Страница 2 из 8
Общая тема
Добавлено: 19 июл 2018 11:19
wasyaka
flegont писал(а): ↑16 июл 2018 23:36
Указанное регулярное выражение не ловит число в тексте, если оно соседствует с символом с кодом 8211 (тире). Потому что этот символ в данном РВ не был предусмотрен
Существует и пред обработка:
► Показать
([A-Za-zА-яЁё]+)\-(\d+)=$1 $2
([А-яЁё]+)(\d+)=$1 $2
(\d+)(\-)(\d+)(\-)([A-Za-zА-яЁё]+)=$1$4$5 $3$4$5
(\d+)([A-Za-zА-яЁё]+)=$1 $2
([а-я])\-\s(\d+)=$1 - $2
([а-я])\s\-(\d+)=$1 - $2
(\d+)\s?(\-)\s?(\d+)=$1 $2 $3
(\d+)\s?(\-)\s?([A-Za-zА-яЁё]+)=$1 $2 $3
которая убирает соседство с 8211 через пробел или вообще

Общая тема
Добавлено: 19 июл 2018 11:53
flegont
Да, можно и так

Общая тема
Добавлено: 19 июл 2018 23:39
tonio_k
Сервис->Орфография->Проверка словарей dic
Код: Выделить всё
в * году=в * годУ
в колчан* стрелы=в колчан* стрЕлы
из колчан* стрелы=из колчан* стрЕлы
отголоск* войны=отголоск* войнЫ
выводит как с ошибкой - не могу понять в чем дело

Общая тема
Добавлено: 20 июл 2018 08:48
flegont
в * году=в
* годУ
в колчан* стрелы=в колчан
* стрЕлы
из колчан* стрелы=из колчан
* стрЕлы
отголоск* войны=отголоск
* войнЫ
Звездочки из правых частей уберите
Общая тема
Добавлено: 20 июл 2018 10:52
tonio_k
-Ааааа! - Семён Семеныч!... (Бриллиантовая рука). Помню что просил именно такие ошибки находить. Потому что их в упор потом не вижу и часто их повторяю. Хочу поблагодарить ещё раз за поиск ошибок в dic. Такой мусор у меня, оказывается в словарях!!!
Общая тема
Добавлено: 20 июл 2018 11:38
flegont
Ошибки в словарях неизбежны, увы... Уж больно трудоемкая работа - составление словарей.
Так что, опция проверки доказала свою полезность

Общая тема
Добавлено: 20 июл 2018 19:25
tonio_k
Сервис->Орфография->Проверка словарей dic
Столкнулся с "несрабатываением" на таком дубликате:
Выяснил, что в словаре есть правила, где вместо пробела - злосчастный символ "пусто"160(А0) (уже который раз он мне воду мутит
!)
После замены этого символа, всплыли новые дубликаты, которые не отлавливались ранее. Так что всем рекомендую проверить свои словари DIC на выявление и устранение этого символа. Из за него многие правила просто не будут срабатывать.
Отправлено спустя 8 часов 9 минут 2 секунды:
flegont, Символ
# перед строкой. Всё что за ней Демагог
не воспринимает как правило. Но если этот символ не ставить, то эта строка будет считаться как правило, но из за отсутствия знака равенства срабатывать будет нечему. Получается Символ
# необязателен при вставке комментариев (если не будет содержать знак равенства)?
Общая тема
Добавлено: 21 июл 2018 08:38
flegont
По существу - да, но лучше, чтобы он был. Строка с # впереди отбрасывается программой сразу. А без него - анализируется на предмет разделения левой и правой части: проверяется существование разделителя :: затем = и только потом делается вывод "ну его нафиг", если разделитель не обнаружен.
Кроме того, в большом словаре легко найти комментарии, начинающиеся с #. А вот обнаружить строки без разделителей - это сложнее.
Общая тема
Добавлено: 21 июл 2018 09:35
wasyaka
Pronunciation adjustment.lua - после обработки - нет времени обработки.
Обработанный текст в окне статистике при продолжении обработки (поиск необработанных омографов) обрабатывается сразу без напоминания о сохранении (при выходе из проги - почему-то не забывает напоминать. )

Труд проги и время юзера прошли почти зря.

