Страница 11 из 13
Скрипты для Demagog
Добавлено: 26 июл 2020 15:45
tonio_k
flegont,

работает как надо!
Скрипты для Demagog
Добавлено: 27 июл 2020 22:33
tonio_k
Вопрос по функции
WSel
Вставим ниже текст в окно Демагога и нажимаем F2
Если выделить текст
ind то покажет k = 3
Вопрос, а как можно определить начальную позицию выделенного текста?
Если бы WSel показывал начальную позицию, то координаты текста я бы мог получить:
Код: Выделить всё
ind=WActive()
k=WSel(ind)
fnd=WSelText(ind)
ShowMessage(k..', '..#fnd)
Скрипты для Demagog
Добавлено: 27 июл 2020 23:53
flegont
Мда... думаю, надо будет усовершенствовать функцию WSel(i), когда задан только параметр - номер окна. Чтобы, если в тексте есть выделенный фрагмент, то возвращалась бы
начальная позиция выделенного (а не конечная, как сейчас), и возвращалась бы
длина выделенного. Как-то так:
Тогда конечная позиция выделенного была бы:
Подумаю, как сделать.
Скрипты для Demagog
Добавлено: 28 июл 2020 00:19
tonio_k
Я тут ещё немного подумал, у нас же на руках есть длина текста #fnd и координата
конца текста.
Можно от координаты конца выделеного текста вычесть его длину и прибавить 1 это и будет начальная координата выделенного текста
Код: Выделить всё
ind=WActive()
k=WSel(ind)
fnd=WSelText(ind)
start=k-#fnd+1
ShowMessage(start..', '..#fnd)
Надо только для удобства это в функцию превратить
k, len = WSel(ind), что бы k действительно был начальной позицией выделеного текста.
Скрипты для Demagog
Добавлено: 28 июл 2020 10:12
flegont
Вер. 385, небольшое изменение в дистрибутиве.
Функция встроенного интерпретатора:
WSel(i , pos, len) - выделяет фрагмент текста во вкладке i с позиции pos длиной len (по умолчанию 0); и возвращает pos и len;
WSel(i, pos) устанавливает текстовый курсор в позицию pos, возвращая pos и 0;
WSel(i) просто возвращает текущую позицию курсора и длину выделенного (или 0),
(это и есть тот случай, когда возвращаемые значения реально могут понадобиться  )
)
Пример:
Код: Выделить всё
-- пусть текст во вкладке 1 имеет выделенный фрагмент
k, len = WSel(1)
s = WText(1)
c = string.sub(s,k+1,k+len)
ShowMessage(k..' '..len..' |'..c..'|') -- посмотрим на результат
Замечание: при поиске в тексте выделенного фрагмента к найденной координате его начала прибавляем 1, т.к. позиции текстового курсора на экране нумеруются с 0.
Скрипты для Demagog
Добавлено: 20 авг 2020 08:02
PETICANTROP
Добрый день не очень силен в работах скрипта, при попытке обработать произведение через скрипт "10_ОКНО ОБРАБОТАТЬ СЛОВАРЯМИ" выбирается небольшой фрагмент для обработки и на этом процесс зависает. Подскажите в чем может быть проблема.
Скрипты для Demagog
Добавлено: 20 авг 2020 09:52
tonio_k
PETICANTROP, в этой ветке обсуждают общие технические вопросы по скриптам. Автор Демагога не может ответить почему не работает та или иная "поделка" пользователя т.к. в её создании он не участвовал. Ваш вопрос касается пользовательской сборки. Задайте свой вопрос в той ветке где скачали сборку. При этом уточните, какой голос вы используете, меняли ли вы что нибудь в сборке. Какую версию сборки применяете. Зависает на всех книгах или только на конкретной одной. Нужно понять (локализовать) где проблема. Иначе на ваш неконкретный вопрос будет ответ: "а у нас работает".
Скрипты для Demagog
Добавлено: 20 авг 2020 14:44
PETICANTROP
tonio_k, Благодарю за напутствие полез разбираться со сборками и понял что сам накрутил ерунды всякой. Скачал вашу сборку и все заработало. Спасибо вам за труды.
Скрипты для Demagog
Добавлено: 05 сен 2020 12:29
flegont
Пример использования функций встроенного интерпретатора:
RuIPA, RuUPS.
(Demagog, вер. 386, сборка от
04.09.2020)
Скрипт для создания фонетического dic-словаря
Название любое, расширение .lua
Поместить в папку _Tests_
В активной вкладке должен находиться список русских слов - все буквы в нижнем регистре, а ударные гласные - в верхнем регистре.
Вызов скрипта - из меню по Ctrl+F2
Во вкладке "0 - Статистика" будет сформирован соответствующий dic-словарь - его можно сохранить под каким-либо именем и с расширением .dic
Код: Выделить всё
-- Создать фонетический dic-словарь в окне "0 - Статистика"
-- по списку слов с ударениями, находящемуся в активной вкладке.
