{0,1}\,=], для чего они?
Ответ на 1-й вопрос:
\[(\d+)(.+)\]=[Примечание $1: $2 Конец примечания.]
\{(\d+)(.+)\}=[Комментарий $1: $2 Конец комментария.]
Ответ на 2-й вопрос:
Бывает, что тексты примечаний заканчиваются точками. После вставки примечаний в текст иногда возникают такие комбинации:
[Текст примечания
.].
[Текст примечания
.],
Некрасиво. Не понятно, как голосовой движок отреагирует. На всякий случай, лишнюю точку убираем.
Впрочем, это мое личное мнение. Тут только на опыте можно убедиться, что лишние точки чтению не мешают, и тогда эти два правила не нужны.
[...]
Кстати, правила постобработки в notes.re можно записать так, чтобы, по ходу дела, сразу исключать квадратные и фигурные скобки, обрамляющие текст примечаний/комментариев:
#Postprocessing#
\[(\d+)(.+)\]=Примечание $1: $2 Конец примечания.
\{(\d+)(.+)\}=Комментарий $1: $2 Конец комментария.
\[(\d+)(.+)\]=Note $1: $2 End of note.
\{(\d+)(.+)\}=Comment $1: $2 End of comment.
\[=
\]=
\{=
\}=
\.\,=.
Остальные 4 короткие правила удалят прочие фиг/квадр скобки, если они были в тексте (и не являлись обозначениями номеров примечаний/комментариев).
Последнее правило удалит везде запятую после точки.
Demagog TTS
Добавлено: 27 июн 2018 22:41
Fenix
flegont писал(а):Как в Демагоге увидеть невидимые символы?
Код символа, стоящего сразу за текстовым курсором показывается в Строке состояния, в десятичном и 16-ричном виде.
В присланном мне тексте в некоторых местах вместо пробела (#32) стоит
неразрывный пробел (#160),
т.н. "ПРОСТРАНСТВО". Этот символ является своеобразной невидимой буквой и служит для типографских целей; не позволяет делать разрядку пробелами, чтобы не отрывать тире от следующей за ним прямой речи.
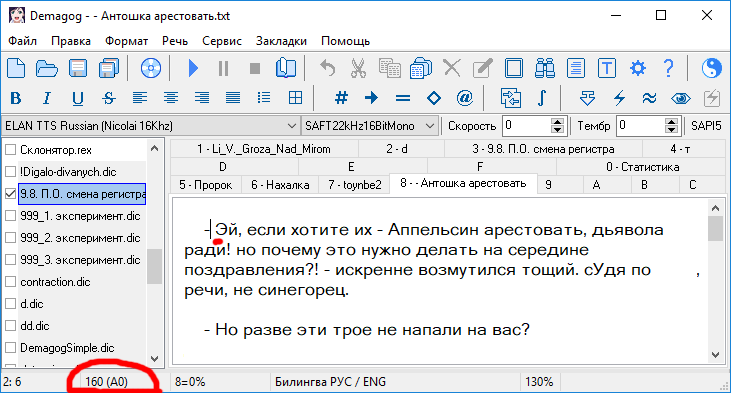
- demago6.gif (24.35 КБ) 58870 просмотров
В тексте нет слова
Эй,
В нем есть слово
-#160Эй,
Такое слово, естественно, предложенным словарем не обрабатывается.
Лечение:
"Правка - Найти / Заменить - Заменить". Режим поиска: "расширенный". Текст для поиска: #160 . Вместо текста для замены ввести один пробел. Нажать кнопку "Заменить все".
После этого словарик отработает штатно.
flegont писал(а): Mar 20 2018
В тексте "Ссыльнопоселенец.txt" во многих местах, вместо пробела (код 32) стоИт символ "пространство" с кодом 160 - т.н.
неразрывный пробел.
Для чего он нужен? Для "типографских" целей иногда необходимо два слова превратить в одно, чтобы при форматировании они не разрежались пробелами. Так делает, например, Word, вставляя "пространство" вместо пробела между символом "тире" (код 150) и следующим за ним словом.
Как результат, имеем проблему.
Например, старичок Николай Еланович Дигало читает вот этот фрагмент
– Какой балдеж! – вытягиваясь в почти горячей воде, пробормотал я.
так:
–ПРОСТРАНСТВОКакой балдеж!ПРОСТРАНСТВО– вытягиваясь вПРОСТРАНСТВОпочти горячей воде, пробормотал я.
Как видим: начиная с тире и заканчивая им - текст формально слепился в одно слово, в котором "пространство" играет роль специфической буквы, имеющей вид пробела. Такого ужасного слова в словаре нет.
Балаболка по умолчанию заменяет "пространство" обычным пробелом при открытии файла.
Демагог предоставляет это пользователю:
"Правка - Найти / Заменить - Заменить". Режим поиска: "расширенный". Текст для поиска: #160 . Вместо текста для замены ввести один пробел. Нажать кнопку "Заменить все".
После этого количество Ё-замен в указанном тексте равно 768.
Не срабатывает лишь одна замена по правилу
пятеркой=пятёркой
поскольку
дробью-«пятеркой»
для Балаболки - это 2 отдельных слова, а для Демагога -
одно.
Причина в том, что разделителями слов в Демагоге являются только пробел, табуляция и перенос строки.
P.S. Кстати, вместо огромного количества словоформ в Ё.dic с корнем "балдеж", ИМХО, достаточно одного правила:
*балдеж*=балдёж
Словарь, при этом, будет работать лучше, захватывая и такие, непредсказуемые заранее словоформы, как "архинаибалдежнейший"