А от так?
► Показать

- 2.jpg (11.27 КБ) 62059 просмотров
Общая тема
Добавлено: 21 июл 2018 10:01
flegont
1) Показывать время обработки в Pronunciation adjustment.lua - будет в следующей версии
2) Стартовый запрос в Pronunciation adjustment.lua: куда именно сохранять результат словарных замен (с запоминанием сделанного выбора) - будет в следующей версии.
В самом деле, скрипт работает долго, результат работы - ценен и его лучше сохранять в более надежном месте, нежели служебный буфер "Статистика".
Общая тема
Добавлено: 23 июл 2018 14:01
tonio_k
flegont,
Поиск ... Шаблоны
Просьба в окне
Шаблоны убрать кнопку "
Удалить все". Она как минимум не нужна , а как максимум у меня самого уже не раз внутри все холодело, когда похожие друг на друга кнопки путал: "Удалить все" вместо "Удалить" нажимал

Как альтернатива предлагаю:
1) кнопку
"Удалить все" изменить на кнопку
"Выделить все"
2) добавить возможность выделить все строки через Ctrl+A.
3) при удалении
выделенных более одной строки, добавить диалоговое окно: "Удалить выделенные строки? Да/Нет
Отправлено спустя 2 часа 31 минуту :
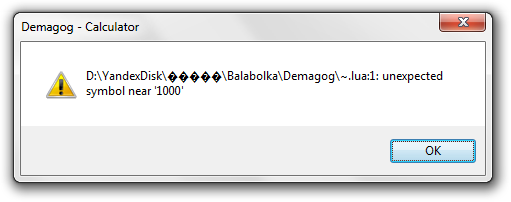
flegont, а как можно в скрипте прописать вставку в конец книги такой строки?
<speak><break time='1000ms'/><speak> Конец книги
У меня в скрипте сейчас так:
► Показать
Код: Выделить всё
docend = '\r\n <speak><break time='1000ms'/><speak> Конец книги'
WAdd(ind,-1,docend) -- в окно 0 в конец добавить текст из переменной
выходит ошибка:
► Показать
- 2018-07-23_16-23-41.png (19.3 КБ) 62015 просмотров
- похоже проблема в кавычках.

Отправлено спустя 15 минут 20 секунд:
Нашел!
Оказывается можно и так записать:
► Показать
<speak><break time="1000ms"/><speak> Конец книги
и паузу Демагог в этом месте делает и ошибка Lua не всплывает, и @Voice Aloud Reader такую строчку как паузу воспринимает.
Общая тема
Добавлено: 23 июл 2018 20:46
flegont
1) В ближайшем (и не очень) будущем интерфейс Окна шаблонов останется без изменений. Ошибочное нажатие кнопки "Удалить все" - ничего не удаляет, а вызывает запрос: "Удалить все?" По умолчанию активна кнопка ответа: НЕТ. Так что ничего страшного не произойдет. Сам я удаляю ненужные строки не тыканьем мышью по кнопкам на форме, а нажатием на клавиатуре клавиши Delete. Чтобы таким способом удалить всё, нужно нажать Ctrl+Delete - случайно такого не сотворишь. И, опять же, будет выдано предупреждение.
В дальнейшем, возможно, будут добавлены кнопки "Экспортировать в файл", "Импортировать из файла". И/или что-то другое. Окончательно мое мнение еще не сложилось.
2) Решение с двойными кавычками - абсолютно верное. Двойные кавычки воспринимаются, как элемент тега SAPI5, а одинарные, обрамляя всё, сообщают интерпретатору, что в функцию передается строковый параметр.
Demagog TTS
Добавлено: 13 авг 2018 22:45
tonio_k
Решил покопаться в скрипатах, входящих в пакет с Демагогом. Наткнулся на
Collection of texts и оказалось, что он мне резко стал нужен
Вопрос по скрипту.
1) Захотел в конце каждого склеенного файлов книг добавить фразу "Конец книги".
в
Pronunciation adjustment решалось добавлением:
► Показать
Код: Выделить всё
docend = '\r\n <speak><break time="1000ms"/><speak> Конец книги'
WAdd(ind,-1,docend) -- в окно 0 в конец добавить текст из переменной
Но в
Collection of texts это не прокатывает:
► Показать
Код: Выделить всё
WAdd(0,9,'\r\n\r\n\r\n <speak><break time="1000ms"/><speak> Конец книги \r\n'
вставляет разрыв и фразу "Конец книги" - в самое начало книги после слова СБОРНИК
И сам вопрос: Как сделать , что бы было "как хочется"?