-- Например:
-- вЫкатившиеся
-- двадцатИ
-- темнО
os.setlocale('', 'ctype') -- национальная кодовая страница
cap = 'Укажите тип транскрипции'
items = {
'Международный фонетический алфавит (IPA)',
'Microsoft Universal Phone Set (UPS)'
}
ans = Menu(cap,items)
if ans == 0 then goto HALT end
if ans == 1 then
-- шаблон тега Pronunciation Lexicon Specification
mask = '<phoneme ph="@"/>'
else
-- шаблон тега Microsoft SAPI5
mask = '<PRON SYM="@"/>'
end
ind = WActive() -- номер активной вкладки
bom = '\239\187\191' -- спецификация UTF-8
s = WText(ind)
a = string.split(s,'\r')
c = ''
for i = 1,#a do
if a[i] ~= '' then
if ans == 1 then d = RuIPA(a[i]) else d = RuUPS(a[i]) end
b = string.lower(a[i])
b = AnsiToUtf8(b)
c = c..b..'='..string.gsub(mask,'@',d)..'\r'
end
end
-- передадим новый utf8-текст во вкладку 0
-- через сохранение во временном файле
c = bom..c
SaveToFile({c},'_.tmp')
WOpen(-1,'_.tmp'); WNew(0); WAdd(0,-1,'\r\r')
os.remove('_.tmp')
WActive(0)
::HALT::
os.setlocale('C')
Пример.
Текст в активной вкладке:
Результаты (в зависимости от выбора пользователя):
Код: Выделить всё
выкатившиеся=<phoneme ph="vˈɨkətʲɪfʂᵻjəsʲə"/>
двадцати=<phoneme ph="dvətt͡sɐtʲˈi"/>
темно=<phoneme ph="tʲɪmnˈo"/>
Код: Выделить всё
выкатившиеся=<PRON SYM="V S1 IX K AX T pal IH F SR IX low J AX S pal AX"/>
двадцати=<PRON SYM="D V AX T TS AEX T pal S1 I"/>
темно=<PRON SYM="T pal IH M N S1 O"/>
Скрипты для Demagog
Добавлено: 16 сен 2020 22:29
tonio_k
есть в шпаргалке функция:
WordFrequency(s, gauger) - подсчитывает частоту слов в тексте s; возвращает таблицу строк вида: 'частота|слово'
В калькуляторе видно, что в этой функции присутствует цифровая сортировка.
А можно добавить в калькулятор отдельно функции:
-сортировка цифровая по убыванию
-сортировка цифровая по возрастанию
Скрипты для Demagog
Добавлено: 17 сен 2020 19:58
flegont
Да, можно. Подумаю над этим.
Скрипты для Demagog
Добавлено: 18 сен 2020 11:38
flegont
Вер. 386, сборка от 22.09.2020
[+] Функция встроенного интерпретатора
table.sortdig(lines, mode) - сортирует таблицу строк lines, по их цифровому содержимому, по возрастанию, если mode = true и по убыванию, если mode = false или nil. Цифровое содержимое в строке ищется до первого символа табуляции (если он есть).
Пример использования:
Код: Выделить всё
-- цифры могут быть в любом месте строки
-- но учитываются только до знака табуляции (если он есть)
-- здесь в строках нет знака табуляции
a = {
'абрикос123',
'корабль 7К-Л1',
'миг-17б',
'восток-1',
'агент 007'
}
a = table.sortdig(a,true) -- по возрастанию
s = table.concat(a,'\r')
print(s)
print()
-- здесь в строках присутствует знак табуляции
a = {
'17 миг',
'123 абрикос',
'1 восток',
'71 корабль',
'7 агент'
}
a = table.sortdig(a) -- по убыванию
s = table.concat(a,'\r')
print(s)
Результат:
Код: Выделить всё
восток-1
агент 007
миг-17б
корабль 7К-Л1
абрикос123
123 абрикос
71 корабль
17 миг
7 агент
1 восток
Скрипты для Demagog
Добавлено: 30 сен 2020 12:11
tonio_k
flegont писал(а): ↑15 июл 2020 12:18
FreqConsolidate(i, j, delim, tmpfile)
Вставляем в окно 1 (код ниже) и нажимаем F2. Смотрим результат в окне 2 - крякобрязы.
Код: Выделить всё
-- Функция, консолидирующий статистику частотности строк из вкладки i в j
-- Каждая запись исходного списка в i имеет вид: ЧастотаРазделительСтрока
-- При этом строки справа от Разделитель могут дублироваться.
-- После обработки дубликаты будут удалены, частоты просуммированы
function FreqConsolidate(i, j, delim, tmpfile)
if delim == nil then delim = '|' end
if tmpfile == nil then tmpfile = 'tmp.txt' end
-- вспомогательные функции
local function DelUtf8BOM(s)
local bom = '\239\187\191'
if string.sub(s,1,3) == bom then s = string.sub(s,4,#s) end
return s
end
local function AddUtf8BOM(s)
return '\239\187\191'..s
end
-- основная процедура
os.setlocale('', 'ctype') -- для работы с национальной локалью
-- заботимся о сохранении юникодных символов
local o = {}
o.File_Encoding = feUTF8
Settings(o)
WSave(i,tmpfile)
local a = LoadFromFile(tmpfile)
a[1] = DelUtf8BOM(a[1])
-- консолидируем статистику
local c = {}
local b
for i = 1,#a do
b = string.split(a[i],delim)
if #b > 1 then
if c[b[2]] == nil then
c[b[2]] = tonumber(b[1])
else
c[b[2]] = c[b[2]]+tonumber(b[1])
end
end
end
local d = ''
for k, v in pairs(c) do
d = d..v..delim..k..'\r'
end
-- опять же, заботимся о юникоде
AddUtf8BOM(d)
SaveToFile({d},tmpfile)
-- готово!