Это относится и к многим другим наборам словоформ.
[...]
Раз уж речь зашла о словарях, не могу не обратить внимание на один глубоко спрятанный капкан, в который рано или поздно попадает каждый 
Правила в словарях .dic и .rex имеют следующий формат:
шаблон=замена
Следовательно, сам шаблон
не может содержать в своем составе знак равенства - иначе правило будет интерпретировано неверно. Примеры:
DIC (попытка заменить в тексте знаки <= их математическим определением)
<==меньше или равно
REX (здесь комбинация ?<= является элементом синтаксиса регулярных выражений)
(?<=\bпро)сто\b=сто так
Для разрешения подобной коллизии со знаком
=, в Демагоге, для разделения левой и правой части правила можно использовать комбинацию
:: (двойное многоточие).
Вот:
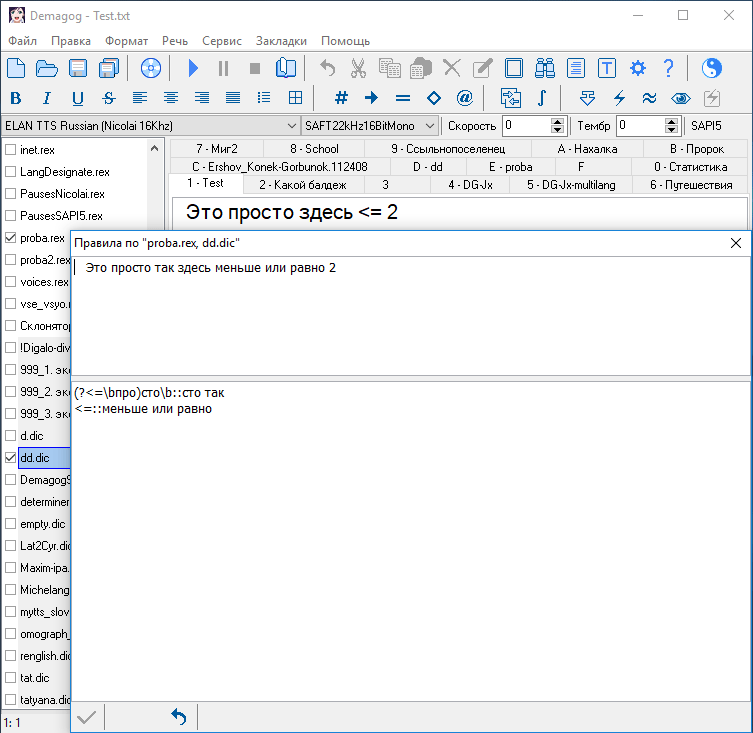
- demago5.gif (27.29 КБ) 58870 просмотров
[...]
tonio_k писал(а):Чисто теоретический вопрос:
Интересно, а если словари DIC , REX как нибудь адаптировать под скрипт для демагога. Как бы он быстро/медленно и ресурсоемко бы их отрабатывал?
Меня самого интересует этот вопрос.
Что, если написать скрипт для словарных замен, который не обращался бы к соответствующим процедурам Демагога, а всё делал бы сам? Например, замены в тексте по правилам словарей DIC?
(С REX он не справится, в нем нет поддержки регулярных выражений)
При всем при том,
язык Lua отличается необычайной шустростью в обработке больших (и даже очень больших) строк.
От экспериментов удерживает лишь одно серьезное обстоятельство.
Lua -
не поддерживает Юникод.
В любой стране, на любой версии Windows ему доступны лишь 2 алфавита: английский и местная локаль.
