Страница 12 из 13
Скрипты для Demagog
Добавлено: 23 окт 2020 20:42
tonio_k
wasyaka писал(а): ↑23 окт 2020 20:00
Отсутствие функций тхт редактора:
как раз это можно реализовать через скрипты. Можно сделать подобие швейцарского ножа с кучей вариантов и повесить его только на одну комбинацию клавиш. Нажимаете комбинацию клавиш к выделенному тексту, выйдет окно для работы с выделенным текстом. Если текст был не выделен, то выйдет окно с вариантами действий для всего содержимого окна. Тут большой простор для полета фантазии и возможностей. Вот простой пример шаблона окна:
http://i91650e3.beget.tech/viewtopic.php?p=4792#p4628
Самое главное, пункты меню вы можете подобрать для себя индивидуально только то что вам хочется и с чем вам удобно работать. А со временем можно пункты убрать или новые добавить. Т.е. вы сами управляете интерфейсом и пунктами меню, а не подстраиваетесь под имеющийся у редактора. Пишите в ЛС обсудим.
Скрипты для Demagog
Добавлено: 05 дек 2020 22:05
VitalijBurenko
Ребята здравствуйте.
Простите если не в ту ветку пишу.
Есть необходимость озвучивать стартовый протокол на спортивных соревнованиях.
Протокол генерируется программно.
Каждая его строка содержит стартовую минуту и набор фамилий.
Подскажите как наиболее легко из него получить либо один длинный файл но чтобы в нем каждая строка начинала воспроизводится четко со своей минуты.
Либо пачку файлов с озвучкой только одной строки.
Пример файла:
1, Произвольный текст 1
2, Произвольный текст 2
.....
5, Произвольный текст 5
7, Произвольный текст 7
Нужно получить либо 1 файл в котором на первой минуте звучит "Произвольный текст 1" на второй "Произвольный текст 2" и т.д.
Либо 7 файлов . 1.mp3 - c озвучкой "Произвольный текст 1" , 2.mp3 - c озвучкой "Произвольный текст 2" и т.д.
Просто с синтезом речи столкнулся впервые и не совсем понимаю как это сделать правильней.

Скрипты для Demagog
Добавлено: 06 дек 2020 12:26
balabolka
VitalijBurenko писал(а): ↑05 дек 2020 22:05
Подскажите как наиболее легко из него получить либо один длинный файл но чтобы в нем каждая строка начинала воспроизводится четко со своей минуты.
Проще всего создать
файл формата LRC и преобразовать его в аудиофайл в
Балаболке (или при помощи консольной утилиты "Балаболки").
Файл формата LRC (с именем, например, FILE.LRC) будет выглядеть так:
Код: Выделить всё
[00:00.00]Произвольный текст 1
[01:00.00]Произвольный текст 2
[02:00.00]Произвольный текст 3
Сначала будет прочитана первая строка текста, когда начнется 2-ая минута - прочитана вторая строка и т.д.
Выберите в "Балаболке" пункт главного меню
Сервис|Преобразовать субтитры. В качестве синтезатора речи желательно использовать не старый голос "Николай", а что-то более новое, так как "Николай" не умеет вставлять паузы в звуковые файлы. Либо на вкладке "Настройки" укажите более свежий голос (не обязательно русский), который будет "читать" паузы между репликами.
Также, можно использовать онлайн-сервисы для преобразования LRC в звуковой файл: в "Балаболке" это пункт главного меню
Сервис|Онлайн-сервис для синтеза речи. У "Яндекса" хорошие русские голоса, можно использовать этот сервис. На вкладке "Субтитры" выберите имя файла LRC, выберите голос и нажмите кнопку "Сохранить".
(Надеюсь, соревнования длятся не много часов, так как результирующий звуковой файл может получится очень большим и на его создание уйдет много времени.)
Скрипты для Demagog
Добавлено: 06 дек 2020 12:39
flegont
Поддерживаю эту рекомендацию.
Скрипты для Demagog
Добавлено: 07 янв 2021 10:14
wasyaka
С Наступившим!

Словарь
*.dic
Сортировка: предлагаемая но не устраиваемая
А сделать
СКРИПТОМ такую сортировку? По
омографам?
С дополнением? в соответствующий каталог:
# омограф =
фраза с омографом
навроде словаря в hmg?
Примерно такой (сделано вручную и пополнение оч-чень нудное)
#автослесаря =
подмастерьем автослесаря=подмастерьем автослЕсаря
#адреса =
в честь адреса=в честь Адреса
*, адреса,=, адресА,
адреса ваши=адресА ваши
#аду =
увидеть аду=увидеть Аду
#ангары =
видишь, ангары=видишь, ангАры
#атласа =
жемчужно - белого атласа=жемчужно - белого атлАса
затёртого атласа=затёртого атлАса
Скрипты для Demagog
Добавлено: 07 янв 2021 11:37
tonio_k
Думаю можно, но с некоторыми особенностями...
Нужно скрипту объяснить какие слова считаются омографами. Тут мне представляется 2 варианта:
1) Для этого должен быть отдельный файл в котором будут перечислены все омографы. Например allomorphs.txt. Тогда любой новый словарь можно будет "отсортировать" по списку allomorphs.txt
2) можно непосредственно в самом словаре *.dic перечислять омографы добавляя знак решётки в качестве метки. При этом знак # как комментарий более в словаре применять нельзя что бы не было проблем при сортировке. Тогда скрипт сначала будет искать с словаре омографы помеченые знаком #, и составлять из найденного список allomorphs, затем по этому списку сортировать правила как в п.1
Минусы предлагаемой сортировки через скрипт:
1)Если какой либо омограф будет пропущен (не перечислен) самим пользователем при создании allomorphs.txt либо не перечислен в *.dic с пометкой #, то правила содержащие только этот омограф будут утеряны!