WOpen(j,tmpfile)
if i ~= j then WNew(i) end
--os.setlocale('C') -- вернуть стандартную локаль
end
WNew(2,[[4 (\S| -)\s(\bчаса\b)(\.\.\.|\,)=$1 часА$3
80 [ ]+=
]])
FreqConsolidate(2, 2, "\9") -- подсчет статистики
Подскажите что поправить?
Что интересно, если поменять строку:
Код: Выделить всё
WNew(2,[[4 (\S| -)\s(\bчаса\b)(\.\.\.|\,)=$1 часА$3
80 [ ]+=
]])
на
Код: Выделить всё
WNew(2,[[1 (\b(без|без [егоёих]{1,3}|вашего|вместо|возле|возле [егоёих]{1,3}|выше|выше [егоёих]{1,3}|два|для|для [егоёих]{1,3}|до|до [егоёих]{1,3}|ему|из|из [запод]{1,3}|какого то|какого тоъ|кроме|кроме [егоёих]{1,3}|мало|мне ни|моего|нет|нет у меня|ни|никому не|ну|оба|оба [егоёихэт]{1,3}|от|от [егоёих]{1,3}|после|против|против [егоёих]{1,3}|со|с [егоёих]{1,3}|своего|смысле|такого|твоего|три|у|у [егоёих]{1,3}|четыре|этого)\b\s?(\w+)?)\s{1,4}(\bслова\b)=$1 слОва
1 (авят|ает|аешь|азал|айте|аны|анял|ать|ашел|!ают|[м]ают|ая|[вмрч]ая|[вмрх]али|ашли|взял|вшим|даем|етны|ечал|зна[лю]|зови|иеся|ими|ируя|ись|ить|ймут|[вкмнч]ать|идал|кали|[вл]или|лены|[мн]ает|ньи|няли|[лн]ять|[рч]ала|руем|ших|ые|ющей|ющих|яют|[вджшщ]ние|гие|жие|кие|хие|чие|шие|щие)(\s*\w*\s*\w*\s*\w*\s*)\s+(места)\b=$1$2 местА
1 @(\w+)([,: -]*)\s+Том([аеуомыи]+)\b=$1$2 ЪЪтОм$3
1156 [ ]+=
1 \b(ей|на|под|ту же|эту)\b(\s*\w*\s*)\s+полку\b=$1$2 пОлку
1 \b(из|к|по)\b\s+(\bдому\b)=$1 дОму
1 ЪЪтОм(\w+)=тОм$1]])
то крякабразов не будет! Собственно, по этой причине ранее и не выявил проблему.
Скрипты для Demagog
Добавлено: 30 сен 2020 18:04
flegont
Кракозябры будут всегда, просто иногда их не сразу видно в общей куче.
Причина - в совершенно нелепой опечатке: в функции FreqConsolidate в конце пропущено 2 символа (обозначены красным):
...
d = AddUtf8BOM(d)
SaveToFile({d},tmpfile)
...
И результирующий временный файл записывался в кодировке UTF-8 без BOM. Отчего Демагог неправильно загружал его в назначенное окно

P.S. А если в Демагоге была включена Настройка эвристического распознавания кодировки русскоязычных файлов, то иногда результат отображался совершенно верно! Когда русский текст в нем достаточно длинный!

Скрипты для Demagog
Добавлено: 30 сен 2020 18:32
tonio_k
tonio_k писал(а): ↑30 сен 2020 12:11
включена Настройка эвристического распознавания
вот в чем дело! А я никак не мог понять причину "плавающей" ошибки. Отключить что ли её, что бы мозги потом не ломать почему, то работает, то не работает?
Скрипты для Demagog
Добавлено: 30 сен 2020 19:01
flegont
По умолчанию "Эвристическое распознавание кодировки русскоязычных текстов" - ОТКЛЮЧЕНО. И я настоятельно рекомендую включать его только в самых крайних случаях! И сразу же отключать, после того, как проблемный файл распознан и пересохранен в нормальной кодировке.
Скрипты для Demagog
Добавлено: 02 окт 2020 12:39
юрабойко
Просьба написать как просто и быстро, расставить ударения слов. Так чтобы все было ясно даже для нуба - возможности отредактировать всю большую книгу вручную у меня нет, глаза устанут намного раньше средины книги. Хотя возможно главу или две отредактирую до этого.
Если возможно я бы вообще расставлял ударения в словах одним или несколькими нажатиями кнопок. Если нет - расставлю их лишь в тех словах которые произносятся хуже всех.
Скрипты для Demagog
Добавлено: 02 окт 2020 13:06
tonio_k
юрабойко писал(а): ↑02 окт 2020 12:39
Если возможно я бы вообще расставлял ударения в словах одним или несколькими нажатиями кнопок. Если нет - расставлю их лишь в тех словах которые произносятся хуже всех.
вы опишите, какие действия выхотите сделать? Например выделить слово
огнедышащий двойным кликом мыши, нажать комбинацию клавиш и вам к этому слову выйдет окно с вариантами:
Код: Выделить всё
Огнедышащий
огнЕдышащий
огнедЫшащий
огнедышАщий
огнедышащИй
огнедышащиЙ
Вы щелкаете по одному из них и это слово исправляется в тексте книги на выбранное.