Т.е. для нас - это английский+русский.
Следовательно, lua-скрипт не смог бы сам выполнять замены в тексте со вставкой тега phoneme,
содержащего транскрипцию IPA
С транскрипцией UPS в теге pron SAPI5 - он бы справился - она - машиночитаемая.
Но... мне больше нравится IPA - она
человекочитаемая!
Таковы серьезные обстоятельства, снижающие мой энтузиазм в отношении lua-скрипта для непосредственных словарных замен.
Именно поэтому словарные замены скрипт Pronunciation adjustment.lua делает путем вызова процедур Демагога. Уж Демагогу-то юникод доступен.
[...]
tonio_k писал(а):по такой схеме файл словаря может уменьшится примерно 3 к 1 что облегчает его загрузку.
И вот вопрос: какие правила Демагог быстрее обрабатывает: список из целых слов или их заменяющий шаблон со звёздочкой?
Когда-то давно, я проводил хронометраж на очень слабом компьютере. Словари в которых вообще нет $ и * Демагог обрабатывает на 40% быстрее.
Но, если реорганизованный словарь "зазвездившись", стал в 3 раза меньше... !!! то, по идее, он не должен стать более тормозным, чем без *. Экономия в скорости за счет уменьшения в разы, должна превысить 40%-е торможение от наличия *
Такие вот теоретические рассуждения.
На практике, на современных компах разницы я не замечал вообще.
Re: Общая тема
Добавлено: 28 июн 2018 05:14
evmir_troll-hunter
flegont писал(а):+ Окно Закладок - теперь не модальное, изменяемого размера.
Теперь у меня это выглядит так:
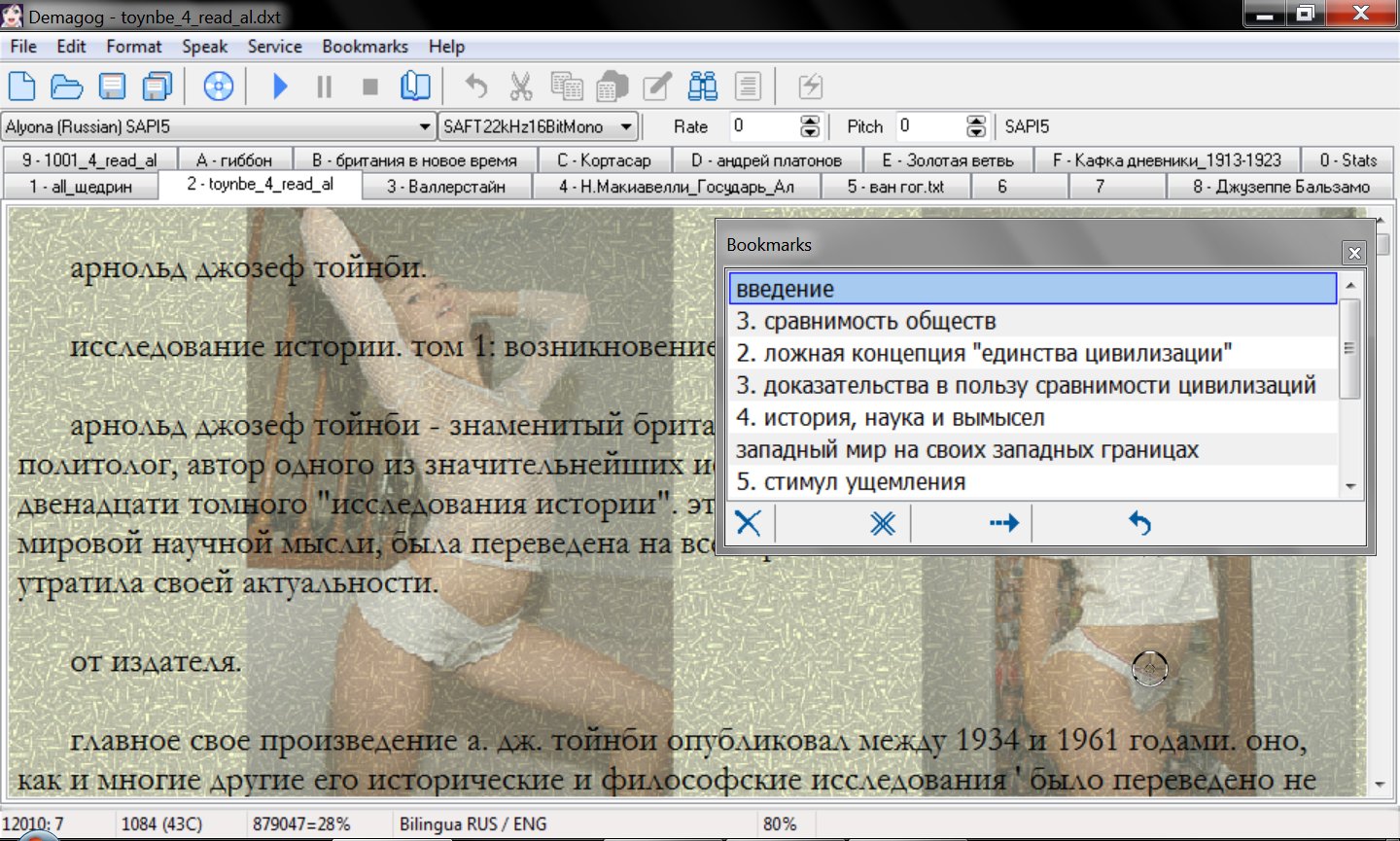
- dem6.jpg (297.07 КБ) 58781 просмотр
Мне закладки нужны для возврата на ключевую точку (если задремал или отвлёкся.)