2) И еще немного усложню: Хотелось бы, что бы в конце каждой книги можно было добавить "Счетчик" к фразе "Конец книги"
n+1 (Один, два и т.д.)
Demagog TTS
Добавлено: 13 авг 2018 23:36
flegont
Даю разъяснения!.. (с) Профессор Выбегалло
1) WAdd(i, j, stroka)
К тексту в окне i добавить текст из окна j, разграничив оба текста строкой stroka
Например:
WAdd(0, 9, '\r\n\r\n')
2) WAdd(i, -1, stroka)
К тексту в окне i добавить НИЧЕГО НИОТКУДА, разграничив строкой stroka
Например:
WAdd(0, -1, 'Конец книги')
В результате к тексту в окне 0 добавится фраза: Конец книги
3) WAdd(0, 9, '\r\n\r\n')
WAdd(0, -1, 'Конец книги')
К тексту в окне 0 добавить текст из окна 9, разграничив пустой строкой.
Затем к результату в окне 0 добавить еще строчку: Конец книги
Demagog TTS
Добавлено: 14 авг 2018 12:42
tonio_k
flegont писал(а): ↑14 авг 2018 09:03
А вот новый образец со счетчиком, полностью:
Работает, но ТОЛЬКО, если книги через Shift или Ctrl мышью выделить сразу несколько.
При добавлении "поштучно" с открытием диалогового окна для каждого нового файла, пока не нажали "отмена" - нумерация не меняется.
Demagog TTS
Добавлено: 14 авг 2018 15:23
flegont
Подумаю и над нумерацией при "поштучным" добавлении книг в сборник - это, действительно, особый случай

Отправлено спустя 18 часов 26 минут 58 секунд:
Вышла версия 348, с обновленным скриптом Collection of texts.lua
Demagog TTS
Добавлено: 15 авг 2018 14:49
tonio_k
flegont,
Сервис - Библиотекарь...
Скажите пожалуйста, есть какие-то ограничения по "глубине" поиска, когда ставим галочку "Искать так же во выхоложенных папках"?
На видео примере находит только 6 книг, а там их на самом деле намного больше
Demagog TTS
Добавлено: 15 авг 2018 17:09
flegont
Теоретически - глубина просмотра вложенных папок не ограничена, а на практике - пока хватит оперативной памяти. Показанная на видео ситуация выглядит странной. Протестирую,что оно там такое
Отправлено спустя 1 час 29 минут 22 секунды:

Поправил и перезалил дистрибутив.
Demagog TTS
Добавлено: 15 авг 2018 22:46
tonio_k
flegont писал(а): ↑15 авг 2018 18:38
дистрибутив.
Небольшие пожелания:
Сервис - Библиотекарь...
1)Открывает книгу
только в окно
0-Статистика. А надо, что бы открытие книги было в активном окне.
2)При выделении курсором одной из найденных книг в окне Библиотекарь, в самом окне Библиотекарь или нижней панели Демагог показывался путь, по которому найдена выделенная курсором книга.
Вкладки окна:
3)Иногда бывает нужно переместить содержимое из одного окна в другое (Например из окна
0-Статистика в Окно
2. Можно ли как нибудь реализовать эту возможность через контекстное меню? Например добавлением пункта меню при щелчке правой мыши:
Переместить в окно...
При нажатии которого выходило бы окно с просьбой ввести номер Окна, в которое нужно
переместить содержимое текущего окна. Или разворачивался список с номерами окон, в котором достаточно просто щелкнуть мышью по нужному номеру. (На всякий случай тут можно добавить "защиту"-предупреждение если окно назначения - не пустое).При перемещении активным должно стать окно назначения.
Отправлено спустя 1 час 2 секунды:
Сервис - Библиотекарь...
4)при перезапуске Демагог, галочка напротив
"Искать так же во вложенных папках" - пропадает
Demagog TTS
Добавлено: 15 авг 2018 23:56
flegont
1) логично
2) было бы удобно
3) что-нибудь придумаю