Скрипты для Demagog
Добавлено: 02 окт 2020 13:20
юрабойко
Ясно, надо заменить в слове одну букву на другую.
Только что пробовал прослушать слово телега через демагог - произносит куда лучше чем в балаболке, в ней первый слог вообще не слышен.
Но ваш пример все равно может очень пригодиться для некоторых слов.
На балоболку судя по всему стоит забить - автор программы ее улучшать не будет.
Скрипты для Demagog
Добавлено: 02 окт 2020 13:34
tonio_k
юрабойко писал(а): ↑02 окт 2020 13:20
автор программы ее улучшать не будет.
вот вы зря так. Балаболка очень продуманная программа и активно обновляется. Произносит вслух не Балаболка, а голосовой движок. Реакция на изменение регистра букв возникает только при наличие соответсвующих словарей. Какие словари, какой голосовой движок вы используете вы не указали. Может у вас голая Балаболка без словарей?
UPD обращаю ваше внимание, что описанный выше вариант решается средствами скрипта. Т.е. это не штатная функция Демагога, а пользовательская доработка, которую вы и сами можете создавать и применять для собственных нужд.
Скрипты для Demagog
Добавлено: 02 окт 2020 17:03
flegont
Скажем так: штатной функцией Демагога (и довольно полезной, как показала практика) является т.н. "встроенный интерпретатор". С его помощью продвинутые пользователи могут создавать (и создают!) различные скрипты, сообразно собственным нуждам. Таким образом, "творчеством масс" расширяются функциональные возможности Демагога
Скрипты для Demagog
Добавлено: 02 окт 2020 19:20
юрабойко
Со словарями для нее. Я поэкспериментировал - на скорости ноль балаболка у меня очень часто глотает начало или конец некоторых слов, многие короткие слова на скорости ноль вообще можно не услышать.
Возможно тут даже не Балаболка виновата - как я в последний месяц не переставлял Виндовс, а есть сомнения в его стабильности. В тоже время не нашел вирусы на компьютере.
Короче для меня комфортной является скорость чтения минус два если не минус три. Если в тексте есть одни длинные слова - возможно минус один. На скорости ноль в каждом среднем абзаце как минимум пару слов не разберешь - пример первый слог слова телега, стоит послушать чуть дольше часа и потом такое происходит постоянно. Причем закрываю балаболку и открываю ее снова - ничего не меняется к лучшему.
Скрипты для Demagog
Добавлено: 04 окт 2020 13:54
tonio_k
Подскажите, как сделать поиск в тексте utf8 без BOM любого символа не входящего в ANSI таблицу?
Это нужно для предварительной проверки текста перед s=WText (1) что бы точно знать, что никакой символ utf8 в знак "?" не превратится
Скрипты для Demagog
Добавлено: 04 окт 2020 14:27
flegont
Предположим:
1) в файле proverka.txt находится текст в кодировке utf8
2) и в этом тексте нигде не встречается знак подчеркивания _
Тогда ответ на ваш вопрос даст следующий скрипт:
Код: Выделить всё
a = LoadFromFile('proverka.txt')
s = table.concat(a,'\r')
_, n = string.gsub(Utf8ToAnsi(s),'_','')
ShowMessage('Символов, не входящих в таблицу ANSI: '..n)
Скрипты для Demagog
Добавлено: 04 окт 2020 14:42
tonio_k
Я думал, существует некий диапозон(перечень) ANSI , задав который можно посимвольно прогнать текст c utf8 с проверкой нет ли символа НЕ входящего в диапозон ANSI. Если найденный символ не входит в диапозон ANSI - значит это символ относится к UTF8 о чем выходит сообщение что найден символ не входящий в диапозон
допустим в тексте книги присутствует символ ɐ о чем я не знаю и не узнаю, пока он не превратится в ? после s=WText(1) так вот мне хотелось бы получить предупреждение, что в книге есть символ который не является ANSI ДО того как я применю s=WText(1)
Скрипты для Demagog
Добавлено: 04 окт 2020 16:58
flegont
1) Для того, чтобы получить предупреждение, надо проверить текст по-байтно (в кодировке utf8) функцией Utf8ToAnsi. Если какая-то комбинация байтов соответствует символу, отсутствующему в ANSI, то он заменится на один или несколько символов _. Это и будет сигналом о присутствии в тексте символов, НЕ приводимых к ANSI.
2) А как получить текст в кодировке utf8 для вышеуказанной проверки? В следующей версии Демагога функция WText будет иметь 2 параметра. WText(i, utf8). 2-й параметр по умолчанию false.
Конечно, и сейчас можно сохранить текст в окне во временный файл в кодировке utf8 а потом прочесть в строку через LoadFromFile. И ее уже анализировать с помощью Utf8ToAnsi.