Поэтому хотелось максимального комфорта\оптимальности... и получил что-то более привычное и практичное.
Дело в том, что сейчас всё выглядит почти как в
foobar2000, коим я активно пользуюсь. Но намного лучше т. к. Демагог в закладках пишет слова\предложения, а плеер лишь названия плейлистов и время.
Спасибо автору за реализацию!
Re: Общая тема
Добавлено: 02 июл 2018 17:10
tonio_k
В Демагоге есть функция "выключить ПК" после окончания записи в аудио?
Re: Общая тема
Добавлено: 02 июл 2018 19:06
flegont
Нет.
Re: Общая тема
Добавлено: 03 июл 2018 15:57
tonio_k
Версия 7.29.343
Протестировал. Прямой перебор - работает. Все хорошо. Спасибо большое!

Есть замечания по поиску:
1) при выборе шаблона, при клике (двойной щелчок, enter, стрелочка) нужно, что бы этот клик активировал окно поиска - как бы вызывал это окно поиска.
2) закрытие окна поиска оставляет висеть открытым окно шаблона. Думаю закрытие окна поиска должно закрывать все его дополнительные окна.
3) думаю не лишним было бы сделать дополнительное отдельно редактируемое текстовое поле - "комментарий" напротив каждого шаблона.
4) по мере накопления шаблонов, бывает так, что какой то шаблон стал чаще применяться. Может возникнуть желание его поднять наверх. Как это можно будет сделать?
Re: Общая тема
Добавлено: 03 июл 2018 16:56
flegont
1) т.е. Enter или DblClick, помещая шаблон в Окно поиска, одновременно переводил бы фокус на Окно поиска. Так?
2) да, я тоже заметил. Поправлю в след. версии
3) от коротких комментариев толку мало, а длинные - сильно увеличат ширину окна шаблонов. Потому я отказался от этого.
4) возможно, в след. версии в окне шаблонов внизу добавятся 2 кнопки: переместить строку вверх / вниз. А пока что, если есть желание серьезно перетряхнуть список накопившихся шаблонов, то ..\profiles\search.lst. Редактируйте, как Вам угодно.
Код- префикс перед шаблоном составляется по правилу:
N - обычный поиск
NC - обычный с учетом регистра
NW - обычный, только целые слова
NCW - обычный, с учетом регистра, только целые слова
E - расширенный поиск, можно вводить коды символов, например: #13
EC - расширенный, с учетом регистра
D - шаблон dic
R - шаблон rex
F... - нечеткий поиск, после буквы F указывается требуемый процент сходства, например: F65
Код-префикс отделяется от шаблона пробелом
Шаблон - это правило вида:
что ищем=на что заменяем
или
что ищем::на что заменяем
Если шаблон только для поиска, то:
что ищем=_SEARCH_ONLY_
Следуя этому стандарту, базу шаблонов search.lst можно создать почти так же, как мы создаем словари - как обычный (ну, не совсем) текст
Re: Общая тема
Добавлено: 03 июл 2018 23:06
tonio_k
1) т.е. Enter или DblClick, помещая шаблон в Окно поиска, одновременно переводил бы фокус на Окно поиска. Так?
- Да
Re: Общая тема
Добавлено: 03 июл 2018 23:09
flegont
Ясно. В следующей версии будет.
Re: Общая тема
Добавлено: 04 июл 2018 12:58
tonio_k
Сервис-Общие настройки-Сериалы-Добавлять в начале и конце название файла и номера части
Скажите пожалуйста, а есть возможность расширить эту возможность за счет, например, скрипта?
Что бы я имел возможность прописать в этом скрипте любую текстовую строку в начале и/или в конце каждого файла из сериала, при этом, что бы был реализован счетчик с номером, который я мог бы вставить в любое место выше указанной текстовой строки.
Схематично в скрипте водятся такие переменные:
SCHETCHIK=1 'Начало нумерации'
TEXT_AP='Блок номер' SCHETCHIK 'моя книга'
TEXT_END='Конец Блока номер' SCHETCHIK 'моя книга'
На выходе получается:
Блок номер 1 моя книга
тексттексттексттексттексттексттексттекст
тексттексттексттексттексттексттексттекст
...
тексттексттексттексттексттексттексттекст
Конец Блока номер 1 моя книга
и так в каждом блоке с изменением только переменной SCHETCHIK=SCHETCHIK+1
Re: Общая тема
Добавлено: 04 июл 2018 16:38
flegont
Вообще-то, шаблоны начальной и конечной строки в серии, изначально заданы в файле настроек $.cfg. Но в программе пользователю они не видны и недоступны для редактирования. Могу и открыть доступ, в следующей версии. В панели "Сервис - Общие настройки - Сериалы". После пунка "Добавлять в начале и конце..." будет окошко для редактирования начального номера (сейчас всегда 1) и шаблонов начальной и конечной фразы.
Любой текст, в котором %1 - это будет имя файла, а %2 - значение счетчика.
Re: Общая тема
Добавлено: 04 июл 2018 22:41
evmir_troll-hunter
Шаблоны начальной и конечной фразы я когда-то изменял в английском языковом файле - там строки:
[Msg_YouListen]
C="%s". Series %d.
[Msg_YouListened]
C="%s". End of series %d.
Мне нужно было чтобы начало каждого блока звучало на 60% тише. Поэтому подключал Хизер Акапела с необходимыми настройками.
Суть: Хизер тихонько проговаривает название сборника и слово "
series", потом уже Алёна орёт № серии.