4) вообще-то так было задумано - рекурсия забирает довольно много ресурсов - и я хотел заставить пользователя каждый раз решать: нужно ли напрягать комп глубинным поиском, или проще в меню выбора папки опуститься вручную на нужный уровень. Хорошо это я придумал, или наоборот - плохо... пока не знаю...
Demagog TTS
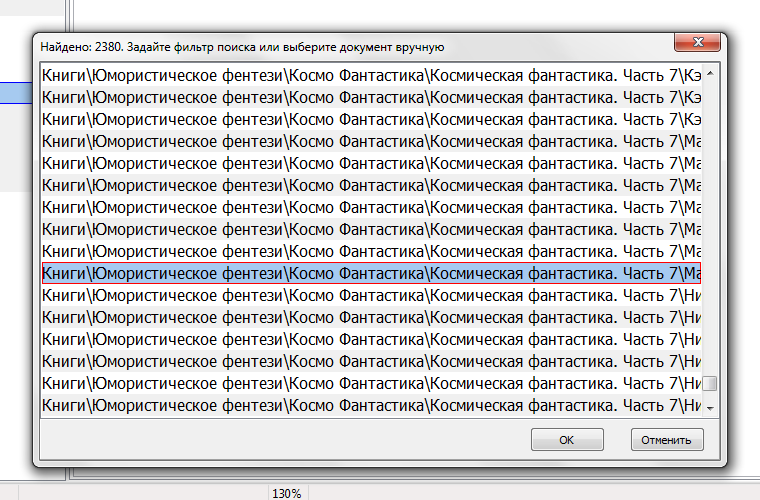
Добавлено: 22 авг 2018 20:36
tonio_k
Сервис - Библиотекарь...
► Показать
- 2018-08-22_20-01-16.png (73.98 КБ) 61722 просмотра
Путь местонахождения файла сдвигает название самого файла вправо - без возможности его просмотреть - невозможно сдвинуть содержимое окна, что бы увидеть "что там за границей ока".
Вообще, ИМХО мне больше нравилось первоначальное отображение - все названия списком. Никакого нагромождения в окне. Полный путь нужен был скорее "справочно" и эпизодически - что бы сориентироваться в случае, например, одинаковых названий в разных подкаталогах. Что бы путь к файлу высвечивался в Информационной строке или при наведении на него, при выделении конкретного файла из списка.
Может, как вариант, Полный путь указывать "справа" от самого названия файла через разделитель или в скобках или как таблица из 2 колонок? При этом добавить возможность прокрутки влево/вправо в самом окне.
Demagog TTS
Добавлено: 22 авг 2018 21:53
flegont
1) Вот как раз в этом меню - я ничего не менял! В нем всегда выдавался полный путь к книге.
Просто, в зависимости от удачного или нет выбора начальной папки в стартовом меню - мы получаем соответственно - более или менее длинный полный путь.
В представленном примере, наверняка был включен режим поиска во вложенных папках. И тут надо было бы выбирать не самую верхнюю папку, содержащую многократно вложенную папку
..\Книги\Юмористическое фэнтези\Космо фантастика\Космическая фантастика. Часть 7\
а сразу в стартовом меню, в дереве папок выбрать папку Космическая фантастика. Часть 7
Тогда в пунктах меню, чей скриншот показан, не будет в каждой строчке вышеуказанной длиннющей "преамбулы"
2) Все, что я сделал, так это показ в заголовке меню найденных книг полного имени начальной папки, выбранной в стартовом меню. В совокупности с именем найденной книги оно образует полный путь к файлу книги.
3) Что делать, когда при всех стараниях, не удается добиться, чтобы строка меню помещалась полностью? Я над этим работаю. Мне хотелось бы, чтобы полный путь изначально НЕ показывался, а высвечивался при наведении мышью на имя файла - как всплывающая подсказка. Но некоторые технические детали я еще обдумываю.
Demagog TTS
Добавлено: 30 авг 2018 16:36
tonio_k
Планируете ли вы в Демагоге обратную совместимость со словарями Балаболки BXD?
Demagog TTS
Добавлено: 30 авг 2018 18:07
flegont
Таких планов нет.
Demagog TTS
Добавлено: 30 авг 2018 19:29
tonio_k
flegont, скажите пожалуйста, а как можно "применить" к текущему окну команду Литературный текст через скрипт?
Demagog TTS
Добавлено: 30 авг 2018 20:16
flegont
Пока никак. В нынешней версии - интерпретатор ничего не знает про эту опцию Демагога, и не может поэтому, к ней обратиться.
Но, практически все действия (заменить, удалить) скрытно выполняемые опцией "Литературный текст", можно смоделировать регулярными выражениями. И составить соответствующий rex-словарик. А со словарями интерпретатор работать умеет (ф-ция WFilter)
Demagog TTS
Добавлено: 31 авг 2018 00:45
tonio_k
Правка - Заменить символы
Если открыть текст из файла - то меню доступно и сочетания функциональных клавиш - тоже. Во всех других случаях (вставили из буфера обмена, ввели текст вручную, и т.д.)во всех окнах меню недоступно, клавиши не работают
Отправлено спустя 8 минут 56 секунд:
И еще одна просьба: Для анализа текста, как в скрипте прописать, что бы был произведен подсчет и выведен результат: сколько раз в тексте встречается указанное в скрипте слово или словосочетание?
Как альтернатива - Поиск - Замена. Где нибудь показывал количество произведенных замен (Через всплывающее окно или в строке состояния). Тогда достаточно произвести замену слова на само себя и посмотреть сколько раз сработало.
Demagog TTS
Добавлено: 31 авг 2018 10:46
flegont
Правка - Заменить символы
Опция доступна
только для т.н. плоских текстов - т.е. не имеющих форматирования. Т.е. нет вариаций шрифта на курсив/жирный/подчеркнутый/зачеркнутый, нельзя применять разные шрифты, а также шрифты разных размеров и т.п. Нет таблиц, нет рисунков.
Почему такое ограничение на доступность этой опции?
Потому что платой за высокую скорость работы опции
Правка - Заменить символы является уничтожение любого вышеуказанного форматирования текста. Такой, блин, алгоритм, составленный в ту давнюю эпоху, когда Демагог умел работать только с плоскими текстами (как Блокнот Windows)