2) если в одном правиле присутствуют два омографа, то правило будет задвоено - продублировано и отсортировано для каждого омографа.
Из плюсов, в списке allomorphs или в словаре *.dic с пометкой # можно будет перечислять омографы в виде:
#замк*
#стрелк*
удобно что бы не перечислять все варианты однотипных омографов.
UPD
#замк* не удачная мысль. Сюда может быть продублировано правило
замкнутым кругом=замкнутым крУгом
Даже тут звёздочки надо использовать с умом.

Скрипты для Demagog
Добавлено: 07 янв 2021 12:05
wasyaka
tonio_k писал(а): ↑07 янв 2021 11:37
tonio_k » 07 янв 2021 11:37
Думаю можно, но с некоторыми особенностями...
Не хотел тебя напрягать,,,
Хочется мнение
Мэтра...
(сортировка внутри... и т.д
Скрипты для Demagog
Добавлено: 07 янв 2021 17:40
flegont
А если знак комментария для обозначения омографа применять в уникальной комбинации с каким-то другим символом (символами)? Тогда другие знаки "обычных комментариев" не помешают. Например:
#~!~передохнут
передохнут от жары= передохнУт от жары
Скрипты для Demagog
Добавлено: 07 янв 2021 18:27
tonio_k
flegont писал(а): ↑07 янв 2021 17:40
#~!~передохнут
Для словаря dic да и самому скрипту по сути без разницы какой символ или символы будут уникальные - главное что бы строки с омографами не содержали = или :: тем самым превращая слово в правило. Можно и так записать:
•передохнут
передохнут от жары= передохнУт от жары
Тогда знак # можно смело использовать в других местах словаря по его прямому назначению. А в скрипте прописать: символ "•" - считать маркером омографа.
От маркера требуется что бы он был удобен, нагляден (пожирнее на экране) ну и завести его можно было по быстрому. Тут # самое удобное. Можно и тройной ### записать.
Использование # - скорее дань традиции добавлять в словарь то, что не участвует в заменах dic комментировать символом решетка. Например "Индексный метод" применения rex словарей через скрипт применяет примерно тот же принцип при индексации. А при индексации символ # используется как метка индексных слов при составлении словаря. Единственное отличие от индексного метода, рассматриваю в сортировке, о которой просит wasyaka, использовать поиск правил содержащих омографы по Dic шаблону (через DicMatch). Это будет не очень быстрая сортировка из за поиска не по шаблону lua, зато реально можно будет записывать ключевые слова омографы со звездочками. Если окажется, что огромный словарь будет сортироваться ооочень долго, тогда можно будет и на сортировку по lua шаблону перейти.
Скрипты для Demagog
Добавлено: 10 янв 2021 17:04
tonio_k
wasyaka писал(а): ↑07 янв 2021 10:14
А сделать СКРИПТОМ такую сортировку? По омографам?
В открытом в текущем окне словаре DIC скрипт распределяет правила по ключевым словам (омографам).
Строка с ключевым словом (омографом) должна начинаться со знака # (можно записать несколько: ###)
Распределение происходит по ключевым словам (омографам) без дублирования. Это означает, что если в правиле dic присутствуют 2 омографа, то данное правило перераспределится только к одному ключевому слову (омографу) - первому по алфавиту.
При распределении правила dic не сортируются.
Нераспределённые правила (к которым не нашлись ключевые слова) переносятся в начало словаря с пометкой ###Нераспределённые правила.
Ключевые слова можно записать в виде целого слова:
###стрелка
###стрелки
###стрелку
тогда к каждому ключевому слову распределятся соответствующие правила dic
Или можно записать в виде lua шаблона:
###стрелк[а-яё]+
###стрелк[аиу]
тогда правила dic распределяются согласно lua-шаблону
Пример работы со скриптом:
Скрипты для Demagog
Добавлено: 22 янв 2021 12:23
tonio_k
скрипты lua пишутся под программу Демагог. Именно Демагог "понимает" и запускает скрипты. Так что научить стороннюю программу чему либо не получится, если она не поддерживает скрипты lua. Можно по-изголяться и попробовать сделать некий симбиоз двух программ Демагог и Booki. Это предполагает обязательный запуск Демагога, который при помощи скрипта lua будет что-то делать с файлами (копировать, перемещать,переименовать, удалять или сохранить fb2 в txt).
KostyasaRgy писал(а): ↑22 янв 2021 06:48
создавала соответствующую папку "Фимилия Имя" автора, а если еще и с вложенной папкой "жанр", так совсем было бы замечательно.
Скрипт lua в Демагоге, думаю, для этого можно сделать, вопрос в том, откуда будет браться текстовая информация: фамилия, имя, жанр? Что должно быть автоматизировано? И вообще, устроит ли вас схема одновременного запуска вашей программы и программы Демагог для решения эпизодических задач?
Скрипты для Demagog
Добавлено: 22 янв 2021 14:47
wasyaka
KostyasaRgy писал(а): ↑22 янв 2021 06:48
соответствующую папку "Фимилия Имя" автора, а если еще и с вложенной папкой "жанр", так совсем было бы замечательно.