Скрипты для Demagog
Добавлено: 05 окт 2020 10:30
tonio_k
flegont писал(а): ↑04 окт 2020 14:27
a = LoadFromFile('proverka.txt')
s = table.concat(a,'\r')
_, n = string.gsub(Utf8ToAnsi(s),'_','')
ShowMessage('Символов, не входящих в таблицу ANSI: '..n
к небольшому куску текста работает хорошо, а вот если средняя по размеру книжка, то пауза - ощутимая (похожая на зависание)
tonio_k писал(а): ↑04 окт 2020 13:54
Это нужно для предварительной проверки текста перед s=WText (1) что бы точно знать, что никакой символ utf8 в знак "?" не превратится
Попробовал через "эмуляцию" воспроизведения ситуации, когда знаки вопроса появляются в тексте:
Код: Выделить всё
a = LoadFromFile('proverka.txt',false)
s = table.concat(a,'\r')
s = string.gsub(s,'\95', "")--удаляем все нижние подчеркивания (если они присутствовали в тексте)
s = string.gsub(s,'\63', "_")--заменяем все знаки вопроса(если они присутствовали в тексте)
SaveToFile({s},'result.txt') -- сохраняем результат
WOpen(-1,'result.txt') -- переоткрываем файл в окно Демагога
o = {}
o.File_Encoding = feANSI
Settings(o)
WSave(-1,'result.txt')--сохраним файл уже с ANSI кодировкой - при изменении кодировки все UTF8 символы заменятся на знак ?
WOpen(0,'result.txt')
WNew(-1)
WActive(0)
WNew(-1)
WActive(0)
s=WText(0)
--Ищем в файле с ANSI кодировкой знаки "?" которые появляются в результате того, что lua не распознает utf8 сиволы
_, n = string.gsub(s,'?','')
ShowMessage('Символов, не входящих в таблицу ANSI: '..n)
Работает намного быстрее, но Символов, не входящих в таблицу ANSI показывает не такое же как в вашем примере.
Подскажите, в чем причина? (файл для примера отправил вам на почту)
Скрипты для Demagog
Добавлено: 05 окт 2020 14:08
flegont
Потому что при s = WText(i) приведение текста к ansi-строке в Демагоге автоматически при присваивании ansi-строка = юникод-строка. При этом символы, не сводимые к ansi заменяются знаками вопроса.
А Utf8ToAnsi - это самоделка, написанная на Lua. Она для удобства, заменяет "нехорошие" символы знаком _ Но работает медленно - а чего мы ожидали от интерпретатора?
Скрипты для Demagog
Добавлено: 06 окт 2020 22:27
tonio_k
юрабойко писал(а): ↑02 окт 2020 12:39
Если возможно я бы вообще расставлял ударения в словах одним или несколькими нажатиями кнопок.
Сделал полезный скрипт для удобства вставки ударения в слово за счет изменения регистра буквы на заглавную:
файл из архива помещаем в папку \Demagog\_Tests_\
Вешаем скрипт на горячую клавишу:
Сервис-Статистика-Выполнить скрипт-По умолчанию; Выбираем удобное сочетание клавиш и прописываем путь к скрипту. Например: Shift+Ctrl+A | _Tests_\ВЫДЕЛЕННЫЙ ТЕКСТ ИЗМЕНИТЬ РЕГИСТР БУКВ.lua
Скрипт применяется к выделенному тексту. Двойной клик по слову - выделит целое слово. Максимально можно выделить текст размером в один абзац. Выделив текст, нажимаем Shift+Ctrl+A выходит окно:
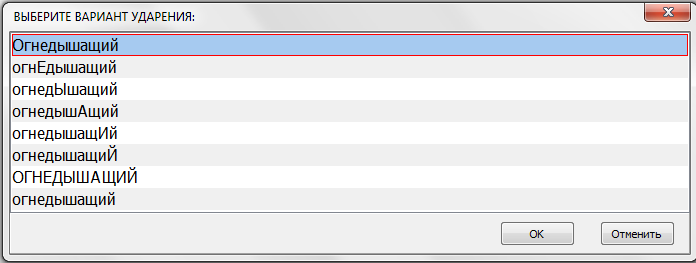
- 2020-10-06_22-17-52.png (22.99 КБ) 5553 просмотра
Выбираем нужный вариант и нажимаем Ok. Или двойной клик на выбранном.
Последние две строчки в списке всегда будут:
- ВСЕ БУКВЫ ЗАГЛАВНЫЕ
- все буквы строчные
Скрипты для Demagog
Добавлено: 07 окт 2020 16:01
юрабойко
Я думаю надо попробовать удвоить число всех пробелов в тексте (между словами) в два или три раза, если и тогда читать на скорости 0 балаболка будет плохо, заменю все пробелы на комбинацию 1 пробел и одна кома. Еще можно попробовать заменить пробелы на Табы, но если балаболка их не читает - последнее никак не поможет.
Скрипты для Demagog
Добавлено: 07 окт 2020 16:16
tonio_k
юрабойко писал(а): ↑07 окт 2020 16:01
если и тогда читать на скорости 0 балаболка будет плохо
а причем тут Балаболка? Это ветка связанная с программой Демагог в частности посвещена скриптам, которые работают только в связке с Демагогом.
юрабойко писал(а): ↑07 окт 2020 16:01
итать на скорости 0 балаболка будет плохо
что значит плохо? Сохраните аудио запись воспроизведения голоса выложите файл и и прокомментируйте что вас в аудиозаписи не устраивает?