P.S. и никаких блоков!.. в Демагоге серии - только серии.
Re: Общая тема
Добавлено: 05 июл 2018 12:02
flegont
В следующей версии этот прием, с правкой секций [Msg_YouListen], [Msg_YouListened] уже не будет работать. Но в настройках будет доступна аналогичная опция, можно будет ввести начальный номер серии (по умолчанию 1) и отредактировать шаблоны, по умолчанию они такие:
"%1". Serie %2
"%1". End of serie %2
При наведении мышью на поля ввода, появятся всплывающие подсказки, объясняющие, что %1 - это имя файла, а %2 - номер серии.
А прежние 2 секции в настройках станут не нужны, программа перестанет к ним обращаться и их можно просто удалить из $.cfg:
[Msg_YouListen]
C="%s". Series %d.
[Msg_YouListened]
C="%s". End of series %d.
Или же, при удалении самого файла $.cfg, при новом запуске программы, он будет создан заново, с настройками по умолчанию, и без этих ненужных секций.
Re: Общая тема
Добавлено: 06 июл 2018 16:37
tonio_k
Для выявления ошибок и оптимизании словарей *.DIC такое пожелание:
сделать "Поиск дубликатов в словре"
Поиск дублей должен происходить по левой части правила, причем, знак $ не должен учитываться - т.е. $Обо всем= и обо всем= должны отбираться как дубликаты.
Таким образом должны выявиться одинаковые правила, а так же дубликаты правил, имеющие разные результаты замен типа:
о всем=о всЁм
о всем=о всём
$О всем=о всём
Рассмотрите такой алгоритм работы поиска замен:
При запуске поиска дубликатов,создается словарь в папке DIC с таким же названием, но с добавлением в название _duplicate. Все дублирующие между собой правила переносятся (с удалением в оригинале) в новый словарь_duplicate. (Тут важно что бы не было перезаписи. Пока пользователь не удалит старый файл словарь_duplicate результаты не должны записываться что бы не было потерь ранее сохранённых словарь_duplicate)
Дальше пользователь работает с новым словарем: оставляет нужные и уникальные правила. После чего результаты можно вручную перенести в основной словарь и удалить словарь_duplicate
В случае отсутствия дубликатов - новый словарь не создается. Выводится сообщение: "дубликаты не найдены".
В Словаре _duplicate правила должны быть отсортированны так, что бы парные дубликаты находились друг за другом - для удобства сравнения. Причем правила начинающиеся с $ вначале правила не должны улетать куда нибудь вниз/вверх словаря, а быть рядом со своими дубликатами.
Re: Общая тема
Добавлено: 06 июл 2018 19:49
flegont
Всё вышесказанное можно изложить одной фразой:
Два правила являются дубликатами, если их левые части совпадают, независимо от регистра
Это определение, по-моему, заведомо не полное.
Вот некий список правил. Последнее правило, выделенное красным - является ли дубликатом для всех вышеперечисленных? Если нет, то почему? Если да, но не для всех - тоже, почему?
туника=тунИка
туники=тунИки
туник=тунИк
туниками=тунИками
...
(далее следует куча словоформ от слова "туника", а затем одно единственное правило...)
...
туник*=тунИк
Re: Общая тема
Добавлено: 06 июл 2018 20:28
tonio_k
Тогда может разделить на два пункта?
Красные Звёзды отдельно, черные туники отдельно?
1) Прямой способ (Два правила являются дубликатами, если их левые части совпадают, независимо от регистра - из выборки исключаются правила со звёздами
2) Расширенный способ - Звёзды плюс первый пункт.
Тогда правило со звездами должно быть выше его"дубликатов" для наглядности.
Почистив словарь по первому пункту, мы сможем оптимизировать словарь по "расширным способом" - убрав правила, которые уже не обязательны, так как для них есть правило со звездой.
Почему стоит разделить на 2 пункта? Выполнив чистку по первому пункту, размер полотна, возникающие только по второму пункту будет намного меньше и в нем легче мониторить возможные "исключения"
Re: Общая тема
Добавлено: 06 июл 2018 20:57
flegont
Хм... Похоже, что
два правила являются дубликатами, если существует слово или словосочетание, на котором срабатывают левые части обоих этих правил
Re: Общая тема
Добавлено: 06 июл 2018 21:04
tonio_k
Причем правило со звездой может или не может иметь дубликат, а вот полное слово не может иметь дубликат в правиле со звездой.
тунИк* есть в тунИка, но тунИки нет в тунИк*
это в плане что брать за шаблон поиска.
Re: Общая тема
Добавлено: 06 июл 2018 21:07
flegont
Да уж. Дубликатность - не коммутативна. Прямо, как любовь: он ее любит, а она его - нет

Re: Общая тема
Добавлено: 09 июл 2018 00:16
MDenis2
Что-то не найду как настроить паузу между предложениями и абзацами. Такое в Демагоге есть?
Спасибо.
Re: Общая тема
Добавлено: 09 июл 2018 09:37
flegont
Как отдельная опция в меню - нет.
Вставку пауз в текст можно cделать применением словаря, вставляющего в нужные места тег паузы вместо (или после) какого-либо знака препинания. Например, вот такое правило в словаре типа DIC вставит полусекундную паузу вместо трех точек:
*...*=<silence msec="500"/>
Более гибкие правила настройки пауз можно составлять с помощью регулярных выражений в словарях типа REX. Например, внедрять в текст паузу и/или снижение громкости для фрагмента в скобках или кавычках. И т.д. и т. п. Для разных языков могут быть свои правила "стильной речи".
Насколько помню, где-то здесь на Форуме есть даже REX- словарь для разметки прямой речи персонажей.
P.S. Демагог поддерживает регулярные выражения стандарта PCRE - Perl Compatible Regular Expression.
Общая тема
Добавлено: 11 июл 2018 00:29
tonio_k
В Демагоге нет функции выключения ПК после записи книги

. А можно сделать кое что другое? Более простое, но с расширенными возможностями:
В настройках записи аудио добавить галочку и текстовое поле:
Выполнить cmd команду после окончания записи аудио. Где пользователь может вручную внести свою команду