Для этого есть готовая прога
calibre: универсальное решение для ваших электронных книг
► Показать
- 2021-01-22_152532.png (378.96 КБ) 3054 просмотра
"жанр" на энглиш
Скрипты для Demagog
Добавлено: 28 янв 2021 10:29
And1z
Подскажите плз, реально ли реализовать разбивку по главам озвученной книги?
Чтобы каждая глава была отдельным mp3 файлом. (для удобства делаю по главам, не удобно когда много глав и всё в ручную каждую главу вырезаю, хотелось бы както автоматизировать)
Например какое-то ключевое слово или символ для создание отдельного мп3... (сделать анлим по времени и по размеру файла, но когда встречается ключ-слово то чтобы создавало на выходе новый файл)
Скрипты для Demagog
Добавлено: 28 янв 2021 11:55
tonio_k
And1z писал(а): ↑28 янв 2021 10:29
разбивку по главам
попробуйте такой скрипт:
данный скрипт текст в окне Демагога разбивает по главам и в указанной папке появляются текстовые файлы с отдельной главой в каждом файле.
Далее (если записываете в аудио штатно) применяем пакетную запись в аудио ко всем текстовым файлам (полученным при разбитии на главы) в папке. В настройках перед записью в аудио указываем максимальное количество символов в одном аудиофайле. В итоге получаем: одна глава = один mp3
Скрипты для Demagog
Добавлено: 06 фев 2021 15:39
flegont
О функции Form()
Начиная с вер. 397 макет формы ввода задается не в текстовом виде, а в виде таблицы Lua. Хотя и прежняя запись будет работать (но упоминание о ней из "Шпаргалки" исключено

)
Записи очень похожи, но табличная гибче и позволяет вычислять элементы шаблона "на лету". Для сравнения:
► Показать
Код: Выделить всё
-- INTERPRETER IN DEMAGOG
-- An example of using the Form() function
s = [[
Form: Width=150; Height=100; Caption=Пример
MarkHello: Top=24; Left=32; Caption=HELLO, WORLD!
]]
Form(s)
pause(1)
-- an alternative way to set the layout
a = {
Form = { Width = 150, Height = 100, Caption = 'Пример'},
MarkHello = { Top = 24, Left = 32, Caption = 'ПРИВЕТ, МИР!' }
}
Form(a)
А вот так теперь выглядит скрипт PlayYandex.lua из моей
личной сборки
► Показать
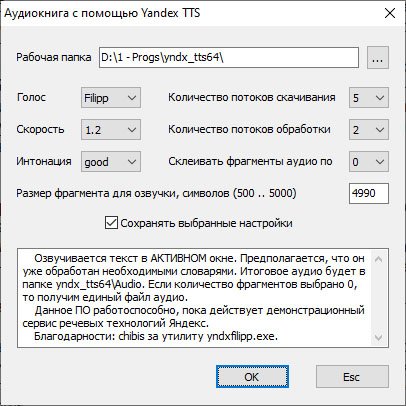
- Y.jpg (71.53 КБ) 2825 просмотров
Еще пример. Конвертер аудиофайлов, на основе converter.lua, написанного ув.
balaamster
► Показать
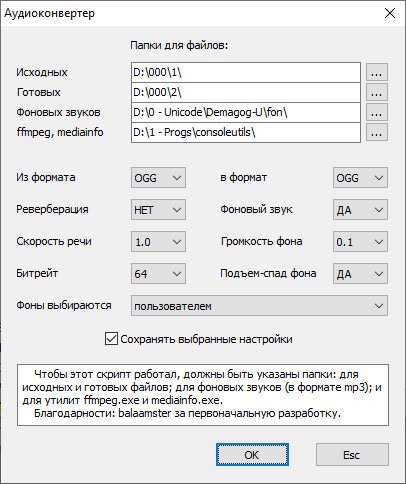
- conv2.jpg (65.92 КБ) 2825 просмотров
Скрипты для Demagog
Добавлено: 11 фев 2021 00:04
tonio_k
не смог разобраться с функцией
Execute()
Например у меня есть команды:
Код: Выделить всё
os.execute(' mkdir "d:\temp\1\" ')--Создать каталог 1
os.execute(' RD /S /Q "d:\temp\1\" ')--удалить каталог 1 со всем содержимым
Может ли
Execute() запустить эти команды вообще? А скрытом виде?
Скрипты для Demagog
Добавлено: 11 фев 2021 09:55
flegont
Функция Execute служит для запуска всяческих исполняемых файлов: *.exe, *.com, *.bat и т.п. (с параметрами или без). Поэтому создадим 2
исполняемых файла:
m.bat, содержащий текст:
и d.bat, содержащий текст:
Для их выполнения теперь можно применять функцию Execute
Код: Выделить всё
Execute('m.bat','',wsHide) -- создает папку 1
Execute('d.bat','',wsHide) -- удаляет папку 1 со всем содержимым
-- всё происходит скрытно от пользователя
Скрипты для Demagog
Добавлено: 12 фев 2021 09:13
Lecron
tonio_k писал(а): ↑11 фев 2021 00:04
Может ли Execute() запустить эти команды вообще? А скрытом виде?
Должно и без батника работать.