Скрипты для Demagog
Добавлено: 07 окт 2020 16:18
юрабойко
Начало слов проглатывает и концы иногда тоже. Сейчас показать не могу - переставляю систему, а завтра без проблем кину ссылку.
Демагог к слову произносит лучше зато запись у него выходит еще хуже по качеству чем у балаболки - почти как у говорилки.
Я правда пока ни разу не делал общедоступным файл из гугл дриве, но думаю разберусь без инструкций, или на кину на my-files.su - там это вообще можно сделать в 4 клика мыши, не больше.
Хотя если запись файла Балаболкой будет говорить лучше чем сама программа этот будет приятным сюрпризом.
Скрипты для Demagog
Добавлено: 21 окт 2020 19:40
юрабойко
Говорилка может записывать аудиофайлы в 100 раз быстрее чем читает, а Демагог как?
Скрипты для Demagog
Добавлено: 21 окт 2020 20:02
tonio_k
юрабойко писал(а): ↑21 окт 2020 19:40
, а Демагог как?
попробуйте засечь время и отпишитесь. Было бы интересно узнать как дела обстоят на практике.
Из теории: и Демагог и Балаболка и Говорилка записывают в wav по времени одинаково. Скорость записи зависит от голосового движка, а не от Говорилки. На
ОБЩУЮ скорость подготовки книги влияет: время на обработку текста словарями + скорость записи голосового движка + скорость работы выбранного конвертора при конвертации wav в mp3. В сборке на базе Демагога книга получается быстрее только потому, что словари составлены и применяются по особому алгоритму - в результате на работу словарей уходит меньше времени (в разы). Во всём остальном скорость практически такая же как у других программ.
Скрипты для Demagog
Добавлено: 21 окт 2020 20:16
юрабойко
Демагог можно заставить записать wav файлы со скоростью 100 - но - качество, причина неясна.
С оригинальными настройками Демагог записывает файлы как минимум втрое медленнее.
Будет записанный с родными настройками лучше - проверю за 5 минут или раньше.
Скрипты для Demagog
Добавлено: 21 окт 2020 20:27
юрабойко
Часть теста завершена, речь в wav файлах лучше чем в mp3. Осталось проверить еще как минимум 2 формата файлов.
Звук у файла mp4 лучше чем у файла mp3.
Звук у файла Ogg у vorbis хуже чем у файла wav.
Звук у файла Custom encoder неотличим от звука файла mp3.
Все при стандартной скорости записи аудиофайла.
Скрипты для Demagog
Добавлено: 21 окт 2020 20:59
юрабойко
С тестами качества записанных аудифайлов разобрался полностью - ускоренная скорость записи ни одному них на пользу точно не пошла.
Качество записи в файл wav при стандартных мне точно самое высокое.
Итог - скорость записи менять может и нужно, но точно после записи при скорости в 100 выше стандартной придется как-то еще обрабатывать файлы, чтобы они не теряли в качестве.
Иначе файл строчит при запуске чуть ли не скороговоркой.
Скрипты для Demagog
Добавлено: 21 окт 2020 23:52
wasyaka
Вариант обработки омографов с помощью скрипта
От мастера угля - мастерам програмирования... 
Скрипты для Demagog
Добавлено: 22 окт 2020 15:59
Lecron
wasyaka писал(а): ↑21 окт 2020 23:52
Вариант обработки омографов с помощью скрипта
Как понял, составляется словарь. Только вопрос, на одну книгу или на будущее? Если первое, зачем редактировать правила до более общего вида? Если второе, словарь не совсем хороший. Альтернатив под другое ударение дофига. Например:
Код: Выделить всё
На крыльце дОма для рабочих.
ДорОгой тетушки неплохо провели время.
Обработанный дУхами скелет, пугал всех посетителей (из фэнтези).
за едУ служить не буду.
К тому же явно сЁстры.
Я узнаЮ везде, где появляюсь.
И так далее, почти для каждого правила, с большей или меньшей вероятность. Конечно это лучше чем ничего, но нужно быть очень аккуратным при составлении правил. И лишит большей части правил вообще.
Скрипты для Demagog
Добавлено: 22 окт 2020 16:33
tonio_k
Lecron писал(а): ↑22 окт 2020 15:59
с большей или меньшей вероятность.
как раз с вероятностями (определяется субъектвно) и приходится добавлять правила при составлении словарей. В "большинстве случаев", "в основном", "скорее всего", правило сработает верно. А если вылезет ошибка, надо будет только добавить другое более конкретное (с большим количеством слов) правило скорее к текущей книге, чем на будущее. Хотя есть мизерная вероятность, что другой автор в другой книге применит именно это словосочетание и правило сработает. Только об этом никак не узнаю, потому что вслух прочиталось верно, значит не надо к этому возвращаться. Хотя узнать можно - можно ввести статистику сработавших правил, копить, анализировать. Инструменты в скриптах для этого есть. Но это замедление общего процесса подготовки книги. И не факт что такая статистика будет полезной. Интересной - да. А вот практичность в плане обьема затрат по времени и ресурсам что бы потом удалить редкое правило которое никогда больше не сработает и выявив и удалив несколько десятков сотен таких правил на скорость работы словарей это практически не повлияет. Немного занесло под конец)))
Короче тут предполагают посмотреть принцип работы со скриптом. А сами правила и их ценность это как пример. Может эти правила сработают в самом начале обработки книги и дале будут неоднократно изменены более точными правилами из последующих словарей.