Когда же появились форматы с форматированием текста (простите за каламбур):
RTF-как есть и
DXT, пришлось эту опцию для них запретить. Текст, еще не сохраненный, т.е. не имеющий имени файла, так же считается
текстом с форматированием, потому и для него эта опция недоступна.
Что делать?
Я собираюсь потихоньку-полегоньку ревизовать алгоритм
Правка - Заменить символы. Чтобы он работал для любых текстов. Но для
RTF-as is,
DXT, и
не сохраненных использовался бы другой метод замен / удалений. Более медленный, но сохраняющий форматирование.
в скрипте прописать, что бы был произведен подсчет и выведен результат: сколько раз в тексте встречается указанное в скрипте слово или словосочетание?
Припоминаю, что где-то в моих архивах есть пример скрипта с подсчетом заданных слов в тексте. Поищу
Ага, вот...
Проверка гипотезы об авторском инварианте
Demagog TTS
Добавлено: 12 сен 2018 23:01
tonio_k
flegont,
три варианта написания одного правила в словаре DIC:
1)
ю.б. заменяет на: ю.б. (т.е. игнорирует - все ок)
2)
ю.б. заменяет на:
ю. бэ.
3)
ю.б. заменяет на:
ю. бэ.
получается, "пробел" в начале правила в п. 2 игнорируется. Т.е. 2) равен 3)?
Demagog TTS
Добавлено: 13 сен 2018 22:12
flegont
Пробелы, обрамляющие левую часть правила в dic-словаре, Демагог игнорирует.
xxx=qwerty
и
xxx =qwerty
это одно и то же.
Demagog TTS
Добавлено: 13 сен 2018 22:28
tonio_k
Вообще меня смутил факт, что в примере ю.б. перед найденной буквой б. стоит точка. Т.е. Нет пробела, между ю. и б. следовательно это не два слова, а одно слово с точкой внутри. - Пишется слитно. А правило все равно срабатывает. Или для словаря DIC знак припенания является разделителем слова?
Demagog TTS
Добавлено: 13 сен 2018 23:33
flegont
для словаря DIC знак препинания является разделителем слова?
Только для прямого перебора