Скрипты для Demagog
Добавлено: 13 фев 2021 22:28
tonio_k
flegont, у меня тут такое рационализаторское предложение. Взять на вооружение (в калькулятор) вот такую функцию:
Код: Выделить всё
-- lines without duplicates
function unique(a)
local q = {}
local t = {}
local k = 0
for i = 1, #a do
if q[a[i]] == nil then
k=k+1
q[a[i]] = ''
t[k] = a[i]
end
end
return t
end
Эта функция удаляет дубликаты в строках
без сортировки. Функция полезна, когда имеем на руках таблицу состоящую из большого количества строк и из которой нужно удалить дубликаты, при этом сама
сортировка не требуется. Сейчас же в калькуляторе удаление дубликатов делается только через функции "сортировка без дубликатов".
► Показать
for key, value in pairs(q) do решил избегать, т.к. в интернете вычитал, что эта процедура работает медленнее чем for i=1 to #s do
С учетом предложенной
function unique(l) (название и переменные поменяйте на ваше усмотрение) предлагаю изменить
function table.sortuniq(lines) на такой вариант:
Код: Выделить всё
function table.sortuniq(lines)
lines = unique(lines)
table.sort(lines)
return lines
end
Тогда получается, если удаление дубликатов применить к строкам первым, то количество строк (при наличии дубликатов) уменьшится. И такая ресурсозатратная процедура как сортировка отработает быстрее.
Скрипты для Demagog
Добавлено: 13 фев 2021 23:15
flegont
Я согласен, что нынешняя реализация удаления дубликатов через сортировку - это очень плохая идея. Но предложенный вами метод удаления оных тоже пока вызывает сомнение. Проблема в обоих случаях в том, что работает это только для таблиц с числовой индексацией. Но не для ассоциативных таблиц. А хочется какого-то общего метода...

Код: Выделить всё
t = {}
t['один'] = 1
t['два'] = 2
t['три'] = 1
d = unique(t) -- удаляем дубликаты
print(t['три']) -- напрасно ждали, что теперь будет nil
Скрипты для Demagog
Добавлено: 13 фев 2021 23:36
tonio_k
flegont писал(а): ↑13 фев 2021 23:15
А хочется какого-то общего метода...
а не получится тогда посудомоечный пылесос?
Пока после посуды не просохнет пылесосить не станет. Я к тому, что такой комбаин может оказаться не таким быстрым как отдельно посудомойка и хлеборезка. Для конкретных задач - пусть будет конкретное решение?
Скрипты для Demagog
Добавлено: 13 фев 2021 23:50
flegont
Может всё же попробовать через for key, value in pairs(a) do ...
Будет ли это приемлемо по скорости? А там уже определиться, каким путем идти...
Скрипты для Demagog
Добавлено: 14 фев 2021 09:37
flegont
Хотя, да... начать лучше с простого. Пусть будет unique для выявления строк без дубликатов. А общий случай рассмотрим как-нибудь потом.
Как-то так:
Код: Выделить всё
-- lines without duplicates
function unique(a)
local q, t = {}, {}
for i = 1, #a do
if not q[a[i]] then
q[a[i]] = true
t[#t+1] = a[i]
end
end
return t
end
Скрипты для Demagog
Добавлено: 14 фев 2021 12:00
Lecron
tonio_k,
flegont, Зачем проверять значение? Разве хэш-таблицы автоматически не поддерживают уникальность ключей? Или есть принципиальная разница, какая из уникальных строк в нее попадут, первая или последняя?
а если номер строки вообще не важен
Код: Выделить всё
local set = {}
for _, l in ipairs(a) do set[l] = true end
return set
Скрипты для Demagog
Добавлено: 14 фев 2021 12:27
tonio_k
Lecron писал(а): ↑14 фев 2021 12:00
Или есть принципиальная разница, какая из уникальных строк в нее попадут, первая или последняя?
я тоже сначала думал в этом направлении. Но при всём отсутствии принципиальной разницы руководствовался 2 моментами:
1)
поддерживают уникальность ключей?
мне это не известно, поэтому предположил, что предложенный вами первый пример это по сути многократная "перезапись" ячейки. Что быстрее перезапись ячейки или 2 операции: проверка наличия ячейки и при ее отсутствии добавление новой ячейки? Я сделал предположение что быстрее последнее.
2)
Сохранить общую структуру первоначального списка при удалении дубликатов может оказаться важным элементом. Например в ситуации удаления дубликатов в словаре dic чтобы сохранить его текущую пользовательскую сортировку.
Скрипты для Demagog
Добавлено: 14 фев 2021 14:40
Lecron
tonio_k писал(а): ↑14 фев 2021 12:27
>>поддерживают уникальность ключей?
мне это не известно,
Ну вообще-то это суть всех хэш-таблиц. Иначе как дважды записать ячейку по одному ключу?
t['1'] = 1
t['1'] = 2
А если значения не нужны, получаем уникальное множество (set).
tonio_k писал(а): ↑14 фев 2021 12:27
Что быстрее перезапись ячейки или 2 операции: проверка наличия ячейки и при ее отсутствии добавление новой ячейки?
Ваш сложнее. Вы дважды хэшируете строку и проводите поиск в таблице. Добавление записи так же производит поиск и только в случае отсутсвия делает вставку. Более того — трижды, т.к. работаете с двумя таблицами.
tonio_k писал(а): ↑14 фев 2021 12:27
Например в ситуации удаления дубликатов в словаре dic чтобы сохранить его текущую пользовательскую сортировку.
она и не должна изменится. По крайне мере в известных мне скриптовых языках порядок соответствует созданию. Да и проверить не сложно.
Код: Выделить всё
t['один'] = true
t['два'] = true
t['один'] = true
Должен вывести {один, два}, а не {два, один}.