Скрипты для Demagog
Добавлено: 22 окт 2020 17:14
Lecron
tonio_k писал(а): ↑22 окт 2020 16:33
В "большинстве случаев", "в основном", "скорее всего", правило сработает верно.
В этом-то и принципиальная ошибка. Нам неизвестны вероятности! То что один из вариантов нам уже предложили в данной книге, заставляет восприятие крутится вокруг него, отчего он кажется более вероятным. Но предложи книга "... дОма для рабочих", "узнаЮ везде" или самое яркое "К тому же явно сЁстры", были бы в словарь записаны именно они.
Как пример работы со скриптом — отлично. Как смысл и результат работы в таком контексте на будущие книги....
Если у кого собрана большая библиотека, можете сами поискать эти словосочетания поиском и убедится в моей правоте. Или вашей)))
Скрипты для Demagog
Добавлено: 22 окт 2020 17:56
flegont
Вероятности - неизвестны.
Оценки вероятностей - известны, хотя они субъективны, зависят от общего объема прочитанного, и могут заметно различаться. Тем не менее, консенсус в большинстве случаев возможен. Я, например, уверен, что 99% здесь присутствующих правильно поставят ударение в последнем слове фразы:
Напряженная неделя заседаний закончилась, и депутаты Госдумы, наконец-то передохнут. 
А кто-то и соответствующее rex-правило найдет

Скрипты для Demagog
Добавлено: 22 окт 2020 18:46
good_cat
Так, вы тут заканчивайте филологические изыски
Скрипты для Demagog
Добавлено: 22 окт 2020 18:56
good_cat
flegont писал(а): ↑22 окт 2020 17:56
Оценки вероятностей - известны, хотя они субъективны, зависят от общего объема прочитанного, и могут заметно различаться.
Не только от объема, но и от жанра, от контекста. В современной литературе, если в начале предложения написано Модель, то скорее всего это модель. А вот, если это военная проза XX столетия, то вероятнее всего имеется в виду Модель. И подобные коллизии в принципе не разрешимы алгоритмическими путями.
Скрипты для Demagog
Добавлено: 22 окт 2020 19:22
flegont
Что ж... Подождем, пока спецы по нейросетям заинтересуются проблемой омонимии в русском языке.
Скрипты для Demagog
Добавлено: 22 окт 2020 21:39
wasyaka
Lecron писал(а): ↑22 окт 2020 15:59
Как понял, составляется словарь. Только вопрос, на одну книгу или на будущее?
Смысл на одну?
...И так далее, почти для каждого правила, с большей или меньшей вероятность.
Это просто пример как расставить омографы и
ДОБАВИТЬ одновременно в словарь
А что добавлять - это сугубо индувидуально.
В окне Демагога не очень удобно это делать (для меня, использую Emurasoft EmEditor Professional - добавил подсветку омографов - основные и все остальные - разным цветом).