Это - тот самый случай, когда быстрый алгоритм и прямой перебор дают разные результаты.
Быстрый алгоритм: просмотр
слов текста, поиск их в хешированном словаре, и замена (отдельно или в словосочетании). Разделители слов: пробел, табуляция, разрыв строки.
Прямой перебор: поиск в тексте
групп символов, соответствующих очередному шаблону из словаря; и проверка границ найденного. Если успешно, то замена. Граница: пробел, табуляция, разрыв строки, знак препинания.
Пример. Правило:
б.= бэ. Текст:
ю.б.
Демагог, быстрый алгоритм:
ю.б. --> ю.б. (правило не применено!)
Демагог, прямой перебор:
ю.б. --> ю. бэ.
Балаболка:
ю.б. --> ю. бэ.
Demagog TTS
Добавлено: 29 сен 2018 22:02
tonio_k
flegont, Настройки "Сериалы" небольшое пожелание:
сделать возможность на выбор пользователя убрать/включить добавление к нумерации каждого файла из сериала наименование файла книги. т.е. два варианта на выходе:
1) 0001.txt, 0002.txt ... и т.д.
2) 0001_Название книги.txt, 0002_Название книги.txt ... и т.д.
Поясню почему. На плеере с маленьким экраном часто приходится дожидаться что бы увидеть номер проигрываемого файла, так как бегущая строка с длинным наименованием текущего файла еще не закончила свой бег...
Demagog TTS
Добавлено: 29 сен 2018 23:21
flegont
Да, это было бы полезным. Сделаю в следующей версии.
Demagog TTS
Добавлено: 01 окт 2018 15:41
tonio_k
flegont, Столкнулся с таким моментом: в общих настройках программы стоит галочка "Вставлять примечание в текст при открытии файла".
При выполнении команды Сервис, Пакетный конвертер -->TXT примечания не вставляются.
Demagog TTS
Добавлено: 01 окт 2018 19:12
flegont
Хм... Конвертирование файла (или множества файлов ) в плоский текст - это не то же самое, что его открытие в активном окне Демагога. Потому я и не озаботился тем, чтобы опция вставки примечаний при открытии файла распространялась и на этот случай.
Впрочем, подумаю.
Demagog TTS
Добавлено: 01 окт 2018 22:08
tonio_k
flegont писал(а): ↑01 окт 2018 19:12
Впрочем, подумаю.
может такой вариант? Сделать проверку на:
1)В настройках "Вставлять примечание в текст" - отключен.
Тогда: Сервис, Пакетный конвертер -->TXT работает как обычно
2)В настройках "Вставлять примечание в текст" - ВКЛючен.
Тогда: при запуске Сервис, Пакетный конвертер -->TXT Выводить Диалоговое окно: "Вставлять примечание в текст" (ДА/НЕТ) - тут по смыслу. Если да, то вставить примечания в текст при открытии файла, если нет, то Пакетный конвертер -->TXT работает как обычно
Отправлено спустя 1 час 37 минут 14 секунд:
Вот с чем только что столкнулся.
Записываю книгу большого размера как сериал.
Записал первые 54 файла mp3 - возникла необходимость остановится. Остановил запись.
Возвращаюсь к вопросу записи книги. Нашел в тексте книги, с какого места начинается 54 файл.
Удаляю в тексте то, что выше выбранного места. Сохраняю полученный файл книги txt.
Ставлю в настройках сериала начать нумерацию с 54 файла. (при этом старый 54 файл удаляю)
Запускаю запись книги и вижу, что все записанные ранее 54 предыдущих файлов исчезли!