Скрипты для Demagog
Добавлено: 14 фев 2021 19:10
flegont
Согласен, можно и не проверять значение.
и получаем набор уникальных ключей - дубликаты погасили друг друга. Осталось соорудить из них упорядоченную таблицу.
Код: Выделить всё
function unique2(a)
local q, t = {}, {}
for i = 1, #a do
q[a[i]] = true
end
for key, value in pairs(q) do
t[#t+1] = key
end
return t
end
Работает в среднем на 20% быстрее, но (в отличие от варианта, предложенного ув.
tonio_k) не сохраняет порядок строк. Он меняется при каждом выполнении скрипта.
Тест:
Код: Выделить всё
-- lines without duplicates
function unique(a)
local q, t = {}, {}
for i = 1, #a do
if not q[a[i]] then
q[a[i]] = true
t[#t+1] = a[i]
end
end
return t
end
function unique2(a)
local q, t = {}, {}
for i = 1, #a do
q[a[i]] = true
end
for key, value in pairs(q) do
t[#t+1] = key
end
return t
end
-- Test
-- формируем большую тестовую таблицу, изобилующую дубликатами
t = {}
for i = 1,1000000 do
t[#t+1] = '1)х.ыфЁ:66;%%?**'
end
for i = 1,1000000 do
t[#t+1] = '2)двести двадцать два миллиона попугаев'
end
for i = 1,1000000 do
t[#t+1] = '3)берег пруда был покрыт выкарабкивающимися из воды лягушками'
end
for i = 1,1000000 do
t[#t+1] = '4)odnA:Fnp0]q39487`253455fmdlsk*$#^YT&(*_)(e gjgf ,skf cj,frf'
end
for i = 1,1000000 do
t[#t+1] = '5)Жил-был великий писатель, Лев Николаич Толстой, Не ел он ни рыбы ни мяса, ходил совершенно босой. Жена его - Софья Толстая, напротив, любила поесть. Она не ходила босая, спасая фамильную честь.'
end
z = os.clock()
d = unique(t)
time = os.clock()-z
print('\149 unicue. time= ',time)
for i = 1,#d do
print(d[i])
end
print()
z = os.clock()
d = unique2(t)
time = os.clock()-z
print('\149 unicue2. time= ',time)
for i = 1,#d do
print(d[i])
end
Результат одного из прогонов:
Код: Выделить всё
# Script>-- lines without duplicates2.txt
• unicue. time= 0.17199999999957
1)х.ыфЁ:66;%%?**
2)двести двадцать два миллиона попугаев
3)берег пруда был покрыт выкарабкивающимися из воды лягушками
4)odnA:Fnp0]q39487`253455fmdlsk*$#^YT&(*_)(e gjgf ,skf cj,frf
5)Жил-был великий писатель, Лев Николаич Толстой, Не ел он ни рыбы ни мяса, ходил совершенно босой. Жена его - Софья Толстая, напротив, любила поесть. Она не ходила босая, спасая фамильную честь.
• unicue2. time= 0.15599999999995
1)х.ыфЁ:66;%%?**
5)Жил-был великий писатель, Лев Николаич Толстой, Не ел он ни рыбы ни мяса, ходил совершенно босой. Жена его - Софья Толстая, напротив, любила поесть. Она не ходила босая, спасая фамильную честь.
2)двести двадцать два миллиона попугаев
4)odnA:Fnp0]q39487`253455fmdlsk*$#^YT&(*_)(e gjgf ,skf cj,frf
3)берег пруда был покрыт выкарабкивающимися из воды лягушками
Как видим, действительно имеется выигрыш по времени. 0,016 секунды для таблицы из 5 миллионов строк.
Скрипты для Demagog
Добавлено: 14 фев 2021 20:10
Lecron
flegont писал(а): ↑14 фев 2021 19:10
Осталось соорудить из них упорядоченную таблицу.
Зачем? Если неудобно читать ключи, просто пишите
Код: Выделить всё
for _, line in ipairs(a) do set[line] = line end
Где ключ и значение таблицы одна и та же строка. Перегрузки по памяти не будет, так как пишется ссылка на одинаковую область памяти.
flegont писал(а): ↑14 фев 2021 19:10
но (в отличие от варианта, предложенного ув. tonio_k) не сохраняет порядок строк.
Тут надо смотреть внимательнее. Почему t[int] сохраняет порядок, а t[str] нет?
Все упирается в результат эксперимента
Код: Выделить всё
t['один'] = 'один'
t['два'] = 'два'
t['один'] = 'один'
flegont писал(а): ↑14 фев 2021 19:10
Как видим, действительно имеется выигрыш по времени. 0,016 секунды для таблицы из 5 миллионов строк.
Борюсь не за время, а за понятность кода.
Если повторное присваивание значения ключу таки меняет порядок следования, вторая таблица все равно не нужна. Просто не присваиваем повторно.
Код: Выделить всё
function unique(a)
local set = {}
for _, line in ipairs(a) do
if set[line] == nil then
set[line] = line
end
end
return set
end
Скрипты для Demagog
Добавлено: 14 фев 2021 21:03
wasyaka
tonio_k писал(а): ↑13 фев 2021 22:28
у меня тут такое рационализаторское предложение.
Стока букв и символов...
А на пальцах - зачем это?
flegont писал(а): ↑13 фев 2021 23:15
реализация удаления дубликатов( героически начудим а потом героически удалим)
А не проще - не добавлять?