например:
shutdown /s -выключение компьютера, или указать путь к запуску сторонней программы, или запустить командный файл *.bat
При этом, что бы можно было выбрать два варианта:
1)всегда выполнять по окончании записи аудио.
2)выполнить по окончании записи аудио только в текущей сессии. (т.е. после перезапуска Демагога выполнять уже не будет).
Соответственно, что бы эту галочку можно было активировать на любом этапе процесса записи аудио для его срабатывания - Поставил на запись в mp3, зашёл в настройки, активировал галочку, пошел спать.
Запись закончилась, ПК выключился.
Общая тема
Добавлено: 11 июл 2018 08:48
flegont
Подумаю над этим.
Общая тема
Добавлено: 11 июл 2018 09:56
flegont
Оказывается, я недостаточно хорошо знаю свою собственную программу

И в действующей версии есть возможность выключать компьютер после записи аудио.
Если записывать аудио через такой, например, lua-скрипт (на моем компе c Win 10 сработало на ура):
-- Пример скрипта для программы Demagog
-- Запись аудио с выключением компьютера
-- выбрать документ
fname = OpenDialog()
if not fname then goto HALT end
-- открыть документ в окне 1 и записать аудио
WOpen(1,fname)
WAudio(1)
-- выключить компьютер
os.execute('shutdown /s')
::HALT::
Общая тема
Добавлено: 11 июл 2018 10:26
tonio_k
Отлично!
. Попробую. Однако, Часто бывает, что сначала поставил на запись, а потом спохватился, что что то долго ждать... И в этот момент бы (в догонку) указать, что надо выключить ПК по завершению. Может тогда в настройках вместо выполнить cmd команду по завершению - указать какой скрип выполнить по завершению?
Откорректирую свою мысль. Создав сразу два скрипта - один без выключения, другой с выключением ПК и заимев привычку записывать аудио только через них, выбор между этими скриптами уже будет напоминанием что есть возможность записать аудио с выключением ПК по окончанию, и "спохватился" уже не должно возникнуть.
Общая тема
Добавлено: 11 июл 2018 11:04
flegont
Можно и один скрипт, со стартовым вопросом: "Выключить компьютер после записи аудио?"
Общая тема
Добавлено: 11 июл 2018 14:35
tonio_k
flegont писал(а): ↑11 июл 2018 11:04
Можно и один скрипт, со стартовым вопросом: "Выключить компьютер после записи аудио?"
Помогите прописать стартовый вопрос к следующему блоку (запись в аудио текущего окна)
ShowMessage('После записи аудио, ПК будет выключен!')
ind = WActive() -- получить номер текущего окна
WAudio(ind) -- записать в аудио текущее окно
os.execute('shutdown /s')-- выключить компьютер
что бы вопрос включал ответы ДА, НЕТ, Отменить.
Общая тема
Добавлено: 11 июл 2018 15:30
flegont
-- Пример скрипта для программы Demagog
-- Запись аудио с выключением компьютера
cap = 'Выключить компьтер после записи аудио?'
itms = {' ДА',' НЕТ'}
a = Menu(cap,itms)
if a == 0 then goto HALT end
if a == 1 then
ShowMessage('После записи аудио, ПК будет выключен!')
end
-- выбрать документ
fname = OpenDialog()
if not fname then goto HALT end
-- открыть документ в текущем окне и записать аудио
ind = WActive()
WOpen(ind,fname)
WAudio(ind)
if a == 1 then
os.execute('shutdown /s') -- выключить компьютер
end
::HALT::
-- Замечание. Функция Menu показывает окно меню с назначенными пунктами для выбора.
-- На самой форме меню имеются также кнопки OK и Отменить
Общая тема
Добавлено: 12 июл 2018 01:44
tonio_k
на этапе WAudio(ind) в случае, если пользователь закроет через [Х] окно выбора папки для сохранения аудио - без выбора папки, как прописать, что бы скрипт прервался? Иначе, (при выборе "выключить ПК") - сразу идет выключение ПК.
Общая тема
Добавлено: 12 июл 2018 09:29
flegont
Пока никак. Скрипт ничего не знает об отказе пользователя. В следующей версии подправлю функцию WAudio. Чтобы она возвращала значение, указывающее: подтвердил ли пользователь запись аудио или отказался? Тогда, по этому значению можно будет в скрипте выполнять пропуск команды выключения ПК.
Общая тема
Добавлено: 13 июл 2018 00:08
tonio_k
► Показать
flegont писал(а): ↑06 июл 2018 20:57
flegont » 06 июл 2018, 20:57
Хм... Похоже, что
два правила являются дубликатами, если существует слово или словосочетание, на котором срабатывают левые части обоих этих правил
В том архиве Демагог, который я раннее вам скидывал для эксперимента через Excel вывел около 2400 дублирующих записей типа:
► Показать
юридические проволочки=юридические проволОчки
юридические проволочки=юридИческие проволОчки
юридическими проволочками=юридическими проволОчками
юридическими проволочками=юридИческими проволОчками
этому набегу=этому набЕгу
этому набегу=Этому набЕгу
это не решает дела=это не решает дЕла
это не решает дела=это не решАет дЕла
это все жара=это всё жарА
это все жара=это всЁ жара
это все жара=это всЁ жарА
это все из за=это всЁ изза
это все из за=это всЁ иззА
это все слова=это всё словА
это все слова=это всЁ словА
это ещё не все.=это ещё не всЁ.
это ещЁ не все.=это ещЁ не всЁ.
Эти записи переместил (с удалением в оригинале) в отдельный dic файл и занялся построчно их прослушиванием и удалением ненужных либо неверных записей. Эти дубликаты, возможно, возникли при моих старых экспериментах со словарями - пакетными преобразованиями. Зато этот пример может вам дать представление о том, какой мусор по объему может скопиться в словарях и почему поиск дубликатов по левой части правил может пригодиться.
Вопрос. Например правило:
берет на пушку=берёт на пУшку
Находясь в окне словаря
50_ОМОГРАФЫ.dic и с активироваными (только) словарями фонем:
70.ФОНЕМЫ Dopolneniya строчные.dic и
79.ФОНЕМЫ.dic, как можно прослушать звучание левой и правой части правила
с учетом активированных словарей фонем?
Пробовал скопировать правую часть правила в буфер обмена и озвучить F9, но сюрприз в том, что если в Демагоге активно окно словаря 50_ОМОГРАФЫ, то буфер обмена читает так, как будто словари с фонемами не активны, а стоит активировать любое другое окно Демагога - буфер читает уже с учетом словарей фонем.
В старой версии Максима такой проблемы не было, так как фонемы прописывались в словарях PLS в самом голосовом движке. С новой версией Максима фонемы прописаны в словарях DIC и проблема с озвучкой в самом словаре теперь требует пересмотра.
Можно, конечно, скопировать содержимое/строку из словаря, вставить в новое окно, прослушать, откорректировать и вернуть на место... Но как то это.. неправильно что ли.
Общая тема
Добавлено: 13 июл 2018 09:07
flegont
Пока останется, как есть - активные словари действуют на любые тексты,
кроме текстов, являющихся словарями. (Определяется по расширению имени файла: .dic или .rex )
Решение не самое лучшее, но...
Я уже достаточно намучился с проблемами, когда правишь словарь, недоумевая, почему все правки не дают должного результата. А через пару-тройку часов вдруг соображаешь, что произношение данного словаря портится другим словарем, в это время активным!