Сделайте пожалуйста, что бы запись сериала файлов txt и файлов mp3 в папке назначения происходила с перезаписью одноименных файлов без предварительной очистки каталога куда записывается сериал.
Demagog TTS
Добавлено: 02 окт 2018 08:39
flegont
Сделать проверку на: настройках "Вставлять примечание в текст"...
Мне пока что больше нравится вариант без всяких вопросов - коль задано вставлять примечания - то и получи
без предварительной очистки каталога куда записывается сериал
Подумаю, может настройками это решать
Demagog TTS
Добавлено: 02 окт 2018 11:43
tonio_k
Вообще, мне очень нравилась фишка в mp3book продолжение прерванной записи. То, о чем я просил выше это ручной способ. Т.е. я должен найти последний файл, прослушать его, найти в тексте это место и т.д.
А можно это реализовать в автоматическом режиме? Т.е. нажимаю кнопку записать аудио, и Демагог сканирует папку назначения и продолжает запись. Примерно я вижу это в таком виде:
В каталог, куда записывается mp3 создаётся сериал txt. Делается проверка на совпадение имен файлов txt с именами mp3. Удаляются лишние txt (все дубликаты текстовых файлов с файлами аудио txt=mp3 при этом последний mp3 файл надо всегда удалять сразу и вначале что бы его перезаписать заново-вдруг он сбойный). И началась запись оставшихся в каталоге сериала txt
Demagog TTS
Добавлено: 02 окт 2018 15:30
flegont
Да, есть тема для размышлений.
Как-то надо различать "состояние" записи: она закончена или была прервана?
Например, если удалять исходные текстовые файлы сериала не все сразу по окончании записи аудио-файлов, а по одному, в процессе. Тогда присутствие в папке с аудио еще и текстовых файлов будет означать, что запись аудио была прервана и требуется продолжение...
Demagog TTS
Добавлено: 03 окт 2018 09:47
tonio_k
Оптимизация Поиска омографов все/всё.
Сейчас ручной поиск омографов работает по принципу просмотра всех вариантов встречающихся в тексте комбинаций "все/всё". Есть хорошо зарекомендовавший себя словарь vse_vsyo.rex. Однако и у него частенько проскакивают ложные срабатывания.
Я лично не использую ручной поиск - как правила сработали, так и слушаю и по ходу чтения вношу корректировки ложных срабатываний в словари.
Но вот в чем моя идея (думаю она может понравиться и тем, кто применяет ручной метод), а что если свести ручной труд к минимуму? То есть не просматривать ВСЕ варианты встречающихся в тексте комбинаций "все/всё", а только те, которые попадают под срабатывание словаря vse_vsyo.rex или словарь dic
В итоге получаем:
Минимальное, по сравнению с общим объемом, количество комбинаций подлежащих к просмотру. Быстрое выявление и анализ ложных срабатываний (с последующим внесением поправок в словари). То есть убирая ложные срабатывания - получаем оптимальный вариант. Вопрос к flegont, есть возможность реализовать такой функционал путем подсветки или поиском и переходом на найденный абзац? Вообще, поиск абзаца в тексте по критерию срабатывания/не срабатывания правила из словаря может дать большое поле для применения.
Demagog TTS
Добавлено: 03 окт 2018 12:03
flegont
поиск абзаца в тексте по критерию срабатывания/не срабатывания правила из словаря
Это чем-то похоже на метод, который я иногда использую: копирую из словаря левую часть некоего правила, и вставляю ее в окно Поиска. Выбираю соответствующий тип поиска: DIC или REX.
И "Найти далее" - пошел по тексту, наблюдать срабатывания правила - найдет что-то или не найдет. Найденное соответствие правилу - как и положено при поиске - выделяется цветом.
Это я к тому, что (похоже) все необходимые модули для поиска по словарным правилам DIC/REX в Демагоге уже есть. Но, пока что доступ к ним открыт только через опцию "Найти/Заменить"
Demagog TTS
Добавлено: 04 окт 2018 03:44
tonio_k
А если пойти немного другим путем? Например сделать функцию вызова поиска через скрипт? Задал ему перечень правил, или плейлист с правилами или лучше вообще указать в скрипте путь к словарю, как вариант и пусть сделает выборку "вывести результаты" в окно статистики по левой части правил? Ну ещё что бы замены при этом произвел, что бы было понятно как изменился текст.
Demagog TTS
Добавлено: 04 окт 2018 08:54
flegont
Не готов сразу дать определенный ответ. Допустим, с dic-правилами мне всё более-менее понятно. А вот как Lua уживается с библиотекой SkRegExp - тут надо экспериментировать.
Demagog TTS
Добавлено: 05 окт 2018 22:46
tonio_k
Поиск.Ctrl+F
Вкладка Заменить
[^\r\n]*(\bвсё\b|\bвсём\b)[^\r\n]* заменяем на "пусто/пробел"
Поштучно кнопка "Заменить" замены происходят, а вот все скопом кнопка "Заменить все" - замены не происходят
Demagog TTS
Добавлено: 05 окт 2018 23:32
flegont
Спасибо за сообщение. Проверю, что там такое
Отправлено спустя 9 часов 55 минут 34 секунды:
Хммм... У меня - работает. Проверил на нескольких книжках. "Заменить все" - удаляются абзацы, содержащие слова
всё и
всём.
Для прояснения ситуации необходим изначальный текст, на котором вы обнаружили глюк.
Demagog TTS
Добавлено: 06 окт 2018 18:29
tonio_k
flegont писал(а): ↑06 окт 2018 09:28
Для прояснения ситуации необходим изначальный текст, на котором вы обнаружили глюк.
Извините, похоже мое нетерпение сыграло со мной обидную шутку. "Заменить все" применялся к текстовому файлу в 33 Мб (сборник из 30 книг). В заблуждение меня ввел тот факт, что после нажатия кнопки "заменить все"
нет никакого информационного сообщения о прогрессе или завершении процесса замен. Нажал на кнопку "Заменить все" и сразу можно окно поиска закрывать или новый поиск задавать или по тексту гулять. Вот после "заменить все", я сразу задал поиск на присутствие \bвсё\b|\bвсём\b в тексте - а он там благополучно присутствует, и находится и заменяется кнопкой заменить. А заменить все - никакой реакции. Вот и забил тревогу, мол не работает!
Как долго ждать окончания процесса "заменить все" - не понятно. Может вообще процесс зависает? Есть подозрение, что при последующем запуске поиска (не дождавшись окончания предыдущего) - происходит жор ресурсов и Демагог штатно не закрывается.
С маленьким по размеру текста "заменить все" происходит довольно быстро.
Demagog TTS
Добавлено: 06 окт 2018 19:29
flegont
33 мегабайта!