Скрипты для Demagog
Добавлено: 14 фев 2021 21:11
flegont
Lecron писал(а): ↑14 фев 2021 20:10
Борюсь не за время, а за понятность кода
Заменяю в своем примере unique2 на вариант от ув.
Lecron, и запускаю скрипт. Результат:
Код: Выделить всё
# Script>-- lines without duplicates2.txt
• unicue. time= 0.178
1)х.ыфЁ:66;%%?**
2)двести двадцать два миллиона попугаев
3)берег пруда был покрыт выкарабкивающимися из воды лягушками
4)odnA:Fnp0]q39487`253455fmdlsk*$#^YT&(*_)(e gjgf ,skf cj,frf
5)Жил-был великий писатель, Лев Николаич Толстой, Не ел он ни рыбы ни мяса, ходил совершенно босой. Жена его - Софья Толстая, напртив, любила поесть. Она не ходила босая, спасая фамильную честь.
• unicue2. time= 0.35999999999999
Время выполнения стало в 2 раза больше, чем в варианте
tonio_k и при этом возвращается пустая таблица.
Скрипты для Demagog
Добавлено: 14 фев 2021 21:41
Lecron
flegont писал(а): ↑14 фев 2021 21:11
Заменяю в своем примере unique2 на вариант от ув. Lecron
Для меня lua сильно иностранный язык. Предполагаю наличие синтаксических ошибок в коде. Но я говорю про алгоритм, а не сам код. Зачем строки хранить в таблице с сурогатным числовым ключом, а флаги присутствия строк в таблице с текстовым?
flegont писал(а): ↑14 фев 2021 21:11
и при этом возвращается пустая таблица.
И почему она возвращается, если все что я делаю
?
На счет времени, отличие еще в способе иттерации, через индекс или по самим значениям. Вы лучше знаете язык, вам и карты в руки. Сами понимаете, работа с одной таблицей, не может быть больше чем с двумя.
Скрипты для Demagog
Добавлено: 14 фев 2021 22:42
tonio_k
wasyaka писал(а): ↑14 фев 2021 21:03
А на пальцах - зачем это?
а без много букв на пальцах не объяснить
► Показать
http://i91650e3.beget.tech/viewtopic.php?t=122&start=200#p1782 тогда
решение было предложено логичное и понятное по принципу: сначала сортируем строки по алфавиту, затем перебираем строки друг за другом с самого начала и сравниваем соседние строки.
Если следующая строка равна текущей - удаляем дубликат. Такой вариант всех устроил и его оставили как стандартное решение. "Рационализаторство" заключается в предложении поменять местами последовательность действий: Сначала удалять дубликаты - тем самым сделав количество строк меньше и уже оставшиеся строки сортировать. Удалить дубликаты, как оказалось, можно быстро всего за один проход перебрав все строки. При этом строки не обязательно должны быть отсортированы. А вот сортировка (по своей сути) это перебор строк и причем неоднократный (т.е. долго). Например, имея список состоящий из трех разных строк и если их продублировать миллион раз, то "по старому" миллион строк сначала будет сортироваться (это долго) и лишь потом удалять дубли. А "по новому" - это удалить все дубли (это быстро) и останется отсортировать всего три строки. Далее идут нюансы - вот их сейчас обсуждают.
Скрипты для Demagog
Добавлено: 14 фев 2021 23:30
flegont
Ради полноты эксперимента, подсчитал для своего контрольного примера время сортировки (обычной алфавитной, как table.sort(t) ).
Для 5 млн строк время сортировки = 10.794 сек
А удаление дубликатов по времени = 0.175 сек
Разница более чем в 60 раз.
Т.о. проверка на дубликаты занимает ничтожное время, и если они действительно были в большом количестве, то их удаление заметно ускорит сортировку.
Скрипты для Demagog
Добавлено: 15 фев 2021 17:06
wasyaka
tonio_k писал(а): ↑14 фев 2021 22:42
Далее идут нюансы - вот их сейчас обсуждают.
http://i91650e3.beget.tech/viewtopic.php?t=59&start=750
Сборка:
DemagogYandexUni.rar от ув.
speeck
Словарь
11. 51_ОМОГРАФЫ_птр
Затрачено буквально пара минут
Итог
Словарь очищенный от
"неомографов" в сортировке по Омографам и по алфавиту в пределах омографа (дубликаты не обнаружены)
(При желании в любой сортировке)
И сами
"неомографы"
С учётом того, что это редко - довольно редко - применяемая функция - зачем заморачиваться?
А вот функция
добавить в словарь которая сразу бы отсекала всё непотребное - была бы очень полезна.
Скрипты для Demagog
Добавлено: 18 фев 2021 11:46
tonio_k
Захотел сделать функцию сканирование папки со всеми подкаталогами и получение списка путей ко всем файлам по маске. Но почему-то у меня одна строчка отказывается работать.
Черновик функции:
Код: Выделить всё
function DirFolder(f,m)
local s = io.popen('dir '..f..m..' /B /S /O:S', 'r' )
s = s:read "*a"
s = DosToAnsi(s)
s = string.split(s,'\r')-- таблицу
GaugeInit(#s)
for i=1,#s do
Gauge(i)
--if FileExists(s[i]) then print(s[i]) end
print(s[i])
end
Gauge(0)
s = table.concat(s,'\r') -- в текст
s = string.gsub(s,'[\r\n]+','\r')
return(s)
end
Пример использования:
Код: Выделить всё
f='D:\\tmp\\Книги\\'
m = '*.txt'--маска
DirFolder(f,m)
Пример рабочий в плане: в функции строка без ремарки
print список путей выводит (причем, список вместе с папками)
Но если я хочу проверить является ли указанный путь именно к файлу а не к папке, то ставим ремарку к
print и пробуем разремарить
FileExists - так уже вообще ничего не выводит. Ощущение, что
FileExists не понимает предлагаемый путь либо где то у меня ошибка.