► Показать
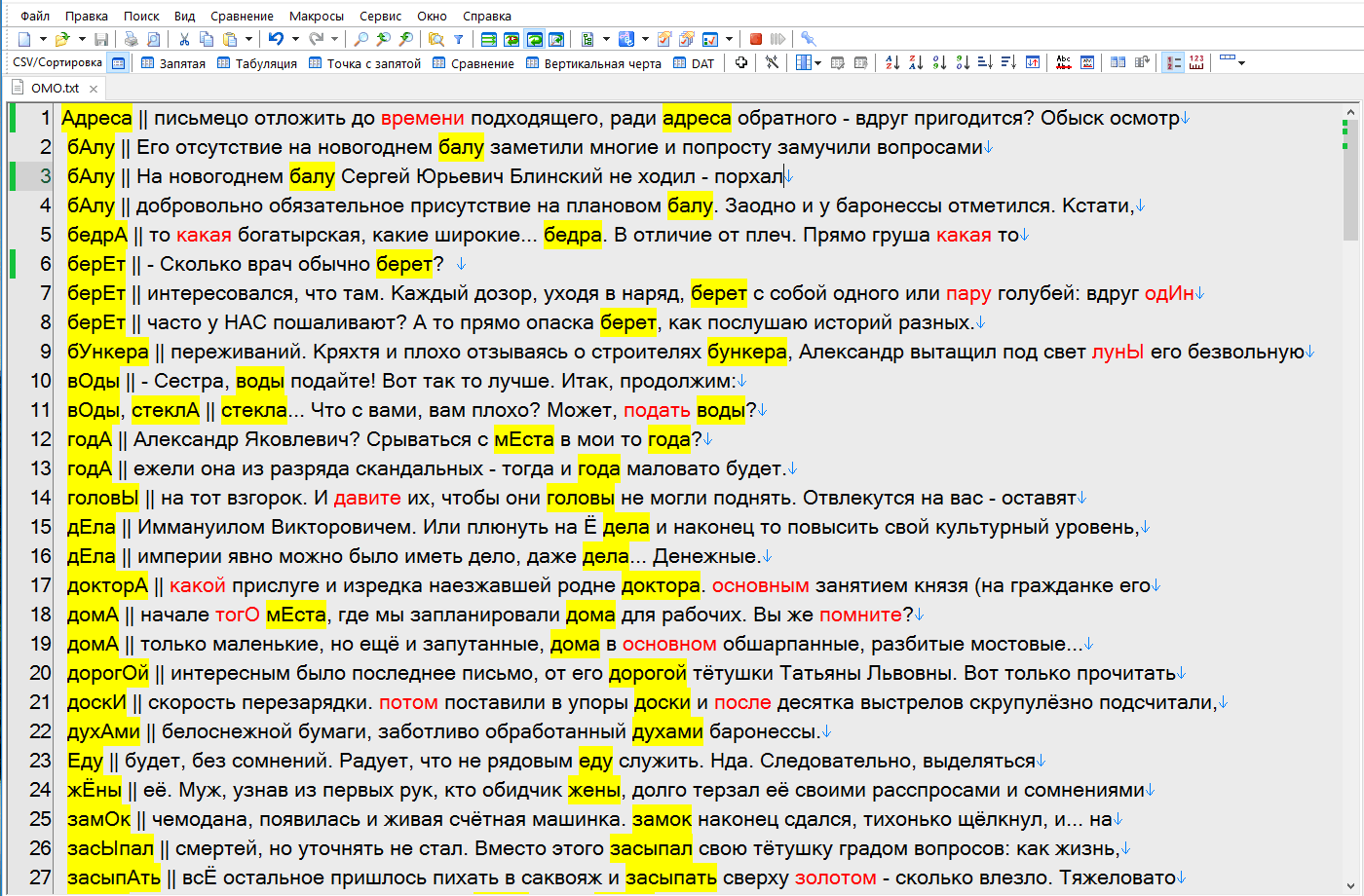
- 1.png (180.91 КБ) 4747 просмотров
Я все тексты подготавливаю и если со списком новых слов - всё добавляется, то с омографами не всё гут... Расставить не проблема, особенно с помощью
Homograph, а добавить в словарь - довольно трудо-нудно-время-ёмкое занятие. Вот и возникла идея, спасибо
tonio_k за скрипт
НЕОБРАБОТАННЫЕ ОМОГРАФЫ.lua. Некоторые омографы добавляю тут же в словарь рег выражений
Код: Выделить всё
@(\bкрейсера\b)\s{1,4}([А-ЯЁ]\w+)(\,|\sи)\s{1,4}([А-ЯЁ]\w+)=крейсерА $2$3 $4
@(\bна\b)\s{1,4}([А-ЯЁ]\w+)\s{1,4}(\bострова\b)=$1 $2 островА
некоторые, в том числе с ошбками в тексте - откидываю и потом ручками...
И
КОНВЕРТЕР требует допиливания, встречаются ньюансы...
.

Скрипты для Demagog
Добавлено: 23 окт 2020 00:43
tonio_k
flegont,
wasyaka писал(а): ↑22 окт 2020 21:39
В окне Демагога не очень удобно это делать (для меня, использую Emurasoft EmEditor Professional - добавил подсветку омографов - основные и все остальные - разным цветом).
может автор подумает над этим? Что бы не придумывать новые словари, может сделать "подсветку" на основе уже существующей поддержки словарей орфографии *.orfo? В настройках Литературный текст прописать либо/либо:
-подсветка ошибок
-подсветка слов из *.orfo
И при выборе второго варианта воспринимать словарь *.orfo как hmg, но с подсветкой, указанной в настройках.
Скрипты для Demagog
Добавлено: 23 окт 2020 10:20
flegont
1) В словаре *.orfo
нет слов. Это - совершенно отдельная, не совместимая с другими словарями система - набор n-грамм для русского языка, при n=5. Поэтому ее ни к чему, кроме проверки орфографии - не приспособишь.
2)
tonio_k писал(а): ↑23 окт 2020 00:43
В окне Демагога не очень удобно это делать
Я не понял, в чем именно состоит неудобство. Поясните.
Скрипты для Demagog
Добавлено: 23 окт 2020 10:28
tonio_k
flegont писал(а): ↑23 окт 2020 10:20
Я не понял, в чем именно состоит неудобство. Поясните.
это была цитата от
wasyaka - это ему неудобно
Скрипты для Demagog
Добавлено: 23 окт 2020 20:00
wasyaka
flegont писал(а): ↑23 окт 2020 10:20
Я не понял, в чем именно состоит неудобство. Поясните
Выделять для удаления лишнего надо с конца строки (или аккуратно) - а к этому надо привыкнуть - иначе нижняя строка присоединяется к текущей
► Показать

- 1.png (27.54 КБ) 4675 просмотров

- 2.png (29.18 КБ) 4675 просмотров
Отсутствие функций тхт редактора:
► Показать

- 5.png (49.96 КБ) 4675 просмотров
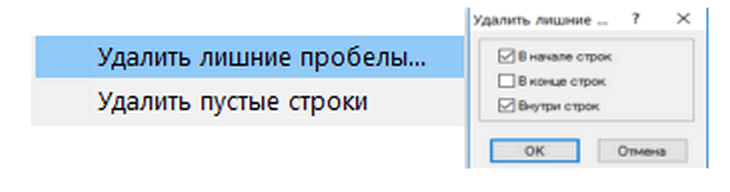
- 3.png (46.94 КБ) 4675 просмотров
Это из PSPad editor
Т.е всё равно надо к тхт редактору обращатся.