Зато теперь знаем, что Демагог и с таким объемом может справиться

Прекрасный вышел тест. Признаком того, что замены завершены, является смена статуса файла в строке состояния на
Модиф. Хотя, если ни одной замены не найдено, то статус не изменится.
Выдавать каждый раз сообщение "Процесс замен завершен" - не хочу. Будет сильно раздражать. Да и время, через которое такое сообщение появится - если поиск достаточно сложный - угадать невозможно.
Тут и модификация алгоритма на вариант с бегущей строкой не поможет. Бегущая строчка будет просто надолго "замерзать", пока ищется очередное совпадение. (Кстати, такая модификация алгоритма - с бегущей строкой, и сама по себе будет в разы медленнее).
Я, кстати, заметил, что если в каком-либо регулярном выражении присутствует символ * то оно может выполняться ооочень долго. Такова специфика РВ. Инструмент очень мощный, но капризный.
Если выполнять следующий поиск, не држидаясь окончания предыдущего, то да, расходуется дополнительная память. А сама Windows настолько хитро устоена, что нехватку памяти может заменять временным сбросом данных на жеский диск... Поэтому может создаваться впечатление, что программа подвисла.
Demagog TTS
Добавлено: 06 окт 2018 19:38
tonio_k
А что если вместо бегущей строки отображать количество произведенных замен т.н. счётчик? Это одновременно и индикатор процесса и статистика для анализа текста по итогам замен.
Demagog TTS
Добавлено: 06 окт 2018 19:50
flegont
Это будет тот же самый медленный вариант алгоритма замен - пошаговый, одна найденная замена, потом другая и т.д. Сейчас используется специальная функция из библиотеки SkRegExp. Она сама делает заданные массовые замены и возвращает готовый измененный текст. Никаких счетчиков внутри нее нет. Зато работает сравнительно быстро.
Да и толку от слежения за заменами, по большому счету - никакого. В теории регулярных выражений особо отмечается тот факт, что алгоритм НЕ является конечным, и теоретически, всегда возможно зацикливание. Или же попадание в "экспонециальную ловушку", когда время расчета непомерно возрастает, что практически равносильно зацикливанию.