Общая тема
Добавлено: 13 июл 2018 09:39
flegont
юридические проволочки
Спасибо за пример, но, вообще-то, я уже в курсе.
► Показать
# Орфография "50_ОМОГРАФЫ.dic"
все как нельзя лучше складывалось=все как нельзя лучше складывалось
шанс найти чего то стОящее есть=шанс найти чего то стОящее есть
шанс найти что то стОящее есть=шанс найти что то стОящее есть
все как то не приходившийся=все как то не приходившийся
в длинное деревянное остриё=в длинное деревянное остриё
все в конечном счёте придёт=все в конечном счёте придёт
сделал все как вы приказали=сделал все как вы приказали
правильно ли они все делают=правильно ли они все делают
тянувшуюся от ковра верёвку=тянувшуюся от ковра верёвку
все как то чересчур гладко=все как то чересчур гладко
...
при чем=при чЁм
при чем=при чём
к копью=к копьЮ
к копью=к копьё
на всем=на всЁм
на всем=на всём
о, черт=о, чЁрт
о, черт=О, чёрт
о черте=о чЁрте
о черте=о чёрте
в щеки=в щёки
в щеки=в щЁки
в полу=в полУ
в полу=в полв полуденном небе
в щеку=в щЁку
в щеку=в щёку
на ухо=нАухо
на ухо=на Ухо
на фиг=нАфиг
на фиг=нафиг
за нос=зАнос
за нос=занос
...
Мне требуется время, чтобы доработать "Проверку словарей Dic", но я сейчас в отпуске

Поэтому, ближайшая новая версия выйдет, пока что, без этой опции.
Общая тема
Добавлено: 14 июл 2018 06:36
wasyaka
tonio_k писал(а): ↑13 июл 2018 00:08
Можно, конечно, скопировать содержимое/строку из словаря, вставить в новое окно, прослушать, откорректировать и вернуть на место... Но как то это.. неправильно что ли
Меняеш dic на txt исправляеш при вкл подсветке омографов (бывает их там и нет
) и после всех манипуляций - назад на dic
Общая тема
Добавлено: 14 июл 2018 13:06
tonio_k
wasyaka, когда нужно проверить такую кучу правил, то, конечно, удобнее создать отдельный текстовый файл перенести туда правила и по одному прослушивать

. Но когда добавляются правила по мере их возникновения по 1-5 штук. То создавать/переименовать и делать прочие финты руками уже не так оптимально. Хочется просто добавить правило в dic, в нём же его прослушать и бежать дальше.

Общая тема
Добавлено: 14 июл 2018 13:28
tonio_k
flegont,
► Показать
flegont писал(а): ↑13 июл 2018 09:07
Пока останется, как есть - активные словари действуют на любые тексты, кроме текстов, являющихся словарями.
может дать пользователю волшебную палочку в настройках программы, с помощью которой он сможет отключать эту защиту?

А уж что он наколдует - это на его ответственности?