Скрипты для Demagog
Добавлено: 18 фев 2021 13:04
Lecron
tonio_k, Желательно публиковать еще и вывод (часть вывода) успешного варианта.
В таких случаях, начинаю с print(FileExists(s)), а потом играть с входным параметром. Если исключить существование ошибок в FileExists, можете накосячить только в излишнем преобразовании DosToAnsi.
Но может проще исключить каталоги сразу dir /A-D ?
Скрипты для Demagog
Добавлено: 18 фев 2021 13:13
flegont
FileExists(f)- возвращает true, если файл с именем f существует; и false в противном случае
Exists(f) - существует ли файл или папка f; возвращает true / false и код ошибки
IsFolder(f) - существует ли папка f; возвращает true / false
Скрипты для Demagog
Добавлено: 18 фев 2021 13:38
tonio_k
Нашел ошибку.
DOS выводит текст с символом-разделителем строк '\n'. А я по привычке пытаюсь сделать таблицу с символом-разделителем строк '\r'. В результате вместо списка получаю все пути в одну сплошную строку. Поправил так:
Код: Выделить всё
--вывести содержимое указанной папки вместе с подкаталогами.
--полученный cписок будет отсортирован по размеру файлов (по возрастанию)
function DirFolder(f,m)
local s = io.popen('dir '..f..m..' /B /S /O:S', 'r' )
s = s:read "*a"
s = DosToAnsi(s)
s = string.gsub(s,'[\r\n]+','\r') -- заменяю все варианты разделителей на '\r'
s = string.split(s,'\r')
local t={}
local u=0
for i=1,#s do
if FileExists(s[i]) then
u=u+1
t[u]=s[i]
end
end
s=nil
return(t)
end
Пример для тестирования:
Код: Выделить всё
f='D:\\tmp\\Книги\\'-- путь к папке
m = '*.*'-- маска файла "*.*" "*.fb2" "*00*.txt"
s=DirFolder(f,m)
for i=1, #s do
print(s[i])
end
Скрипты для Demagog
Добавлено: 18 фев 2021 13:46
Lecron
tonio_k, Глядя на ужасно нелогичный набор функций Exists, FileExists, IsFolder, хочу предостеречь от аналогичной ошибки. Делайте две функции DirItems(path, recursive) и DirFiles(path, mask, recursive), когда вторая будет вызывать первую и только фильтровать ее вывод. В идеале, маску вообще надо фильтровать отдельно, по месту приемения. Но в данном случае кмк это избыточно, таки не файловую библиотеку пишем.
Скрипты для Demagog
Добавлено: 18 фев 2021 13:57
Lecron
tonio_k писал(а): ↑18 фев 2021 13:38
s = string.gsub(s,'[\r\n]+','\r') -- заменяю все варианты разделителей на '\r'
s = string.split(s,'\r')
А сразу s = string.split(s,'\r\n') язык умеет? Нам здесь универсальность не нужна. Прграмма не кроссплатформенна и работатет только с выводом функции dir.
Скрипты для Demagog
Добавлено: 18 фев 2021 14:11
tonio_k
Lecron писал(а): ↑18 фев 2021 13:46
ужасно нелогичный набор функций Exists, FileExists, IsFolder
а что в них не так? очень удобные в использовании и понимании. В своих скриптах активно применяю.
Lecron писал(а): ↑18 фев 2021 13:46
хочу предостеречь от аналогичной ошибки
а моя ошибка с этими функциями вообще никак не связана. Проблема в разбитии текста полученного от DOS команды dir (ну забыл я что DOS и блокнот любят разделитель '\n). Почему вообще полез в DOS? Потому что AllFiles(folder, mask) получает список файлов только из конкретной папки, а мне нужно было получить со всеми подкаталогами, причем отсортированный по размеру файлов в порядке убывания. Команда dir может одним махом такой список получить, причем сразу отсортированный по возрастанию размеров файлов. "отзеркалить" список, что бы сортировка с "по возрастанию" стало "в порядке убывания" - это уже не проблема.
Lecron писал(а): ↑18 фев 2021 13:57
А сразу s = string.split(s,'\r\n') язык умеет?
умеет, но я же не программист что бы тонкости знать. А если текст корявый и разделитель в нем '\n\r' будет, тогда s = string.split(s,'\r\n') сработает? Или порядок символов не важен?
Скрипты для Demagog
Добавлено: 18 фев 2021 14:26
Lecron
tonio_k писал(а): ↑18 фев 2021 14:11
а что в них не так? очень удобные в использовании и понимании. В своих скриптах активно применяю.
Не так с организацией. Нарушение принципа единственной ответсвенности и единого наименования. Exists должна проверять существование файлового объекта, а IsFile и IsFolder только принадлежность к типу.
tonio_k писал(а): ↑18 фев 2021 14:11
а моя ошибка с этими функциями вообще никак не связана.
Дело не в ошибке. Есть такое понятие как инкапсуляция (гугл в помощь))). Вы заворачиваете io.popen и трансформацию вывода в функцию... и больше никогда об этом не думаете. В остальных местах работая уже с готовым списком путей.
tonio_k писал(а): ↑18 фев 2021 14:11
Команда dir может одним махом такой список получить,
После обсуждения обработки многих миллионов строк, обращать на это внимание, себя не уважать. Для интерпретатора, любые существующие объемы вывода dir, это ничто.
tonio_k писал(а): ↑18 фев 2021 14:11
умеет, но я же не программист что бы тонкости знать.
А я думал, что это простая логика))) Я тоже lua не знаю. Даже меньше вашего.
tonio_k писал(а): ↑18 фев 2021 14:11
А если текст корявый и разделитель в нем '\n\r' будет, тогда s = string.split(s,'\r\n') сработает? Или порядок символов не важен?
Порядок символов важен. Только измениться он не может. Функция dir как выводила данные 20 лет назад, так и через 20 будет выводить.
Скрипты для Demagog
Добавлено: 18 фев 2021 14:42
flegont
string.split - не входит в состав Lua. Это - самоделка, найденая в Инете. Так же, как вышеперечисленные FileExists, Exists, IsFolder. Я стараюсь не изобретать велосипеды сверх необходимости - почти все они уже изобретены. Если что-то пригодилось - используем, не оправдало ожиданий - выбросим.
А работает string.split очень интересно. Каждый символ, перечисленный во втором параметре, будет воспринят, как самостоятельный разделитель.
Код: Выделить всё
s = 'a1bra2ka3da4bra'
a = string.split(s,'1234')
for i = 1,#a do
print(a[i])
end
Результат:
a
bra
ka
da
bra
Скрипты для Demagog
Добавлено: 18 фев 2021 14:51
flegont
P.S. А что касается абстракции, наследования, инкапсуляции и полиморфизма, то (извиняюсь за оффтоп), как показала жизнь
ООП - это катастрофа на триллион долларов
Скрипты для Demagog
Добавлено: 18 фев 2021 14:57
tonio_k
flegont писал(а): ↑18 фев 2021 14:42
Каждый символ, перечисленный во втором параметре, будет воспринят, как самостоятельный разделитель.
более того, получается что разделитель '1234' это аналогично выражению
[1234]+ (с плюсиком) в регулярках. Буду иметь в виду. С такой трактовкой буду смелее использовать (и более широко применять) эту функцию
Код: Выделить всё
s = 'a1bra2ka3da4bra3113131sim444536031'
a = string.split(s,'1234')
for i = 1,#a do
print(a[i])
end
#Результат:
a
bra
ka
da
bra
sim
5
60
Скрипты для Demagog
Добавлено: 18 фев 2021 15:12
Lecron
flegont писал(а): ↑18 фев 2021 14:51
как показала жизнь
В-первых, любая крайность — катастрофа. Во-вторых — прошу прощения, не совсем верно выразился. Скорее переиспользование, как капсуляция сложности.
Нужно ли оно? Если dir еще используется или предполагается использовать хоть где-то, то нужно. Нет — значит нет.
Скрипты для Demagog
Добавлено: 22 фев 2021 20:20
tonio_k
Пример получение контрольной суммы файла (хэш-суммы)
Код: Выделить всё
a=OpenDialog(true)
if a==nil then goto HALT end
item={'MD2','MD4','MD5','SHA1','SHA256','SHA384','SHA512',}
shapka = " Выберите криптографический хеш:"
dial = Menu(shapka,item,4)
if dial == 0 then goto HALT end
for i=1, #a do
local s = io.popen('certutil -hashfile "'..a[i]..'" '..item[dial], 'r' )
s = s:read "*a"
s = string.split(s,'\r\n')
s[2] = string.gsub(s[2],' ','')--удалить пробелы
print(s[2])
print(a[i])
print()
end
::HALT::
скрипт использует встроенную в Windows Certutil.exe
Скрипты для Demagog
Добавлено: 22 фев 2021 23:48
flegont
Наверное так:
Код: Выделить всё
f = io.popen(...)
s = f:read "*a"
f:close()
Скрипты для Demagog
Добавлено: 26 фев 2021 11:51
юрабойко
Мне нужен скрипт для автоматически расставить коммы после каждого слова или через одно, кроме коротких - не более 3 или 5 букв?
Если комма, это запятая, то во-первых так и пишите, а во-вторых любая из программ на форуме, поддерживающая rex словари это умеет.
\b\w{5,}(?=\s)=$0,
Шаблон начинающийся с начала слова, содержащий не менее 5 букв и не заканчивающийся пробелом (чтобы не зацепить знаки препинания), заменить на шаблон+запятая. Для "через одно" — \b\w+\s\w{5,}. Может какие-то нюансы не учел, но принцип такой, регулярки для этого и созданы. Если словарь не распознается из-за второго знака равно, заменить этот блок на негативный (?![\.\!\?,:])
Желательно подобный пример дайте, программу для редактирования файлов если надо тоже просьба напомнить.
Скрипты для Demagog
Добавлено: 26 фев 2021 12:07
юрабойко
Еще одна деталь - я уже пробовал заменить все знаки препинания на пробелы или запятые, потом командой найти заменить убрал все лишние пробелы, потом заменил все пробелы на это:
пробеле + запятая + пробел.
Результат прослушивания после этого в балаболке мне целом понравился, но коробит дискомфорт от длинной паузы после каждого слоова из одной буквы, но скорее всего так будет со всеми словати из пяти букв, и почти с гарантией - из трех букв.