Общая тема
Добавлено: 14 июл 2018 13:52
good_cat
Вспоминая детскую книгу Николая Носова "Незнайка в Солнечном городе" я не рекомендовал бы это делать...
Общая тема
Добавлено: 14 июл 2018 18:52
flegont
Если нужно проверить одно (или пару-тройку) новоизобретенных правил, при том с учетом влияния других словарей...
Ничто не мешает записать это правило в любом свободном окне, и даже сохранять НЕ надо. Включаем прослушку, и правило будет прочитано с учетом всех подключенных словарей.
Устраивает? Копипаст в словарь, открытый в любом другом окне.
Не годится? Исправили и слушаем снова.
Закончили творческую работу, закрываем программу - появляется запрос: сохранять ли текст в том самом экспериментальном окне? Ответ: нет, и все дела

P.S. "Незнайка в Солнечном городе" - очень смешная и поучительная книжка

Общая тема
Добавлено: 14 июл 2018 18:59
tonio_k
Сдаюсь.

Общая тема
Добавлено: 15 июл 2018 23:46
tonio_k
flegont, в режиме подсветки омографов не работает Ctrl+Z (отменить последнее действие)
Общая тема
Добавлено: 16 июл 2018 10:05
flegont
Да - при включенной подсветке хот-кей Ctrl+Z - отключен, чтобы опция "отмена последнего действия" не конфликтовала с подсветкой. Удастся или нет мне эту проблему решить - будущее покажет.
Общая тема
Добавлено: 16 июл 2018 22:46
wasyaka
Скрипт Fragments with numbers.lua(фразы с цифрами) выдаёт цельный абзац из нескольких предложений с одной цифрой и для проверки-дополнения словарём "числа" или ему подобным очень не удобно.
► Показать
© Михаил Алексеев, 2018
© ООО «Издательство АСТ», 2018
23 сентября 1941 года.
Штаб 1-й Ударной армии. Александрино
Командующий 1-й Ударной армией Герой Советского Союза генерал-лейтенант Оганян надевал парадный мундир, который он все же заказал и сшил в этом времени. Не хотелось ему отставать от своего товарища – уже генерал-майора Красавина, у которого мундир уже был. Тоже, кстати, Героя Советского Союза. После окончания Белорусской оборонительной операции на оба Особых корпуса – и воздушный, и общевойсковой – пролился наградной дождь.
Штаб формируемой армии располагался в имении князей Волконских, расположенном в тридцати километрах севернее Вязьмы, неподалеку от разъезда Касня. Из истории Иосиф Бакратович помнил, что именно здесь располагался штаб Западного фронта генерал-лейтенанта Конева осенью 1941 года той истории, закончившейся «Вяземским котлом». Но сейчас война идет другим путем и враг далеко отсюда.
рег выражение
(\w+)?([…,.!?:; -])?\s?(\w+)([…,.!?:; -])?\s(\d+)\s?([…,.!?:; -])?(\d+)?\s?([…,.!?:; -])?(\w+)([…,.!?:; -])?\s?(\w+)? (не совершенное, но 3 и более... в следущей строке...)
использую в EmEditor функцию:
найти >> извлечь >>параметры извлечения>> отобразить только совпадающие части строк
► Показать
Выпуск 132
Михаил Алексеев, 2018
23 сентября 1941 года.
Штаб 1-й Ударной
Командующий 1-й Ударной
Конева осенью 1941 года той
целом еще 29-й и
оба Особых, 5-й, 6
механизированные и 6-й кавалерийский
аэродрома. Полки 43-й авиадивизии
был переброшен 16-й иап
о формировании 1-й Ударной
в составе 5-го и
го механизированных, 6-го кавалерийского
обеспечения. Бывшие 108-я и
РГК. Штат 134-го полка
танковый батальон 134-го полка
сделали с 23-м МСП
спаренных авиационных 23-миллиметровых, теперь
стал Катуков. 805-й артполк
командиры из 1979 года не
сержантов из 1979-го с
Возможно переделать скрипт (дополнить функциями) или добавить в найти-заменить извлечь?
Общая тема
Добавлено: 16 июл 2018 23:36
flegont
Найти / Заменить Ctrl+F
Вставить в поле поиска:
(\w+)?([…,.!?:; -])?\s?(\w+)([…,.!?:; -])?\s(\d+)\s?([…,.!?:; -])?(\d+)?\s?([…,.!?:; -])?(\w+)([…,.!?:; -])?\s?(\w+)?
Указать
Шаблон REX (регулярные выражения)
Нажать кнопку
Все подходящие
В окне Статистики будет результат.
P.S. Указанное регулярное выражение не ловит число в тексте, если оно соседствует с символом с кодом 8211 (тире). Потому что этот символ в данном РВ не был предусмотрен

Общая тема
Добавлено: 19 июл 2018 00:17
tonio_k
[+] "Сервис - Общие настройки... - Орфография - Проверка словарей Dic".
Предлагаю добавить проверку на "многоравенство" - для выявления подобного:
жаркое небо=жАркое=нЕбо
Общая тема
Добавлено: 19 июл 2018 09:31
flegont
Хм... Количество знаков = в правиле, большее 2 - это НЕ ошибка, а вполне может быть. Например:
{{ENG}}=<voice required="Name=Microsoft Zira Desktop">
Разделителем правила на левую и правую часть всегда считается первый знак =